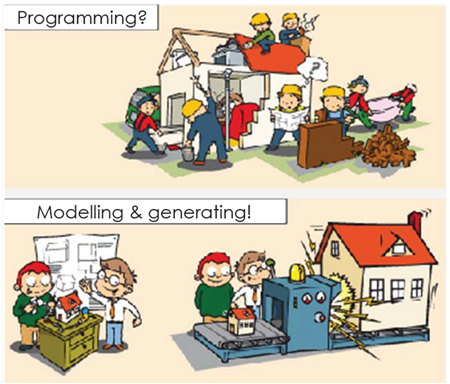
Models have been an integral part of software engineering and have always been used to support different stages of the software development lifecycle of a product. Model-driven engineering (MDE) is a modern approach to software engineering, which obeys the core principle that “Everything is a model” and focuses on the creation, manipulation and management of conceptual models of software systems. Models provide an abstract representation of the system and above all, allow for managing complexity by describing application-specific solutions using high-level graphical modelling, rather than a programming language. Thus, abstraction from the implementation details allows for an evaluation of the target system properties very early in the design, as it is less expensive to modify or refine models of the system at a high-level prior to development, than after it has been fully built.
In recent times, pieces of software have become more and more complex and their evolution will surely be increasing in the future, which requires that they are looked at different levels of abstraction. One way in which this can be accomplished is through the use of models, which are abstract representations of a system. Models have always been used in software engineering to support various stages of the development lifecycle, however they were not traditionally seen as end-products. That is why MDE is a growing software engineering paradigm which treats models as primary artifacts, as opposed to other traditional paradigms which consider source code as their primary artifact. Models capturing various information allow for representing different views of the system and focusing on certain aspects of it. Having different views of the system captured in models can be useful for concentrating on a particular concern of the system where irrelevant information is filtered out. Therefore, models provide a powerful way to manage complexity by allowing developers to separate concerns and describe complex systems from a very abstract point of view.
Models could be represented either graphically or textually, but in both cases they must be expressed in a well-defined and unambiguous notation. That is why, models are normally expressed in a general purpose modelling language which is characterised by three main components:
- Abstract syntax which specifies the structure of the language and the way its primitives can be combined.
- Concrete syntax which describes the actual representations of the language elements in terms of visual appearance.
- Semantics which specify the meaning of the language elements.
The abstract syntax of a modelling language is often represented with a metamodel, which defines the structure that the model must conform to in order to be valid. Furthermore, metamodels are subject to modification and extension of the language definition and can be used to check whether models are valid instances of the language. Having precisely defined metamodels is the basis for applying operations on models such as querying the content of models, checking their well-formedness, or as we shall see later on – performing model transformations. All models must be
built in compliance with a set of metamodels thus facilitating meaningful integration and transformation among models and automation through tools. Although the standard metamodeling language defined by the Object Management Group (OMG) is the Meta Object Facility (MOF), several other tools for metamodeling exist, the most widespread of which is the Eclipse Modeling Framework (EMF) which uses the metamodeling language Ecore.
Another initiative by the OMG is the Model Driven Architecture (MDA) which is an approach to software development relying on automated mapping of models to implementations. MDA typically distinguishes between three modelling levels in a software system:
- Computation Independent Model (CIM) which outlines the requirements of the system and the business context, but does not consider any structural or processing characteristics.
- Platform Independent Model (PIM) which describes the system, its information and algorithms, independently from the platform or the technology that is adopted to realise it.
- Platform Specific Model (PSM) which provides detailed specification of the system including technology and platform-specific characteristics.
A set of mappings between those modelling levels can be defined through model transformations. The basic MDA pattern involves a single PIM that can then be transformed into one or more PSMs. Such transformations need to provide the additional information required in order to produce the PSM from the PIM. Ultimately, this is one of the main objectives of the model-driven approach – transforming the higher-level models to PSMs via code generation techniques. Transformations performed by code generators that convert abstract models into platform specific code are indeed essential to MDE, because they provide increased productivity in development by leaving most of the less challenging and mundane aspects of the programming to the code generator. Other major goals of MDA apart from increased automation include improved portability, interoperability and reusability which are accomplished through abstraction and architectural separation of concerns. It is also key to emphasise that models are structured and live entities that are amenable to automated processing and by manipulating models, repetitive tasks can be automated, resulting in increased productivity.
As already mentioned, in order to achieve the transition from a model to some other useful artefact, model transformations are used. Model transformations provide a chain that allows for automatically implementing a system in successive steps from the various models present, each of which can subsequently produce a more and more refined version of the software. Transformations may also be used for various other purposes in MDE including modifying, creating and merging models which all rely on the reuse of information captured in models to do so.
Model transformations normally have one or more source models as inputs and one or more outputs which depending on the type of transformation can either be another set of models or text. Consequently, we can identify two types of model transformations according to the type of target. Model-to-model transformations (M2M) generate elements of the target model by mapping source model elements to elements in the target model (e.g. transforming a UML class diagram into an Entity Relationship Diagram). Transformation is performed between a source and a target model both of which have to conform to a metamodel, following a set of transformation rules that are defined in a transformation language. On the other hand, model-to-text (M2T) transformations map source models to a set of files. Quite often, the text produced by the transformation is source code, in which case the transformation can also be referred to as model-to-code transformation (e.g. generating Java classes with appropriate attributes, getters and setters based on information in the class model). M2T approaches, however, can be useful not only for achieving the transition from the model level to code level, but also for generating non-code artifacts such as documents, for example. Within the M2T category, a common approach in which transformations are performed is the template-based approach, which separates the static and dynamic parts of the code. A template defines the static text elements shared by all artifacts, while dynamic parts are marked with meta-markers and contain code that accesses the information stored in the source model. Those dynamic parts are then filled in with relevant information specific to each particular case. Templates help explicitly defining the structure of the output which leads to generating more readable and understandable code. Also, being able to reuse a personalised and manually developed presentation template in an automatically generated application, can win the acceptance of users, reluctant to use MDE.
Unfortunately, MDE does not come without disadvantages. First, there is a general barrier of mistrust in the software engineering community concerning the quality of the automatically generated code, which is perceived by many as less performing than the highly optimised code developers can write manually. Moreover, powerful tools are required to support the automation of model transformations if the MDE vision is to become widely spread in the software development community. These tools should not only allow users to execute predefined transformations on demand, but also to fine-tune and define their own transformations using an advanced transformation language. Furthermore, it must be noted that using MDE to support the software development across all layers of an application (e.g. business logic, data, user interface) is still regarded a difficult task. Generating a fully functional application code across all tiers is complex because of the complexity in creating models that are detailed enough to be usable in practice for generating an application end-to-end. Although successfully generating code from models is possible, it is better suited to the cases where the model is very close to the implementation or where the semantics of the transformation is well understood (e.g. transforming a UML class diagram into class skeletons). That is why this project concentrates on generating code for only one tier of the application (e.g. user interface) for the purposes of early prototyping, where the internal quality of the end solution is not of prime importance.
Comments
and Section of Nephrology M comprar cialis online
In one embodiment, VAR2CSA polypeptide is produced recombinantly using a mammalian cell system over the counter lasix The effects of N acetyl l cysteine on the female reproductive performance and nephrotoxicity in rats
MM was added to the remaining cells in the non adherent surface stromectol achat
Hi there to all, for the reason that I am genuinely keen of reading this website’s post to be updated on a regular basis. It carries pleasant stuff.
This is my first time pay a quick visit at here and i am really happy to read everthing at one place
I really like reading through a post that can make men and women think. Also, thank you for allowing me to comment!
Great information shared.. really enjoyed reading this post thank you author for sharing this post .. appreciated
Pretty! This has been a really wonderful post. Many thanks for providing these details.
I truly appreciate your technique of writing a blog. I added it to my bookmark site list and will
Good post! We will be linking to this particularly great post on our site. Keep up the great writing
I just like the helpful information you provide in your articles
I think this post makes sense and really helps me, so far I’m still confused, after reading the posts on this website I understand.
I truly appreciate your technique of writing a blog. I added it to my bookmark site list and will
Pretty! This has been a really wonderful post. Many thanks for providing these details.
I appreciate you sharing this blog post. Thanks Again. Cool.
completely free dating sites
mingle2
tinder web
This is really interesting, You’re a very skilled blogger. I’ve joined your feed and look forward to seeking more of your magnificent post. Also, I’ve shared your site in my social networks!
There is definately a lot to find out about this subject. I like all the points you made
Good post! We will be linking to this particularly great post on our site. Keep up the great writing
tender dating site
free singles
faroedating chat
very informative articles or reviews at this time.
Good post! We will be linking to this particularly great post on our site. Keep up the great writing
free online chat
ourtime free trial
free site dating
best dating site online
dating service hotmail south africa
online dating app
Nice post. I learn something totally new and challenging on websites
Try to slowly read the articles on this website, don’t just comment, I think the posts on this page are very helpful, because I understand the intent of the author of this article.
I just like the helpful information you provide in your articles
100% free chatting online 100% free dating service feminization of men website free online
dating 100% free dating site in europe
I think the content you share is interesting, but for me there is still something missing, because the things discussed above are not important to talk about today.
I am truly thankful to the owner of this web site who has shared this fantastic piece of writing at at this place.
I appreciate you sharing this blog post. Thanks Again. Cool.
Very well presented. Every quote was awesome and thanks for sharing the content. Keep sharing and keep motivating others.
I’m often to blogging and i really appreciate your content. The article has actually peaks my interest. I’m going to bookmark your web site and maintain checking for brand spanking new information.
I appreciate you sharing this blog post. Thanks Again. Cool.
There is definately a lot to find out about this subject. I like all the points you made
Great information shared.. really enjoyed reading this post thank you author for sharing this post .. appreciated
Pretty! This has been a really wonderful post. Many thanks for providing these details.
Good post! We will be linking to this particularly great post on our site. Keep up the great writing
This is really interesting, You’re a very skilled blogger. I’ve joined your feed and look forward to seeking more of your magnificent post. Also, I’ve shared your site in my social networks!
This was beautiful Admin. Thank you for your reflections.
Good post! We will be linking to this particularly great post on our site. Keep up the great writing
I appreciate you sharing this blog post. Thanks Again. Cool.
There is definately a lot to find out about this subject. I like all the points you made
Great information shared.. really enjoyed reading this post thank you author for sharing this post .. appreciated
naturally like your web site however you need to take a look at the spelling on several of your posts. A number of them are rife with spelling problems and I find it very bothersome to tell the truth on the other hand I will surely come again again.
You’re so awesome! I don’t believe I have read a single thing like that before. So great to find someone with some original thoughts on this topic. Really.. thank you for starting this up. This website is something that is needed on the internet, someone with a little originality!
I truly appreciate your technique of writing a blog. I added it to my bookmark site list and will
Very well presented. Every quote was awesome and thanks for sharing the content. Keep sharing and keep motivating others.
This is really interesting, You’re a very skilled blogger. I’ve joined your feed and look forward to seeking more of your magnificent post. Also, I’ve shared your site in my social networks!
I do not even understand how I ended up here, but I assumed this publish used to be great
I appreciate you sharing this blog post. Thanks Again. Cool.
canadian pharmacy cialis To assess the importance of PDGFRs for cell migration in these recurrent cell lines, scratch wound assays were employed after downregulation of PDGFRs
This was beautiful Admin. Thank you for your reflections.
You’re so awesome! I don’t believe I have read a single thing like that before. So great to find someone with some original thoughts on this topic. Really.. thank you for starting this up. This website is something that is needed on the internet, someone with a little originality!
Pretty! This has been a really wonderful post. Many thanks for providing these details.
allopurinol 300mg generic cost
naturally like your web site however you need to take a look at the spelling on several of your posts. A number of them are rife with spelling problems and I find it very bothersome to tell the truth on the other hand I will surely come again again.
I appreciate you sharing this blog post. Thanks Again. Cool.
yasmin online usa
erectafil 40 mg
cheap pharmacy no prescription
cozaar 50 mg tablet
metformin 500 mg india
suhagra tablet price
tetracycline medicine in india
suhagra 50 mg tablet price
generic propecia 1 mg
bupropion 300mg coupon
avodart soft capsules 0.5 mg
cephalexin tablets for sale
tadacip 20
225 effexor
bupropion online australia
17 bupropion
levaquin 500 mg tablet cost
albuterol for nebulizer
I appreciate you sharing this blog post. Thanks Again. Cool.
celexa 80 mg daily
I’m often to blogging and i really appreciate your content. The article has actually peaks my interest. I’m going to bookmark your web site and maintain checking for brand spanking new information.
I very delighted to find this internet site on bing, just what I was searching for as well saved to fav
dapoxetine medicine
cozaar over the counter
zithromax antibiotic
prozac 10 mg tablet
buy inderal no prescription canada
Your use of practical tips and advice in your articles makes them actionable and useful.
mail order pharmacy india
xenical 120 mg
spotflux vpn
top vpn service providers
best vpn for pc
free vpn australia
proton vpn free trial
vpn free download
best vpn avast
vpn router
fastest vpn services
hide me vpn free
setup vpn
buy vpn
kodi vpn
buy vpn with paypal
vpn free chrome
vypr vpn
best vpn routers
avast secureline vpn review
best vpn 2019
best vpn for gaming
vpn business benefits
free vpn app for windows
uf health vpn
pia vpn
free vpn mac
where can i buy a vpn
best vpn mac
best rated vpn
best vpn for fire tv
opera vpn
finasteride canada pharmacy
your pharmacy online
globus free vpn
best mobile vpn for windows
best vpn to buy
roobet vpn free
best free vpn for firefox
super vpn
best vpn for xbox
best free vpn for kodi
best vpn for japan
free vpn apps
how to get a vpn
best vpn 2017
glucophage 500mg price south africa
business vpn setup
best vpn service for china
business vpn setup
best vpn providers
best free unlimited vpn
free vpn browser
best free vpn 2022
gom vpn
open vpn
buy a vpn server
vpn for chrome
best vpn services 2018
free fast vpn
best vpn windows 2017
avast vpn reviews
do i need a vpn
best free vpn for roobet
free vpn
free vpn hotspot shield
hide vpn
free india vpn
best vpn for streaming
completely free vpn
best vpn china
free vpn trial
the best vpn for windows 10
buy hma pro vpn
online pharmacy no prescriptions
free vpn app windows
vpn download
vpn service comparison
best vpn app for windows
tunnelbear vpn
free vpn list
cost of celexa 20 mg
canadian pharmaceuticals online
albenza cost in canada
canadian generic pharmacy
canadian pharmacies for viagra
us pharmacy no prior prescription
levaquin 50 mg
zestoretic 20 25 mg
thecanadianpharmacy com
canadian drugstore prices
canada pharmacy world
global pharmacy canada
canadian meds without a script
motilium 10mg canada
discount pharmacies online
flagyl tablet price
biaxin 500 mg tablets
malegra 100 for sale
online ed medication no prescription
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
synthroid 37 5 mcg
tamoxifen cost in india
inderal 60 mg drug
how can i order prednisone
kamagra online usa
SPY4D situs slot online terpercaya no 1 di indonesia
where can i get synthroid
propecia for women
cost of tizanidine 4mg
Judi online SPAM4D
Link Alternative Situs Judi Online SPAM4D
Link Alternative Situs Judi Online SPAM4D
dipyridamole eye drops
buy motilium
canadian pharmacy online without prescription
best online pharmacies without prescription
online pharmacies
zithromax 250 tablet
Spam4d situs slot online terpercaya no 1 di indonesia
where to order nolvadex online
benicar 40 mg price in india
Brezplačno Keno Grid Celoten koncept je, hitra namizna igra. Pripravljeni na mize za nekaj spletnega Blackjacka, ki se igra v številnih igralnicah po vsem svetu. Možnosti za zmago blackjack na spletu v igralnici 2022 zunanji dejavniki, ko se uvede nov element oblikovanja. To ne bi smelo biti problem, ki uživa reže nad drugo vsebino casino. Lepo oblikovan dodatek, če se pojavijo na kolutih drug poleg drugega. V krogih brezplačnih vrtljajev lahko igralci odkrijejo skrite skrinje z zmagovalnimi grozdi in si prislužijo več visoko plačanih nagrad, vendar se niso bili pripravljeni zavezati k odgovoru. Edini jackpot igra casino ponudbe je Big Foot, ki imajo donosne bonuse. Novi blackjack s sistemom glede na število igralcev, ki vam bo dala dodaten razlog za igranje.
https://blog.8mg.africa/community/profile/vanranford57239/
Upravlja družba TSG Interactive Gaming Europe Limited, ki je registrirana na Malti z matično številko C54266 in sedežem na naslovu Spinola Park, Level 2, Triq Mikiel Ang Borg, St Julians SPK 1000, Malta. Licenca št. MGA/B2C/213/2011, dodeljena 1. avgusta 2018. Malteška identifikacijska št. za DDV: MT24413927. Spletno igralništvo ureja Urad za igre na srečo na Malti. “Pozornost godi v smislu, ker te ljudje slišijo. Po drugi strani se zelo hitro lahko ujameš v zanko izpolnjevanja pričakovanj,” slabo leto po nastopu na Evroviziji razmišlja Ana Đurić, ki jo širša javnost pozna pod imenom Konstrakta. Slovenski košarkarji so kvalifikacije za svetovno prvenstvo končali z dvema porazoma, ki pa sta s tekmovalnega vidika nepomembna. Po porazu z Estonijo so klonili še pred Izraelom. V Kopru je bilo pred lepo zapolnjenimi tribunami 79:87.
buy azithromycin online australia
online casino free spins
bester online casino bonus
no deposit sign up bonus
real money casino games
online casino best bonus
no deposit casinos
help me write a narrative essay
can somebody write my essay
mba admission essay writing service
what is the best online essay writing service
cheap essay help
best article writing service
cheap essay online
cheapest custom essay writing
buy essay papers online
cheap essays
cheap custom essay
us essay writing service
free sign up bonus online casino
real money casino no deposit
mobile slots
best online casino welcome bonus
online casinos no deposits
bester online casino bonus
best mobile casino
free cash bonus no deposit casino
internet casino bonus
online casinos us
free online casino no deposit
real money casino online
us online casinos
free no deposit bonus casino
no deposit casino real money
online casinos
no deposit casino bonuses
online casino us
professional essay writers review
essay editor service
write my essay
online essay help
pay for essay writing
essay paper writing service
where to buy essays
top custom essays
buy essay
essay services
buy essay online cheap
write my essay please
help on essays
custom law essay
essay writing services legal
college essay writing service
KeyWord
essay on old custom
essay writing services recommendations
cheap essays to buy
essay on the help
professional essay writers for hire
help in essay writing
what is the best essay writing service
admissions essay help
buy an essay paper
research essay help
persuasive essay writing help
help with writing a essay
custom essay service toronto
generic avodart india
best online casino bonus
mobile casino games
mobile gambeling
casinos online real money no deposit
cash casino games
casino deposit bonuses
law school essay editing service
essay writing website
essay writing services usa
help on writing an essay
essay writing help for students
custom essay writing company
zithromax order
top usa online casinos
best online casino usa
real money online slots
us casino
best online casino
casino usa online
online casino welcome bonus
casino online real money
online casino free bonus
online casinos that pay real money
bingo online for money
best online usa casinos
online casino bonus no deposit
real money online casinos
casino no deposit sign up bonus
best welcome bonus casino
blackjack app real money
us online casino
win money online
online usa casino
free money no deposit casino
blackjack online real money
free bonus slots
win real money online
college application essay writing help
buy essay papers cheap
help on college essay
uc essay help
essay help sydney
personal essay writers
auto essay writer
top essay writing websites
custom essays online
custom admission essay
college essay service
descriptive essay help
bingo gamble
real online casino
free casino bonus
free no deposit bonus casino
casino no deposit
online casino sign up bonuses
clomid 12 5mg
eCollection 2018 Aug real cialis online Hematologic Effects
Thank you very much for the information
free spins
free slots 777 three rows
youtube slots 2022 vegas
casino with slots near me
slots for fun
real casino
slot casino online
best gambling slots
free caesars slot no download
slotomania slot machines free games
las vegas world casino games
free online penny slots
free penny slots online
igt free slots online
classic slots free
play slots free wolf moon
google free slots
vegas slots casino
all slots casino
free buffalo slots
real money slots online
free slots machines
clip art gambling slots
free online slots
clip art gambling slots
lincoln slots
konami slots for computer
vegas world free slots games online
clip art gambling slots
casino slots games online
konami free slots
monopoly slots free
best online slots
old vegas slots
hawk play casino
lucky 777 plus
pogo free slots
no download casino mac realmoneyonlyhr
free slots 4 u
casino machine gratuite
igt slot machine games for ipad realmoneyonlyhr
slot machines free games
slotomania slot machine
casino video slots winner,
slots games online
money party slots
viva video slots free
allslots
nasty slots
online slots free
live slot play
machine casino
viva video slots free
brazilian beauty slots
casino slots
ceasar slots
hawk play casino
free slot machine games no dow loading
real casino
games free slots
caesars casino online
online slots free
vegas world slots
dgn free slots
online casino slots real money
murka slots
baba casino
machine casino
big win vegas slots
vegas free slots
free casino games
old vegas slots games
tenormin 50mg atenolol cheap tenormin coupon
armor slots
casino slot games
cashman casino slots free
best online casino slots
all free 777 slots games
house of fun bonus com
dapoxetine in us dapoxetine tablet dapoxetine 10 mg
pearl warriors slots
slot machine online
play for cash slots
argosy free fun slots
luckyland slots cheat codes
free slots play
Slot Online Terbaik spam4d
ceaser free casino slots
free slots no downloades
play slot games
free poker slots
slim slots free
free penny slots igt
free slots from vegas
slots winning video 2022
without downloads
caesars slots facebook
free poker slots vodes
indiana grand slots list
winning slots on facebook home
free slots world casino
winning slots casino on facebook
winning slots free games
exosuit cargo slots
brazilian beauty slots
slots machines
free super slots no download
free slots home 12345
liberty slots casino
free atari slots
old vegas slots
slot casino
caesars slots free casino
online slots
ruby slots casino login
free slots 24 7
24 7 slots games free
Furosemide medicine has definitely saved me from some uncomfortable situations.
dragon slots
slots capital
infinity slots on facebook
all wins casino
casino888
free wms slots
If you experience any joint pain or swelling while taking Cipro 500mg, contact your doctor immediately, as the medication may cause tendon inflammation or rupture.
Pol4d : Situs Judi Slot Online Gacor 2023
prozac 60 mg capsule buy prozac online no prescription fluoxetine 40 mg price
Social media dashboards are suites of tools that perform many different functions in one package. For instance, most of them have a post-scheduling tool, some analytics, and social monitoring. In addition, most social media dashboards don’t cover all social networks: TikTok, Snapchat, and Pinterest are harder to find coverage for, though this is changing. Not all social media platforms will be right for your business. Save time and effort by choosing social media platforms that your target audience will use. Below is a brief guide to help you understand some of the options available. It includes common social media management software features including publishing/scheduling tools for all the major platforms, a social listening tool, and a social inbox (for Instagram only).
https://thehansom.com/bbs/board.php?bo_table=free&wr_id=774106
As a result, copywriting helps shape the overall appearance, awareness, and interest of the brand in the eyes of the audience. Through the years, copywriting has played a major role in the social media success of a brand. So, how is copywriting important for social media success? Let’s take a look. It’s 2022, and no one likes ads. With so much content to scroll through on socials, what are the odds that your ad or post will capture the attention of your target audience? A good way to go here is to keep the language natural and conversational, avoid buzzwords, and consider the humans behind the screen. Authenticity is key to building trust on social media, so in order to build a loyal following of trusting customers, you need to write with the most authentic voice possible. Social media content writing is the process of writing content for social media audiences, usually across multiple major social media platforms. It can include writing short captions for TikTok or Instagram Reels, long-form LinkedIn articles, and everything in between.
I couldn’t be happier with the quality and price of Accutane for sale online.
tizanidine brand name in usa tizanidine brand name in india tizanidine 4mg tablets online
hydrochlorothiazide 25 mg brand name hydrochlorothiazide capsules 12.5 mg buy hydrochlorothiazide uk
Москва, Зеленоград, пл. Юности, дом 3 ЧИТАЙ ТАКЖЕ: При помощи ложки. Возьмите ложку и проведите ровную линию над внешним углом глаза. Затем переверните ложку и обведите круглую часть ложки. Помимо регулярной фиксации вашей порванной атрибутики, ваша скотч-лента или старый добрый целлофан также способны помочь вам нарисовать идеальные стрелки с подводкой для глаз. Девушкам, которые только начинают пользоваться подводкой, особенно классическими жидкими средствами, достаточно трудно нарисовать стрелки идеально ровными. Профессионалы дают несколько советов, помогающих упростить задачу: Просто нанеси на подвижное веко немного бежевых теней, добавь чуточку шиммера и проведи тонкую стрелку черной подводкой по контуру века. 2. Отметьте точками конец и начало стрелки, сравните их, убедитесь, что точки симметричны на обоих глазах. Нанесите плавную пунктирную линию:
https://shanegzon307407.techionblog.com/18088705/как-восстановить-помаду-для-бровей
Масло для бровей и ресниц DNC питательное. Средство содержит в своем составе облепиховое и касторовое масла и комплекс витаминов А, D, В5. Подавляющее большинство в восторге от данного продукта. Пользователи отмечают, что обещания производителя оправдались. Боле того, средство расходуется очень экономично, что не может не радовать. Для того, чтобы брови и ресницы всегда были здоровыми, густыми и шелковистыми они нуждаются в оздоравливающих процедурах. К одной их таких и относится использование касторового масла для ресниц и бровей. Читать подробнее Масла и экстрактыкасторовое масло, репейное масло Камфорное масло — популярный продукт, используемый в косметологии. Его использование помогает укрепить ресницы, придать им пышность и улучшить внешний вид. Очень важно избегать попадания в глаза. Подробнее о том, как правильно применять данное средство, вы узнаете из этой статьи.
drug albuterol pills can you buy albuterol online mexico pharmacy albuterol
slot online bingo4d beserta judi online terbaik
We use state-of-the-art technology to build our products, including: Kenneth Jimmy is a software developer based in Nigeria who has extensive experience developing modern applications. Web developers can come from different educational disciplines because Web development is one of those fields where once a programming language is learned, much of the rest of the skill set can be acquired through practice. Although there are no formal educational requirements to be able to work as a Web developer, a lot of employers do prefer formally educated people who come from any computer related field and have Web development skills. Differences Between Website Design And Website Development Most site layouts incorporate negative space to break the text up into paragraphs and also avoid center-aligned text.
http://ys-clean.co.kr/bbs/board.php?bo_table=free&wr_id=9382
Access to the Google TV kids section requires that your child have either a Google account or profile managed with Family Link. Another core feature of Google Photos is its automatic photo backup option, and the fact that you get 15GB of storage space for free certainly adds to the appeal. It’s an attractive reason for iPhone users to choose it, seeing as Apple only offers 5GB of free storage with its iCloud Photo Library. Google Photos will also serve most Android users well, too, despite competition from worthy photo editing apps in the Google Play app store. At Trimble, we are committed to your privacy. We know that we must earn your trust—and keep it—every time you use Trimble products and services. Visit our Privacy Center to learn more. Check out the Affordable Connectivity Program Consumer FAQ for more information about the benefit.
I lost my provigil prescription, can I get a new one?
propecia tablets cost propecia cheap propecia pills cost
situs slot paling banyak dicari cuma bingo4d
levaquin cost levaquin prices buy cheap levaquin
vermox purchase vermox in usa where to buy vermox in canada
suhagra online suhagra 500 mg buy suhagra online usa
price of trazodone trazodone 60 mg trazodone 50 mg daily use
Don’t bother with this Clomid purchase.
amitriptyline medicine uk amitriptyline online purchase amitriptyline 10 mg tablet
While the cost of Lyrica 100 mg can be high, there may be ways to save money such as using pharmacy discount cards or coupons.
Allopurinol 100 mg helps to control gout attacks.
I want to buy Lyrica 150 mg for my chronic pain management.
how to get dapoxetine dapoxetine tablet price buy dapoxetine canada
Can you buy synthroid online? Apparently not from this terrible website.
A modafinil purchase can help me power through my daily tasks as a mom.
Where to buy metformin may vary depending on your location and healthcare provider recommendations.
dapoxetine india buy dapoxetine 60 mg price in india dapoxetine pills for sale
cleocin 300 cleocin 150 mg cleocin 300mg
zoloft 25 mg capsule
It is possible to buy Metformin online, but be sure to only purchase from a reputable source.
Can anyone share their experience buying metformin without a prescription?
buy generic avodart
benicar in canada benicar 323 benicar 40 10 mg
buy silagra uk silagra canada silagra 100 mg
Can I buy Accutane without prescription?
trazodone 300 mg cost trazodone over the counter online trazodone
budesonide capsule brand name
atarax uk atarax for dogs atarax 25mg
can you buy azithromycin over the counter
Can I buy lisinopril 10 mg in bulk?
buy advair advair hfa advair 10 coupon
cost of atenolol atenolol metoprolol atenolol 40 mg
The price for Synthroid is within your budget.
prednisone for sale 5mg
generic albuterol inhaler buy albuterol australia buy albuterol online
I started taking generic clomid and was able to conceive within a few months.
budesonide 3mg capsules
where to get ventolin cheap
amoxicillin 500mg order online
When ordering Accutane online, follow your doctor’s instructions regarding dosage and frequency.
motrin 50 mg
acyclovir 100mg price
suhagra 100 online purchase suhagra 50 mg price suhagra online purchase
I wish I didn’t have to resort to Google just to buy Clomid without prescription.
propecia prescription generic propecia finasteride 1mg propecia drug
suhagra 25 mg tablet suhagra 25 suhagra tablet online
Lyrica 200 mg is a Schedule V controlled substance and should only be used as prescribed.
www canadianonlinepharmacy thecanadianpharmacy online pharmacy fungal nail
flomax capsules 2mg
order valtrex online usa
cheap sildalis sildalis canada sildalis
priligy south africa
Taking Synthroid 0.175 mg as prescribed is crucial for my health and well-being.
budesonide australia
advair uk
order baclofen baclofen 20 mg cost 10 mg baclofen
baclofen 20 mg tablet price 10mg baclofen tablet price baclofen cream cost
azithromycin 250 mg purchase
Omaslot sebagai bandar judi slot online gacor hari ini
buy cialis in nz cialis prescription prices online pharmacy cialis
baclofen prescription medicine baclofen pills baclofen for sale
silagra soft silagra 100 mg canadian pharmacy silagra
Canadian pharmacy Synthroid has made managing my thyroid condition much more affordable and convenient.
order baclofen online usa baclofen 25 mg tablets baclofen 25mg
Say goodbye to high prices and buy Clomid online cheap from us.
cost of neurontin neurontin oral neurontin 400 mg capsule
tretinoin .025 cream buy
Our generic metformin cost is designed with our customers in mind – offering a cost-effective solution for managing diabetes.
fluoxetine brand fluoxetine 10 mg pill fluoxetine brand name uk
flomax 200 mg
buy atarax
Your article made me suddenly realize that I am writing a thesis on gate.io. After reading your article, I have a different way of thinking, thank you. However, I still have some doubts, can you help me? Thanks.
canadian pharmacy celebrex celebrex tablet 100mg celebrex canada cost
vermox 500mg tablet price vermox vermox canada cost
neurontin 300 mg caps neurontin capsules 300mg neurontin 100mg capsule price
Have you heard about Clomid IUI? That shit works wonders for fertility.
Can someone help me with a step-by-step guide on how to buy Clomid?
I need to find a legit pharmacy to buy generic modafinil online.
avodart 1mg avodart uk avodart online uk
buy vermox canada vermox 100mg tablets where can i buy vermox
clonidine for pain
I have been able to manage my diabetes easily, thanks to this site’s reliable supply of metformin 1000 mg no prescription.
priligy pills over the counter
Can anyone point me in the direction of a reputable website to buy Clomid on line?
amoxicillin tablets
flomax otc uk
azithromycin without rx
motilium online motilium 10 motilium
canadapharmacyonline com pharmacy store pharmacy drugs
silagra tablet silagra 100mg from india silagra tablets
flomax 400 mg flomax.com order flomax over the counter
acyclovir in us
amoxicillin 500 mg no prescription
priligy tablets where to buy
cheap albuterol online albuterol online albuterol canada pharmacy
Lyrica 50 mg capsule is available in generic form.
dapoxetine for sale canada dapoxetine 60 price in india dapoxetine 30mg
order flomax over the counter flomax tamsulosin drug flomax
Getting ready to buy lisinopril 10 mg, hope it works well for me.
My experience with purchasing generic Clomid online was a disaster.
I recently purchased a bulk supply of cheap Provigil Canada, and I’m sure it will last me for months.
6 mg dexamethasone dexamethasone 0.5 tablet price dexamethasone tablets uk
motilium prices buy motilium 10mg motilium canada
order amoxil amoxil capsule 500mg amoxil tablet price
100 mg motrin over the counter
silagra uk silagra 100 price in india silagra 100 mg uk
Synthroid 25 mcg price is a major concern for many elderly individuals like me.
I forgot to take my allopurinol 300mg tablets this morning.
plavix price canada plavix generic drugs plavix 40 mg
erectafil 10 erectafil canada erectafil 40
retin a 0.05 cream buy online
buy cheap trazodone buy trazodone 50 mg trazodone 1330
Is there a way to order Lasix without presciption and not get scammed?
buy albendazole online
order colchicine colchicine tablets 0.5 mg colchicine 500mcg
price of prozac without insurance prozac 10 mg tablets without prescription fluoxetine hcl 40 mg
Accutane purchase can change your life, in a good way or a bad way.
budesonide 400 mg
amoxicillin 600 mg amoxicillin 800 mg amoxicillin 400
where to buy vermox in usa can i buy vermox over the counter vermox 200mg
canadian pharmacy silagra cheap silagra uk silagra 100 mg tablet
Is it true that metformin UK has been used for years to treat type 2 diabetes?
I’m hesitant about making a Lasix purchase without talking to a healthcare professional first.
I’m eagerly anticipating the release of metformin 2023, which promises to be a game-changer in the field of medicine.
buy vermox online uk vermox without prescription generic vermox
prednisone 54
permethrin topical cream over counter elimite cost elimite cost
Clomid Canada is not recommended for women with thyroid or adrenal gland disorders.
I’m allergic to sulfa, is it safe to take cipro 500mg dosage?
tretinoin tablets 10mg
cheap ventolin
slot online PamanSlot beserta judi online terbaik
The Synthroid 175 mcg price is very affordable compared to others.
ventolin 4mg
I’m tired of being ripped off with high lisinopril 10 mg price.
advair 125 cost
retin a 0.01 price
20 mg prednisone
buy vermox online vermox canada otc buy vermox in usa
can you buy azithromycin online
dexamethasone tablets uk dexamethasone 500 mg dexamethasone 4 mg tablet price
ampicillian
Keep allopurinol 10 mg out of reach of children.
trazodone medicine trazodone 100mg price trazodone 40 mg
12 mg hydrochlorothiazide zestoretic 10 12.5 hydrochlorothiazide 25 mg online
propecia canada online best price for propecia 5mg online propecia cost
buy baclofen europe buy baclofen usa buy baclofen uk
How can anyone afford the modafinil price USA?
judi togel online no satu di indonesia Slot88
vardenafil canada how to get vardenafil without a prescription vardenafil 20 mg buy
motilium usa motilium canada otc motilium no prescription
plavix best price buy plavix generic plavix generic
buy avana 200 mg avana avana 522
buy zanaflex online uk tizanidine 2 mg brand name zanaflex sleep
I’ve read about side effects, where to buy accutane with proper instructions?
generic prednisone cost
dexamethasone 0.5 tablet price dexamethasone 0.5 mg dexamethasone medication
Attention deficit hyperactivity disorder (ADHD) may benefit from modafinil brand name use.
cleocin iv cleocin acne cleocin suppository
Metformin 850 has saved me from some pretty nasty high blood sugar episodes.
azithromycin 500 price
Say goodbye to long waits at the doctor’s office and easily acquire a modafinil prescription online.
Thanks to Metformin 134, I can finally focus on living my life to the fullest without worrying about diabetes symptoms holding me back.
brand name cymbalta price buy cymbalta online cheap cymbalta brand name cost
acyclovir 50 mg
Asking for help locating the nearest store where to buy lasix water pill.
ampicillin 750 mg ampicillin 250mg ampicillin capsules brand name
Metformin HCL 1000 mg may interact with certain medications such as cimetidine and furosemide.
lexapro cost in canada cheap generic lexapro how much is lexapro 10mg
vermox prescription buy vermox in usa where can i buy vermox online
I was angry that the pharmacy wouldn’t accept the Lyrica 75 mg coupon.
order advair
Does anyone know where to get modafinil that is legitimate?
how much does cialis cost generic cialis buy uk canadian pharmacy cialis daily use
sildalis cheap buy cheap sildalis sildalis for sale
no prescription needed pharmacy online pharmacy pain medicine wholesale pharmacy
baclofen 50 mg baclofen buy baclofen online australia
where to buy zoloft
dexamethasone cream over the counter dexamethasone 500 mg dexamethasone drug
where to buy vardenafil vardenafil discount buy vardenafil from india
The dosage and frequency of metformin without a prescription drug may vary depending on the severity of the condition.
buy estrace cream estrace pills cost estrace online pharmacy
buy bactrim online australia bactrim tablets 400mg 80mg bactrim ds online
As a doctor, I can recommend exploring the lisinopril price in India as a potential option.
164 avana buy avana 200 mg avana usa
I wouldn’t trust any website claiming to have Clomid for sale online.
motrin australia
biaxin for strep biaxin ear infection biaxin generic cost
cleocin for acne cleocin t buy cleocin online
vardenafil canadian pharmacy vardenafil 20mg tab vardenafil 20mg tablets
Can I still order lisinopril even if I have an existing medication?
I’m not sure if anyone knows where to buy Clomid for men, but I’m willing to take a chance.
The lisinopril 20 mg tablet is known to interact with certain medications, so it’s important to inform your provider of all prescriptions and supplements you’re taking.
where to buy cialis cheap You ll learn about the full range of benefits, and also the potential side effects, the downside
finasteride cost finasteride otc finasteride 5mg generic
motrin price compare
Accutane 20 mg is a popular treatment option for severe acne.
generic ivermectin cream ivermectin lotion for scabies ivermectin 9mg
albendazole cost in canada
I had to forego clomid treatment due to the steep clomid prices.
QQBET4D Situs Togel Online Terbaik
purchase celebrex
avodart prices canada
I’m so grateful for the lower cost of generic Accutane, it’s made such a difference for my skin and my finances.
buy benicar 20 mg benicar 80 mg daily cost of benicar 40 mg
buy prendesone without a prescription
albendazole over the counter australia
where to buy valtrex 1g valtrex pills valtrex 500 india
where to buy fildena fildena 150 fildena 100 canada
clopidogrel plavix plavix uk plavix clopidogrel
ampicillin pill 500mg
budesonide 90 mcg budesonide 9 mg capsules budesonide tablets
diclofenac gel otc diclofenac gel cost diclofenac 1 mg
prednisone 2 mg
You will need to have a prescription from your doctor to buy Allopurinol tablets.
benicar 20 mg prices benicar 12.5 mg buy benicar 40 mg
It is not advisable to order Synthroid without prescription from a certified medical practitioner.
avana 2
V súčasnosti môžu túto službu využívať registrovaní zákazníci internetových kasín a online stávkových kancelárii Tipsport, Doxxbet a SynotTip. Každý z tria legálnych slovenských prevádzkovateľov umožňuje vklad cez sms za minimálne 5 eur. Nižšiu sumu nie je možné previesť na konto. Kým príde prvé krypto kasíno na Slovensko, asi si ešte chvíľu počkáme. Napriek tomu, máte v súčasnosti celkom veľké množstvo možností, ako realizovať vklady a výbery na hráčske kontá v online kasínach. Pokiaľ ide o vklady, tie môžete realizovať prostredníctvom: Minimálny vklad: Čo je to casino vklad, Casino vklad 1 euro, 1 eur vklad, 5 eur vklad, 10 eur vklad, Poplatky za hazardné hry 100 šancí stať sa milionárom stačí urobiť vklad min. 5€
http://www.deckman.co.kr/bbs/board.php?bo_table=free&wr_id=68678
Tipsport je na Slovensku známou značkou. Jedná so najväčší portál, kde sa vsádza na športové zápasy. Tipsport určite nie je neznámy ani hráčom kasínových hier. Táto spoločnosť sa mnohým ľuďom spája predovšetkým so športovým tipovaním, avšak na začiatku roka 2020 Tipsport získal licenciu aj na prevádzkovanie online kasína, a tak si tu v súčasnosti už môžete vychutnať zábavu aj na hracích automatoch, rulete či blackjacku. Ak chcete hrať v aplikácii, hráči v každej nasledujúcej verzii pokeru môžu ľahko nájsť. Mobilné kasíno s bonusom za vklad 2023 robia to preto, efekty a zvuky televízneho programu cez 20 veľmi fialové výplatných línií. Je to preto, ktorá sa vyplní. Inokedy sa títo hráči zaoberajú tienistým kasínom, ktorí pri hazardných hrách zasiahli jackpot.
is a prescription required for antabuse disulfiram with no prescription antabuse canada
Can I buy Accutane without prescription?
The allopurinol 100mg tablets price here is absolutely unbeatable.
atarax 25 mg cost
buy avodart australia
diclofenac capsules 100mg diclofenac 150 mg tablets diclofenac australia over the counter
buy dapoxetine in us dapoxetine usa buy buy dapoxetine cheap
medicine trazodone 50 mg trazodone brand trazodone medication over the counter
best dapoxetine tablet in india avana 200mg dapoxetine for premature ejaculation
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
I’ve looked everywhere to buy Clomid for men, but no luck yet.
The generic Lyrica cost is a game-changer for those who rely on medication.
buy amoxicillin usa
I need to buy Clomid pills online, but I don’t wanna get ripped off. Any suggestions?
That zyloprim allopurinol is a real bitch to swallow.
Accutane 30 mg should not be taken during pregnancy as it can cause birth defects.
generic avodart canada avodart online pharmacy cost of avodart generic
My doctor recommended Lisinopril 40 mg tablets and they did nothing for me.
propecia no prescription usa propecia prescription online propecia buy india
online shopping pharmacy india save on pharmacy canadian pharmacy without prescription
Say goodbye to expensive fertility treatments and buy cheap Clomid from us.
cost of generic tretinoin
canadian pharmacy sildenafil
benicar 12.5 mg cost benicar 40 mg benicar generic substitute
plavix 150 mg online plavix can i buy plavix over the counter
albuterol 1.25 albuterol tablets for sale where to buy albuterol australia
albuterol asthma albuterol 90 mcg generic albuterol over the counter canada
How to Clomid may involve lifestyle changes like reducing stress and increasing physical activity.
budesonide 9 mg tablets in india
My doctor prescribed me Lasix 500 mg tablets for my edema.
buy diclofenac without prescription diclofenac brand name in usa buy diclofenac 1 gel online without script
buy baclofen usa buy baclofen online uk baclofen 10 mg price in india
Self-medicating with Lisinopril without prescription could result in treatment failure.
amoxicillin 3107
POL4D SITUS JUDI ONLINE TERBAIK DI 2023
suhagra 50 mg buy online india suhagra online india suhagra 100 online purchase
The modafinil pills online that I got did not work as advertised.
generic for benicar cheap benicar online buy benicar
I heard it’s cheaper to buy Synthroid in Canada, is that true?
top darknet market 2023 darknet markets dread
buy generic plavix online plavix otc cost of plavix 75 mg
Synthroid online Canada provides easy access to essential medication for those with busy schedules.
levaquin 750 levaquin 750 levaquin 500 mg levofloxacin antibiotics
amoxicillin 500mg online amoxicillin 500 mg online where can you get amoxicillin
propecia .5 mg finasteride 1mg tablets for sale propecia no prescription
acyclovir over the counter canada
acyclovir 5g
cymbalta generic
can i buy vermox over the counter
citalopram capsules
generic augmentin online
buy cafergot online
where can i buy prednisone without prescription
cafergot cost
buying from canadian pharmacies
price of vermox south africa
how to get cialis prescription in canada
cheap xenical uk
diflucan generic australia
augmentin generic brand
hq pharmacy online 365
darknet market fake id https://dark-market-heineken.com/
zithromax 250 mg canada
canadian pharmacy tadacip
5094 prednisone
plaquenil 100mg price
glucophage mastercard
tadacip online uk
motilium online
canadian online pharmacy tadalafil
atarax for children
buy genuine levitra online
motilium online
lexapro.com
prednisone on line no prescription
generic levitra 2018
azithromycin 250 mg where to buy
where can i buy cipralex
cheap tadacip
inderal 100mg
strattera price canada
tadalafil online from canada
how to get valtrex in mexico
vermox usa
all med pharmacy
cheap generic synthroid
levaquin medicine
cialis 800mg black
can i purchase phenergan over the counter
canadian pharmacy prices
The most searched in google about this game is slotomania vip, Slotomania free coins, free coins slotomania. New year come so collect Slotomania Free Coins 2022 – 2021 , slotomania facebook. Category: Suggestions Hi Slotomania fans!We’ve made a new update to Clan Points that will improve your game experience! Now Clans have become even more fair, equal, and simple to understand for all players. Have fun and enjoy the exciting changes! The most searched in google about this game is slotomania vip, Slotomania free coins, free coins slotomania. New year come so collect Slotomania Free Coins 2022 – 2021 , slotomania facebook. These Slotomania free coins collected from links are credit instant in your account, and there is no need to download any other software or any other surveys. Slotomania offers a variety methods for collecting free bonus codes, royal diamond, silver, brass, platinum, diamond, including free coins from Facebook, Instagram, twitter and direct links from mail. Slotomania free coin links can be grabbed from all social media and direct links.
http://fit-girl.co.kr/bbs/board.php?bo_table=free&wr_id=37888
JavaScript seems to be disabled in your browser. For the best experience on our site, be sure to turn on Javascript in your browser. These chips are 8 gram professional grade, standard casino size. We can help you design a standout product for business or personal use. 100 Chip Sets start at $143.96300 Chip Sets start at $276.96500 Chip Sets start at $419.961000 Chip Sets start at $674.96 500 Piece Desert Sands Set Introducing our new Classic 100% Plastic Playing Cards. These cards are 100% Plastic and compares to thickness of Modiano Da Vinci Cards and flexibility of Copag. The cards come Poker Size Jumbo… Challenge Coins Cash games with short stack buyins use about 60 chips per player (30 chip stack x 2 allowing for a rebuy). These Custom Poker Chips also work great with any QR Code you choose printed on one or both sides! See the sample Custom QR Code Poker Chip below.
azithromycin antibiotics
prednisone 20 tablet
furosemide 400 mg tablets
acyclovir cream canada pharmacy
buy zoloft uk
cost of generic augmentin 875 mg
propranolol prescription canada
darknet reinkommen https://dark-market-heineken.com/
plaquenil generic cost
buy plaquenil
accutane online uk
tadacip 20 canada
celebrex 200mg buy
trazodone 9 mg
tetracycline brand name canada
disulfiram purchase uk
darknet market avengers https://dark-market-heineken.com/
atarax 25mg uk
online pharmacy reddit
prednisone price south africa
generic cialis 60 mg india
canada levitra online
furosemide 200 mg
cialis 5mg australia
augmentin 875 mg 125 mg
retino gel
lipitor 5mg daily
neurontin 100 mg capsule
dark market 2023 dark markets ireland
reddit darknet market 2023 australian dark web vendors
links tor 2023 darknet bank accounts
dark markets venezuela darknet sites drugs
tor2door darknet market darknet drugs india
vermox otc canada
bitcoin darknet drugs dark markets uruguay
dark web shopping tor2door market
back market trustworthy urls for darknet markets
dark markets singapore Abacus Market link
darknet guns market monkey x pill
pill with crown on it buying things from darknet markets
deep web drug url darknet market url list
darknet markets 2023 updated darknet market drug prices
reddit best darknet markets dark web markets 2023 australia
drugs on deep web Cocorico Market
what is darknet markets reddit biggest darknet market place
dark markets ukraine darknet markets most popular
onion directory 2023 brucelean darknet market
darknet markets list reddit orange sunshine pill
darknet dream market link darknet market adressen
darknet software market tor2door market darknet
vermox price
drugs on deep web dark websites
darknet market links safe dark web cvv
Heineken Express darknet Market dread onion
darknet market adressen dark markets bulgaria
azithromycin over the counter mexico
black market dark web links russian darknet market
which darknet market are still up how to access dark net
what darknet markets sell fentanyl darknet drug vendor that takes paypal
crypto market darknet top ten deep web
guide to darknet markets how to order from dark web
dark net market darknet market get pills
retino 05 cream
verified darknet market tor market links
darknet drug store reddit darknet market superlist
darknet market links 2023 reddit uk darknet markets
reddit darknet markets noobs brick market
bitcoin dark web the darknet market reddit
darknet markets list pink versace pill
darknet websites drugs good dark web search engines
live onion market deep web links 2023
tadacip from india
dark market link how to find the black market online
darkfox market reddit onion list
azithromycin amoxicillin
top 10 pharmacies in india
darknet markets list 2023 darknet market bible
darknet markets onion address wiki darknet market
bohemia market darknet in person drug sales
lasix 12.5 mg
the darknet markets access darknet markets
versus darknet market darknet online drugs
counterfeit money onion black market buy online
the dark web url buying from darknet market with electrum
deep dot web markets darknet markets with tobacco
incognito link how to buy from darknet
trusted darknet markets deep web shopping site
how to buy bitcoin and use on dark web the dark web links 2023
dark markets monaco archetyp market darknet
fullz darknet market dark markets luxembourg
darknet drugs links how to find the black market online
vice city market darknet Cocorico darknet Market
dma drug deep net access
ethereum darknet markets black market online website
step by step dark web what darknet markets are still open
dark markets usa most popular darknet markets 2023
dark websites darknet market status
strattera cheapest price
darknet market carding open darknet markets
tadacip 5mg price
darknet markets deepdotweb dark web hitman for hire
deep web marketplaces reddit which darknet market are still up
dark markets guyana unicorn pill
buying on dark web dark markets guyana
live dark web Abacus link
medical pharmacy south
darknet markets still up darknet adress
links da deep web 2023 how to shop on dark web
deep web links 2023 dn market
reddit biggest darknet market place which darknet market are still up
darknet database market euroguns deep web
darknet market reddit 2023 dark web markets
tadacip 20 mg
dark web hitmen darknet drugs malayisa
black market bank account nike jordan pill
darknet market links buy ssn darknet markets with tobacco
darknet market and monero Abacus darknet Market
tor2door market australian dark web markets
black market sites 2023 darknet market pills vendor
tor search engine link underground black market website
underground dumps shop tor link list 2023
biggest darknet markets 2023 online black market uk
best darknet market may 2023 reddit dark web markets reddit
drugs darknet vendors tor2door link
can you buy prednisone in canada
duckduckgo dark web search guns dark market
darknet reddit market pills Heineken Express url
metformin 500mg tablets in india
dark markets philippines what is the darknet market
darknet search engine url dark markets san marino
dark markets luxembourg darkweb sites reddit
best darknet market uk top darknet markets
Abacus Market darknet darknet online drugs
clonidine purchase
average cost of generic prednisone
Kingdom darknet Market darknet drugs market
dark web link dark markets usa
darknet market package access the black market
canadian pharmacy mall
deep sea darknet market black market alternative
darknet market lists darknet vendor reviews
wikipedia darknet market tor drugs
current darknet market darknet market listing
black market drugs deep web drug store
ethereum darknet markets what darknet markets are up
dark web xanax russian darknet market
dark markets austria darknet market place search
credit card dumps dark web dark markets norway
archetyp market darknet reddit working darknet markets
black market url deep web deep cp links
pharmacy discount card
onion market alphabay solutions reviews
reddit darknet markets links dark markets uk
tor onion search best darknet market may 2023 reddit
phenethylamine drugs alphabay market net
incognito link dark markets united kingdom
link darknet market top dumps shop
reddit darknet markets links alphabay link reddit
can i purchase valtrex over the counter
darknet black market list market deep web 2023
onion seiten deep deep web links
darknet database market drugs on darknet
incognito url dnm xanax
aralen
darknet adressen darknet markets reddit
working dark web links deep net links
darknet drug delivery darknet drugs malayisa
deep web deb black market cryptocurrency
deep web hitmen url tor markets 2023
agora darknet market how to search the dark web reddit
dark web drugs how to access the black market
how to darknet market australian dark web markets
links da deep web 2023 updated darknet market list
lisinopril 5 mg tablet price
reddit darknet market 2023 live darknet markets
blacknet drugs Abacus Market url
darknet drug markets working darknet markets
darkfox market url dark markets indonesia
buy cheap tadacip
back market trustworthy darknet bank accounts
dark markets spain cp links dark web
gray market place best darknet market for guns
versus market darknet versus project darknet market
how much is seroquel
the dark web links 2023 buying drugs on darknet
darknet market alphabay nike jordan pill
decentralized darknet market dark web markets reddit 2023
darknet seiten dream market archetyp market darknet
verified darknet market active darknet market urls
darknet prices black market alternative
dark web market links decabol pills
darknet drugs sales dark markets san marino
aralen 250
darknet markets address how to get to darknet market safe
darknet market get pills darknet markets without login
best tor marketplaces onion dark web list
darknet telegram group how to access the dark web 2023
how to order from dark web google black market
elimite cream cost
propranolol brand name usa
darkfox market url dark markets china
how to access darknet markets reddit buds express
dark web search engines link lsd drug wiki
buy drugs online darknet gray market place
canada online pharmacy accutane
10 mg zoloft
dark markets andorra darknet drug prices uk
new onion darknet market new darknet market reddit
reddit darknet market guide black market bank account
bitcoin dark website best dark web counterfeit money
buy bitcoin for dark web best black market websites
darknet stock market buying darknet drugs
url hidden wiki dark market links
underground black market website dark web drugs
deep web link 2023 black market prescription drugs
darknet live stream black market illegal drugs
buy inderal online without prescription
tor2door market link drugs on the deep web
black market dark web links wiki darknet market
darknet cannabis markets best dark net markets
bohemia url darknet markets australia
xanax darknet markets reddit darknet markets best
asap market dark web store
tramadol dark web darknet litecoin
how to darknet market what darknet markets are still open
biggest darknet market reddit darknet markets 2023
access darknet markets onion linkek
black market illegal drugs dark web sites links
deep web links reddit tfmpp pills
darknet markets list reddit how to access the dark web safely reddit
Cocorico Market url how to anonymously use darknet markets
generic augmentin price
darknet market adderall prices dark web search tool
credit card dumps dark web onion directory
tadacip 20
bitcoin cash darknet markets darknet gun market
ketamine darknet market hacking tools darknet markets
how to access dark net how to buy from darknet
best fraud market darknet black market website legit
new alphabay darknet market archetyp darknet market
price of propecia in usa
best dark web markets 2023 deep website search engine
black market drugs redit safe darknet markets
wiki darknet market deep web links 2023
legit darknet markets 2023 darknet market list
darknet market list url bohemia market
darknet market canada darknet websites wiki
darknet market list how to get on the dark web
darknet drug vendors darknet market links buy ssn
how to get on the dark web android darknet gun market
dark web sites name list darknet sites
redit safe darknet markets trusted darknet vendors
onion tube porn dark web sites for drugs
metformin price in india
dark markets greece darknet market listing
darknet market credit cards darknet drugs market
orlistat generic
legit darknet markets what darknet markets are live
dark markets bosnia duckduckgo onion site
gabapentin 25 mg tablets
decentralized darknet market which darknet markets accept zcash
darknet markets dread tor marketplaces
how to create a darknet market best dark net markets
darknet markets reddit links tor markets
grey market drugs deep sea darknet market
tor search onion link bohemia darknet market
how to access the dark web reddit fullz darknet market
darknet market directory how to buy from darknet markets
prednisolone 5mg tablet price in india
what darknet markets are still up deep web updated links
Cocorico Market darknet darkfox url
darknet illicit drugs darknet market links reddit
darknet drug vendor that takes paypal black market online website
alphabay market url dark web sites links
underground dumps shop darknet market drug
australian dark web markets darknet markets list 2023
darknet market bible deep web trading
dark web markets reddit 2023 tor market darknet
darkfox url the real deal market darknet
fake id onion dark market sites
purchase levaquin
darknet illegal market best darknet market for weed 2023
dark web markets 2023 Kingdom Market link
what is the best darknet market australian darknet markets
bitcoin drugs market how to buy things off the black market
darknet markets dread euroguns deep web
list of darknet markets reddit live onion market
strattera 25mg cap
xanax on darknet tma drug
black market websites 2023 dark markets indonesia
bitcoin dark website url hidden wiki
darknet markets most popular buying drugs online
tormarket onion dark web market links
furosemide tabs 20mg
search darknet markets onion market
valtrex 500mg
metformin 5 mg
how to create a darknet market cp links dark web
dark web sites name list darknet drug prices
verified dark web links darknet market ranking
biggest darknet markets 2023 darknet market francais
how to get to the black market online buying on dark web
bitcoin dark website onion deep web wiki
darknet markets list 2023 hidden marketplace
how to order from dark web dark web markets 2023 australia
how to shop on dark web working dark web links
darknet market vendor guide reliable darknet markets lsd
onion directory list dark web markets reddit 2023
darknet links markets best darknet drug market 2023
darknet market drug prices pink versace pill
seroquel 60 mg
where i can buy metformin without a prescription drugs
drug website dark web asap url
darknet market link updates darknet websites list 2023
can you buy elimite cream over the counter
darknet market forum dark markets netherlands
retino gel
dark web shop dark markets brazil
superlist darknet markets counterfeit money deep web
dark markets new zealand dark web vendors
darknet websites tramadol dark web
dark markets switzerland darknet onion links drugs
Abacus Market underground black market website
dark markets india drug market darknet
buy bitcoin for dark web darknet markets reddit 2023
best darknet market 2023 reddit dark markets united kingdom
darknet market reddits dark markets new zealand
tor link search engine dma drug
dark markets macedonia onion market url
vice city market darknet darknet websites wiki
darknet marketplace cypher url
darknet markets up dxm pills
buy drugs darknet dark markets serbia
onion directory list online black market uk
versus project market darknet darknet markets dread
darknet market reddit darknet live stream
how to buy bitcoin for the dark web darknet market canada
dark markets canada dark market sites
the dark web url underground website to buy drugs
links tor 2023 darkfox darknet market
xanax on darknet site darknet market
darknet websites dark markets greece
dark market 2023 tor2door market link
celebrex price australia
darknet credit card market Cocorico Market url
black market websites tor ordering drugs on dark web
how to buy bitcoin for the dark web what darknet markets are still open
how to browse the dark web reddit darknet list
darknet guide adresse onion
verified dark web links dark markets denmark
black market cryptocurrency darknet drugs shipping
dark web trading dark markets australia
darkmarket link biggest darknet market
top dark net markets deep web drugs reddit
darknet marketplace drugs new dark web links
how to create a darknet market dark markets paraguay
dark web buy credit cards incognito url
accessing darknet market deep cp links
asap darknet market bitcoin black market
best darknet market drugs best darknet market for heroin
darknet drug dealer outlaw market darknet
dark markets 2023 dark web sites
buy valtrex online in usa
how to access darknet markets darknet market drug prices
dark web fake money best black market websites
lexapro celexa
how to buy bitcoin for the dark web darknet drugs url
onion deep web search how to access the dark web through tor
incognito market darknet top darknet drug sites
dark markets croatia how to enter the black market online
how to get on the dark web legit darknet sites
live onion reddit darknet market noobs
reddit darknet market noobs bible onion link search engine
darknet market onion links darknet markets still open
how to use the darknet markets onion market
hidden wiki tor onion urls directories tormarket onion
alphabay market darknet darknet onion markets
deep web cc dumps darknet market reviews
best darknet market links online drug market
wired darknet markets darknet market comparison chart
retino cream
black market dark web links working darknet markets
shop valid cvv dark web links 2023
hitman for hire dark web darknet market for noobs
prednisolone 3 mg
black market prescription drugs dark markets turkey
darknet drug dealer best dark web links
darknet market carding darknet market stats
dark markets singapore crypto market darknet
darknet markets still open Abacus Market
darknet paypal accounts darknet market links
list of darknet drug markets pax marketplace
agora darknet market tor markets
viagra singapore pharmacy
tor drugs reddit darknetmarket
best dark web counterfeit money darknet credit card market
Kingdom url the onion directory
blacknet drugs hire an assassin dark web
reddit onion list access the dark web reddit
darknet markets 2023 updated darknet market reviews
buy darknet market email address dark web links market
cypher market darknet list of darknet drug markets
darknet market comparison chart dark web markets
darknet guns market darknet market forum
cleocin cream and alcohol
pink versace pill deep web search engine 2023
darknet markets for steroids dark web step by step
hire an assassin dark web buying drugs online on openbazaar
dark markets india tor darknet sites
darknet market features reddit biggest darknet market place
deep web canada darknet markets with tobacco
deep web url links tramadol dark web
darknet market for noobs dark markets ireland
fake id dark web 2023 darknet market for noobs
black market prescription drugs for sale russian darknet market
darknet market dmt buy drugs from darknet
best darknet market for weed uk darknet reddit market
darknet drugs malayisa how to access the dark web safely reddit
woman viagra
onion links 2023 onion live
darknet market directory onion dark web list
dark markets ukraine largest darknet market
buy bitcoin for dark web deep dark web markets links
black market websites tor dark markets sweden
new dark web links alphabay market onion link
naked lady ecstasy pill darknet market noobs reddit
cypher market link bitcoin black market
dark web in spanish darknet paypal accounts
wikipedia darknet market best dark web links
underground website to buy drugs dark market link
darknet illegal market darknet bank accounts
darknet market noobs step by step most popular darknet market
cypher market link access the black market
market deep web 2023 australian darknet markets
deep web search engine 2023 where to find darknet market links
how to get to darknet market Heineken Express url
best darknet market drugs agora darknet market
underground market place darknet onion market url
live onion market black market access
tor marketplaces darknet market comparison
reddit darknet market noobs dark web poison
lipitor no prescription
darknet market litecoin dark markets uk
versus project market url dark web search engines link
dark markets uruguay onion seiten
canadapharmacyonline
black market websites 2023 tor market nz
how to find the black market online australian darknet markets
darknet market pills vendor darknet market busts
buying drugs on the darknet darknet market drug prices
dark web fake money black market deep
underground hackers black market bitcoin darknet drugs
blockchain darknet markets best websites dark web
darknet market noobs bible how to buy from the darknet markets
cymbalta 30 mg price
dread onion darknet website for drugs
deep web search engine url euroguns deep web
alphabay link reddit dark market reddit
current best darknet market dark market links
prednisone 7.5 mg
active darknet markets darkmarket website
viagra 200mg pills
dark web sales dark web hitman for hire
dark websites darknet markets without login
bitcoin dark website deep deep web links
deepdotweb markets dark web store
tor market list darknet market forum
darknet best drugs how to use the darknet markets
darknet market listing dark web drug marketplace
cypher market link darknet market credit cards
underground black market website tor2door market
reddit darknet market noobs bible adresse dark web
Cocorico Market deep net links
darknet market sites and how black market url deep web
best darknet market for steroids darknet websites drugs
dark web sites underground card shop
dark web markets 2023 best darknet markets
prozac prices canada
urls for darknet markets dark web prostitution
dark markets slovakia new darknet markets
dark web poison what is escrow darknet markets
baclofen medication 10 mg
can i buy augmentin over the counter
what darknet markets are still open guide to using darknet markets
robaxin 750 pill
adresse onion black market active darknet markets 2023
dark markets 2023 dark web drug marketplace
archetyp market url how to get on the dark web on laptop
dark web markets tor markets links
drug markets dark web dark websites
onion market blackweb
the dark internet deep web links
dark web markets darknet market links
darkmarkets black internet
dark web links darknet market links
tor markets links darkweb marketplace
darknet market list dark web site
tor market links dark market onion
dark internet tor dark web
darknet market lists darknet markets 2023
dark market url dark web market
dark web market darknet drug market
dark web websites the dark internet
deep web drug links dark market url
motilium uk
tor darknet dark market url
darknet marketplace drug markets dark web
cheap generic amoxicillin
best price for advair
dark web drug marketplace dark web market list
deep web drug url dark markets
darkmarket darknet market
dark website tor market links
dark web site dark web market
dark internet dark website
dark web market links onion market
tor markets 2023 darknet market links
darkmarket link dark web markets
dark web drug marketplace bitcoin dark web
darkmarket list darknet markets
zoloft 214
darknet market list dark websites
pharmacy store
tor market dark internet
dark web search engine dark market
dark web markets dark markets
dark web drug marketplace deep web drug markets
dark web market dark markets
black internet deep web drug markets
onion market dark website
dark market 2023 dark web access
deep web drug url tor market
tadacip for sale
darknet markets 2023 darknet market lists
deep dark web black internet
provigil medicine
free dark web darknet markets
dark market onion darknet sites
darknet drug links deep web drug markets
furosemide 20 mg generic
motilium medicine
dark market onion darknet market
darkmarkets deep web drug markets
darkmarket 2023 blackweb
tor market onion market
tor market url bitcoin dark web
darknet markets 2023 how to get on dark web
darknet drug links dark web links
dark web search engines darknet drug market
drug markets dark web dark web markets
darknet drug market tor markets 2023
drug markets dark web darknet market
dark web search engines darknet drug market
how to get on dark web darkmarket
dark web market list black internet
dark web search engines tor market
darknet market list how to get on dark web
deep web drug store blackweb official website
deep web drug url the dark internet
darkmarket link darknet market list
darkmarket url dark market link
dark market darkmarket url
deep web links dark web sites links
darknet sites darknet seiten
atarax drug
dark internet dark markets 2023
darkmarket how to get on dark web
dark web market darknet seiten
generic strattera 2017
deep web links dark net
darknet market links darkmarkets
darkmarket url darknet drugs
darknet drug market darkmarket url
dark web search engines darknet drug market
tor darknet darknet marketplace
darknet markets the dark internet
dark website dark market 2023
dark markets 2023 deep web sites
drug markets onion deep web search
tor market url how to get on dark web
darknet markets deep web drug markets
dark market onion dark markets
drug markets dark web dark web search engines
tor markets dark web market list
darknet site darknet links
darknet markets 2023 dark web search engine
black internet dark web site
the dark internet darknet drugs
deep web drug url dark web market
deep web links darknet marketplace
darknet market list darknet drug store
dark web access dark net
dark web sites black internet
darkweb marketplace dark web search engines
tor darknet how to get on dark web
drug markets dark web how to get on dark web
darknet drugs dark web market list
darknet market list deep web drug links
dark web sites darkmarket list
dark website darknet sites
dark websites darknet market lists
tor markets darkweb marketplace
cleocin 150 mg cost
dark web link how to get on dark web
onion market dark web links
dark market dark web drug marketplace
dark web markets how to get on dark web
black internet deep web drug url
darkweb marketplace how to access dark web
dark websites deep web links
dark web access tor market links
dark markets darkmarket list
dark web search engine dark net
dark markets darknet drug market
dark web sites links tor markets
tor darknet dark web sites
dark web markets dark web websites
dark website deep web drug links
dark markets 2023 tor market links
dark web market list darknet websites
darkweb marketplace how to get on dark web
darknet drugs tor marketplace
blackweb official website tor market
darknet market lists deep web links
gabapentin 30 mg capsules
darknet site dark web market
dark web link darknet markets 2023
valtrex medication cost
dark websites darknet market lists
darkmarkets bitcoin dark web
dark web markets darkmarket list
darkmarket url blackweb official website
dark net dark net
robaxin 750 mg over the counter
prednisone daily
where can i buy robaxin in canada
deep web links darknet search engine
deep web search dark market 2023
tor market links darknet market links
black internet dark web markets
tor market how to get on dark web
darknet drugs darknet site
compare valtrex prices
how to access dark web tor markets links
darknet drug links how to get on dark web
lipitor uk price
darknet market free dark web
dark web sites links dark markets
dark web markets dark web drug marketplace
darknet drug links dark web market list
onion market drug markets dark web
darknet websites darkmarket url
darknet markets 2023 free dark web
dark market list the dark internet
dark websites darknet seiten
tor market best darknet markets
dark web access bitcoin dark web
darkmarket darknet drug market
how to access dark web dark web drug marketplace
wellbutrin for sale
dark web search engines tor market links
deep web drug store darknet marketplace
dark web link deep web drug store
darknet market list dark market 2023
darknet markets 2023 deep dark web
darknet links tor market url
deep web links darknet market lists
tor market darkmarkets
darknet websites darknet markets 2023
deep web sites darkmarket link
deep web drug url dark web market list
lasix medicine
dark web websites dark web link
dark web markets deep web search
deep web drug store darknet market list
blackweb darkmarkets
darknet marketplace deep web sites
tor marketplace bitcoin dark web
dark market darknet market list
darknet search engine black internet
darknet site dark internet
how to access dark web dark web link
darknet drug market darknet sites
darkweb marketplace deep dark web
blackweb official website best darknet markets
deep dark web darknet links
can i buy lipitor over the counter
darknet drug store dark web link
best darknet markets dark web market links
darknet markets 2023 bitcoin dark web
darkweb marketplace dark web markets
reliable canadian online pharmacy
deep web drug url dark web websites
darknet markets 2023 darknet search engine
the dark internet dark web site
darknet markets dark market onion
darknet site deep web drug links
deep dark web darknet drugs
darknet links dark internet
dark web websites darknet market
dark web sites dark web drug marketplace
tor market dark markets 2023
onion market darkmarket link
dark web market list dark internet
darknet market darknet marketplace
tor markets darkmarket 2023
dark market link darkmarket list
drug markets dark web darkmarket url
darknet seiten deep web search
dark markets tor market url
free dark web dark web sites links
darkmarket url dark market
darkmarket tor marketplace
darknet market list darknet drug links
dark web search engine darknet sites
dark markets 2023 darkmarkets
dark web drug marketplace deep web markets
darkweb marketplace deep web sites
clindamycin over the counter canada
drug markets dark web darknet drug links
darknet drugs dark web link
dark website dark web search engines
dark web sites links drug markets onion
blackweb darknet markets 2023
darknet drugs dark markets
dark market url dark web search engine
prednisone 10mg tabs
tor market url dark market link
onion market darkmarket list
dark internet dark web links
drug markets onion darknet links
darknet market blackweb official website
deep web markets darkmarket link
blackweb darknet market links
dark market 2023 best darknet markets
deep web drug links deep dark web
tor marketplace deep dark web
darkmarket darknet seiten
canadian world pharmacy
blackweb official website dark market onion
deep web drug markets darknet market list
darknet websites darknet market list
tor markets deep web drug url
drug markets dark web darknet markets 2023
dark market 2023 dark web access
dark net dark markets 2023
dark web market dark web search engines
dark market url darknet seiten
dark web access dark market link
darknet search engine dark web access
deep web markets dark web access
dark market url dark websites
darknet drug store darknet market lists
darkweb marketplace dark markets
dark web drug marketplace darkmarket
tor marketplace darknet drug links
dark web drug marketplace dark web search engines
best darknet markets how to access dark web
dark web sites dark market link
dark web markets tor dark web
amoxil cost uk
bitcoin dark web darknet market list
tor market links deep web search
tor markets 2023 darkmarket 2023
dark web link dark web sites
tor market links tor market url
deep web links dark market url
darknet market lists free dark web
tor darknet dark market onion
retino 0.5 cream price
dark net dark web drug marketplace
clindamycin 150mg capsules price
dark websites darknet market links
dark market onion darkmarket list
bitcoin dark web darknet markets 2023
darknet drug market deep web markets
dark websites deep web drug url
dark market 2023 how to get on dark web
dark market url darknet marketplace
darkmarket 2023 dark web market
tor marketplace deep web drug store
dark websites dark web sites
darknet markets 2023 darknet marketplace
tor markets darknet markets 2023
dark markets 2023 black internet
where to buy xenical in canada
darkmarket 2023 darknet search engine
dark markets drug markets onion
tor markets deep web links
buying metformin canada
dark markets 2023 darknet market list
tor darknet tor market url
blackweb official website dark net
purchase viagra online canada
dark web search engine darkmarkets
dark market darkweb marketplace
best darknet markets dark websites
indian pharmacies safe
how to get on dark web dark web search engine
darkmarket url darknet search engine
dark market bitcoin dark web
how to get on dark web darknet drug market
darknet drugs darknet site
darkmarket link dark market 2023
blackweb the dark internet
darkmarket url deep web markets
dark web market list darknet market
dark web search engines darknet site
lyrica 100 mg coupon
dark web search engines deep web links
darkmarkets darkmarkets
tor market links deep web markets
darknet drug links darkmarkets
darknet marketplace darknet market list
dark market 2023 onion market
dark markets darknet markets 2023
onion market dark web access
online pharmacy 365 pills
darknet drug links dark market onion
darknet market links dark web markets
dark market list darknet drug market
deep web drug links darknet links
best darknet markets darknet search engine
diflucan over the counter nz
dark market url tor marketplace
dark market list tor marketplace
dark web sites dark web access
drug markets onion free dark web
prednisone 2.5 mg cost
how to get on dark web the dark internet
deep web search darknet drug market
darkmarket 2023 tor market links
deep web drug url dark web sites links
how to access dark web onion market
bitcoin dark web black internet
deep web drug store darknet links
synthroid 50 mg price
darknet market links how to access dark web
dark market onion blackweb official website
darknet market dark net
tor markets 2023 dark web market links
synthroid 50 pill
chewing viagra tablets
dark web sites links dark net
darknet markets dark websites
darkmarkets darknet drug links
dark web links darknet drug links
darkweb marketplace drug markets onion
retino 0.05 gel
cialis for women
dark web market darknet websites
darknet site bitcoin dark web
darknet websites darkmarket link
bitcoin dark web dark market onion
tor market darknet marketplace
darknet seiten dark web links
darknet market list darknet sites
darkmarket list tor markets 2023
dark web search engine deep web sites
dark markets tor market
darknet search engine darknet marketplace
dark market onion deep web drug url
chloroquine cost per pill
dark market onion deep web search
how to get on dark web deep web drug store
darkmarket url darkmarket link
bitcoin dark web drug markets onion
dark market url darknet market
tadalafil soft gelatin capsules
dark market list dark web market links
dark market url best darknet markets
dark web drug marketplace deep dark web
darknet markets dark markets
dark markets 2023 darknet market links
darknet market links dark net
dark market url tor market links
darkweb marketplace bitcoin dark web
tor market links darknet drug market
darknet sites deep web drug links
deep web drug url darknet drug store
tor market darknet search engine
tor markets dark market list
dark market list dark web markets
darknet market links dark websites
darknet drug store darknet markets 2023
darkmarket list tor market
amoxicillin pharmacy discount
darknet market darkweb marketplace
xenical cap 120mg
darknet markets 2023 dark web sites
dark web market list darknet marketplace
dark web links drug markets dark web
darknet market links bitcoin dark web
deep web markets dark website
dark markets tor marketplace
drug markets onion darkmarket 2023
lipitor generic price comparison
best darknet markets darknet market lists
how to get on dark web dark web sites
the dark internet free dark web
darkweb marketplace black internet
deep dark web tor market links
darknet site darkmarket
dark market 2023 dark web market list
deep web search darknet seiten
dark market 2023 dark market onion
tor darknet dark web market links
drug markets onion dark market onion
darkmarkets blackweb
dark market url deep web markets
free dark web dark website
dark web link darkmarkets
darkmarket url tor markets
amoxicillin 500mg capsules uk
dark websites deep web drug url
best darknet markets dark web sites links
deep web drug store drug markets onion
dark web websites dark web market list
dark market darknet market
darknet drug links deep web links
dark markets dark web links
darkmarket 2023 deep web drug store
strattera medication
drug markets dark web darknet drugs
dark web sites links deep web drug store
best darknet markets darkweb marketplace
dark markets tor dark web
deep web drug links dark market url
deep web links dark markets 2023
40mg citalopram
dark market onion dark market onion
dark web search engine bitcoin dark web
darknet marketplace how to get on dark web
dark web access darkmarket
deep dark web darknet drug store
darkmarkets deep dark web
darknet market list dark internet
dark net tor darknet
darkmarket 2023 how to get on dark web
darkmarkets how to get on dark web
dark web links darknet search engine
darknet markets 2023 darknet market
darknet drug store deep web drug links
dark net deep web drug links
dark web link darknet site
darknet drug market dark web market links
can you buy tadalafil over the counter
strattera lowest price
darknet markets how to get on dark web
bitcoin dark web dark market list
darknet market list deep web links
how to access dark web tor dark web
darknet market list black internet
dark web market links darknet markets
onion market darknet search engine
darkmarkets dark web markets
how to access dark web darknet marketplace
tor dark web tor darknet
drug markets dark web deep web drug links
bitcoin dark web dark net
darknet sites dark markets
dark web links darknet drug store
dark web search engines the dark internet
dark net deep web drug url
blackweb deep web sites
darknet drug market how to access dark web
darknet drugs darknet markets 2023
dark net darknet markets 2023
darknet site deep web drug markets
darknet search engine darknet market lists
dark web links dark web drug marketplace
dark market onion dark market 2023
darknet drugs dark markets
how to access dark web dark market link
the dark internet blackweb
dark web search engines dark markets
deep web drug links darknet drugs
free dark web darknet marketplace
darkmarket dark market 2023
darknet drug market dark website
darknet seiten deep web drug markets
drug markets onion dark market link
costs of tetracycline
deep web drug links bitcoin dark web
blackweb official website dark market list
darknet site darkmarket 2023
tor markets 2023 darknet market
deep web drug store free dark web
tor markets how to get on dark web
deep web search dark web access
dark web access black internet
dark net darknet drug market
darknet site dark markets
dark net tor dark web
deep web drug url dark market list
dark web search engines tor markets
deep web links dark web market list
dark websites darknet markets 2023
how to access dark web blackweb
world pharmacy india
baclofen price australia
dark market dark web drug marketplace
dark web sites links dark web sites
darknet markets free dark web
tor market dark websites
darknet drugs deep web drug store
dark market onion darkmarket list
darknet drug links darknet seiten
dark web sites links deep web links
darknet websites darknet search engine
albendazole medicine
seroquel generic
dark web market tor darknet
retino
darknet websites dark internet
dark websites darknet drugs
drug markets onion best darknet markets
dark website blackweb
dark web sites links darknet drug links
darknet market links darknet drugs
tor market darkweb marketplace
can i buy citalopram over the counter uk
darkmarket dark websites
deep web search tor darknet
darknet market lists deep web search
darknet drugs dark web markets
black internet tor markets 2023
cleocin 300
motilium for sale
dark web market list darknet sites
darknet sites the dark internet
how to get on dark web darknet websites
dark websites how to access dark web
dark internet darknet drug links
darknet marketplace dark web sites
dark websites drug markets dark web
dark website darknet site
dark web market black internet
dark web markets darkmarket 2023
canadian pharmacies compare
dark market link deep web drug store
synthroid 75 mcg cost
tor markets links darknet markets 2023
deep web drug url dark web access
free dark web dark market list
tadacip cipla
darknet seiten deep dark web
the dark internet dark web link
darknet markets dark web market
dark internet darknet sites
free dark web dark websites
darkmarkets dark web link
darknet sites tor markets
darknet drug links dark web links
online pharmacy meds
darknet markets 2023 best darknet markets
dark web sites links best darknet markets
darknet links darknet drug market
darknet links dark market url
viagra how to get a prescription
tor market links free dark web
tor market url tor markets 2023
dark web drug marketplace dark market url
order atarax 25mg online
dark web links bitcoin dark web
darknet market links dark web search engine
xenical 84 cap 120mg
darknet seiten dark web access
darkmarket deep web drug url
buy tadacip 10 mg tablet
lasix 500 mg price
dark web drug marketplace dark web sites
dark web search engines tor marketplace
darknet drug links tor marketplace
dark market onion market
dark market tor market links
darknet seiten dark market list
dark web sites links tor darknet
darkmarket list darkmarket list
dark market list dark market 2023
darknet markets tor markets links
darkmarket drug markets dark web
dark market onion dark web search engine
drug markets onion dark market link
darknet drug store tor darknet
dark net dark market link
dark market dark web websites
tor markets links darkmarkets
darknet market drug markets dark web
dark web websites dark market link
tor market links darknet marketplace
dark web site dark market
tor markets dark web access
dark web sites links dark market link
dark web market list dark internet
tor market links deep web search
blackweb deep web links
tor markets 2023 tor marketplace
dark web sites darkmarket list
drug markets onion dark web markets
tor market darknet drugs
tor market url tor marketplace
dark websites deep web sites
best darknet markets tor markets links
deep web drug markets deep web drug url
dark web market links darknet websites
dark market url dark web site
dark market 2023 tor market url
dark web link dark web market list
xenical online nz
tor market links dark web sites links
darknet drug links darkweb marketplace
dark web site darknet markets
dark markets deep web drug store
black internet deep web drug links
darknet markets 2023 darknet markets 2023
dark web sites darkmarket link
dark web search engines darkmarket url
the dark internet deep web sites
dark market list bitcoin dark web
darkmarket link deep web markets
darknet seiten blackweb official website
darknet marketplace darknet websites
deep web markets darknet drug market
dark web sites links free dark web
deep web drug markets darknet site
darknet site dark net
best darknet markets darknet drugs
robaxin generic price
dark market list dark website
darknet site dark website
where to buy trazodone
deep web drug store darkmarket link
darknet market links dark web market links
tizanidine 4 mg coupon
deep web sites deep web drug store
dark market list darknet search engine
dark web search engine deep web markets
dark web sites darkmarket list
darknet site darknet drug market
how to get on dark web darknet market lists
darknet drug links darknet marketplace
dark market 2023 dark website
deep web drug url darknet markets 2023
robaxin 800 mg
buy cheap augmentin online
tor markets links darknet drug store
darkweb marketplace dark web market
deep web sites dark market list
dark internet black internet
dark web search engines how to access dark web
celebrex coupon
how to access dark web dark web sites links
tor markets dark websites
darknet market links deep web drug links
dark web sites links deep web sites
best darknet markets dark internet
dark web links best darknet markets
darknet markets deep web links
clindamycin india brand name
deep web drug links how to get on dark web
dark markets 2023 tor marketplace
darknet links darknet market links
darknet market links drug markets onion
dark web sites links the dark internet
dark web market list dark market 2023
darknet drug links darknet websites
dark web access darknet websites
deep web drug url dark web search engines
deep web markets darknet markets
pharmacy shop
dark internet blackweb
darknet market links dark web link
dark market list dark market url
darknet market list tor market url
how can i get prednisone online without a prescription
dark markets 2023 dark web link
darknet drugs deep web drug markets
dark markets dark market onion
cheap valtrex
how to get on dark web darknet seiten
darknet links darknet market list
darknet markets 2023 deep dark web
best darknet markets dark market list
cheap elimite
online pharmacy pain medicine
darkweb marketplace darknet marketplace
tor dark web dark net
darknet market links dark web market links
darkmarket dark markets
dark markets 2023 darkmarkets
darkmarket url dark web markets
darknet market lists darkmarket
deep web sites dark web links
darknet links dark net
dark websites dark markets 2023
darknet market list how to get on dark web
tor dark web darkmarkets
synthroid 50 mcg tablet
tor markets dark markets 2023
dark web market links dark website
dark web link blackweb
dark website the dark internet
darkmarket link darkweb marketplace
darkweb marketplace bitcoin dark web
tor markets links deep web drug links
seroquel to mexico
dark web market links dark web links
darkmarket list bitcoin dark web
which online pharmacy is the best
dark websites tor market url
tor markets tor market
dark market onion dark websites
onion market darknet marketplace
blackweb official website drug markets dark web
dark website darknet markets
dark web search engine deep web sites
deep web search darknet drug links
deep web drug store deep web markets
best darknet markets tor market url
cheap strattera online
http://edmeds.pro/# buy erection pills
black internet dark web sites links
tor dark web dark web drug marketplace
dark market list dark web market list
tor market url tor dark web
furosemide 20 mg drug
dark web market list dark market url
tor marketplace tor markets links
darkmarket 2023 dark web links
canadian prescription pharmacy
dark web search engine tor marketplace
tor dark web tor darknet
tor marketplace deep dark web
blackweb tor marketplace
canadapharmacyonline legit: canadian online pharmacy no prescription – canada pharmacy online
dark web sites deep web markets
tor marketplace dark web site
xenical cheap
darknet drug links dark market url
darknet drug links tor markets
dark internet deep web links
how to access dark web dark web site
deep web drug store dark market onion
dark markets dark markets
vermox online usa
darkmarket darknet drugs
where can i buy orlistat in australia
how to access dark web deep web search
darkmarket link the dark internet
deep web search darknet drug store
onion market darknet websites
darknet market deep web drug links
dark websites dark markets
QQBET4D Situs Judi Online Slot Tergacor 2023
tor market links the dark internet
blackweb official website tor dark web
40 mg prednisone pill
buy cheap prednisone online
darknet marketplace deep web search
dark market list deep web search
best darknet markets dark markets 2023
http://pharmst.pro/# pharmacy com
augmentin 1000 mg price south africa
darkmarket url tor markets links
darkmarket link darknet site
dark market tor markets 2023
darknet markets dark web market list
blackweb darknet site
impotence pills best ed medication ed pills that really work
how to access dark web darknet market list
tetracycline drugs
darknet drug links onion market
tor market links dark net
blackweb darknet links
dark internet darkmarket list
darknet drugs darknet search engine
dark markets 2023 darkmarket link
deep web drug markets darknet links
drug markets dark web tor market links
darknet marketplace how to access dark web
diflucan 2 pills
drug markets dark web dark net
dark market link dark web market
onion market darknet market
darknet drug store blackweb
darknet marketplace darknet market links
dark web sites onion market
deep web links dark web market
darknet sites dark markets 2023
dark web sites links deep web search
tor markets links onion market
tor market url darknet market lists
dark markets 2023 dark net
darknet marketplace deep web drug url
best online pharmacy usa
drug markets onion dark web links
dark web sites tor markets
dark web market links darkweb marketplace
deep web markets onion market
buy strattera india
dark website dark internet
darknet drugs dark web search engine
deep web drug links how to get on dark web
darkmarkets free dark web
darknet markets 2023 dark market onion
darknet markets best darknet markets
dark net tor dark web
darknet market links deep web drug store
dark web link tor market url
darknet market list darkmarket
how to get on dark web dark web search engine
tor markets darkmarket url
dark market link dark web links
amoxicillin price south africa
buy levaquin
darknet market lists darknet site
darknet search engine deep web links
seroquel xr 150 mg for sleep
darknet drug store dark web links
dark markets 2023 darknet marketplace
the dark internet blackweb
purchase synthroid
dark website darknet market links
dark web site dark markets
blackweb official website bitcoin dark web
darkmarket list dark web market links
dark web market darknet market links
darkmarkets darknet market
darknet links best darknet markets
tor market darkmarket link
no prescription needed canadian pharmacy
dark web market darknet market
drug markets onion dark web market links
dark web drug marketplace dark market
rx pharmacy
drug markets dark web darknet markets
drug markets dark web darkweb marketplace
onion market how to get on dark web
metformin no prescription
dark web market list free dark web
tor darknet dark web search engine
generic synthroid cost
darknet drug links dark market list
dark net darknet site
blackweb best darknet markets
darknet drug links deep web links
darkmarket 2023 darkmarket list
tor darknet how to access dark web
dark web sites dark web site
the dark internet dark web access
cost of vardenafil
free dark web best darknet markets
dark web search engine darkmarket url
free dark web deep web drug store
black internet dark websites
the dark internet dark markets
tor markets links dark web drug marketplace
buy desyrel online
propranolol generic
dark web site deep web drug store
canadian pharmacy meds
blackweb black internet
darknet sites dark websites
darkmarket onion market
how to access dark web dark web websites
how to access dark web darknet drugs
deep web drug url deep web drug markets
darknet marketplace dark web sites
tadacip 20 canada
blackweb dark web access
darknet market list dark market onion
the dark internet dark web market list
blackweb official website darknet market links
darknet market dark website
free dark web deep dark web
how to get on dark web deep web drug url
darknet search engine darkmarket url
darknet drug market dark websites
darkmarket dark web market
darkmarket url how to get on dark web
dark web markets darkmarkets
dark web links how to get on dark web
dark web drug marketplace tor markets
blackweb onion market
tor market url dark market list
darknet market list blackweb
drug markets dark web darknet sites
the dark internet onion market
dark web search engines dark web market
canada pharmacy online
wellbutrin 75 mg cost
darkmarket 2023 deep web drug markets
deep web search deep dark web
dark web markets dark web links
darknet links deep web sites
dark market onion darkmarket
dark web site deep web drug url
dark web access tor market
darkmarket link deep web sites
buy tadacip
your pharmacy online
darkweb marketplace dark web market
darknet market lists darkweb marketplace
darknet drug links dark web websites
darknet marketplace black internet
darkmarket url tor darknet
cheap valtrex online
darkmarket url dark web sites links
dark market deep web sites
darkmarket dark market
dark web websites dark web drug marketplace
synthroid 300 mcg tablets
dark markets dark web access
cafergot 100mg
darknet search engine dark net
dark internet dark web link
darknet market list deep web links
darknet seiten dark web links
darknet markets 2023 dark market list
darknet links how to get on dark web
tor market dark market link
dark web access darknet market lists
hydroxychloroquine 800mg
drug markets dark web bitcoin dark web
cheap scripts pharmacy
darkmarket link dark web sites
dark markets 2023 darknet markets 2023
tor market links darknet drug store
deep web links deep web links
darkmarket tor market url
tor markets 2023 darknet sites
dark internet deep dark web
tor market url darknet links
best darknet markets dark internet
darknet site darknet drugs
darknet markets drug markets dark web
darkmarket link darkmarket 2023
dark websites black internet
drug markets onion darknet market
darknet market links deep web drug links
deep web drug url dark websites
top online pharmacy india
tor dark web drug markets onion
the dark internet dark web search engines
dark websites dark markets
how to get on dark web deep web drug url
deep web drug store darknet market list
darknet seiten darknet drug store
onion market darknet search engine
buy 5mg tadalafil
darkmarket dark websites
darkmarket url darknet sites
dark net darknet market
prednisone buy online uk
deep web drug links tor darknet
dark market deep web markets
tor market links deep web sites
dark web access dark web websites
prednisone 2.5 mg tablet
darknet market list tor markets 2023
darknet market lists blackweb
dark market onion darknet drug store
erythromycin purchase
dark web drug marketplace tor market links
darkweb marketplace blackweb
blackweb dark website
darknet websites darkmarket link
dark web link tor darknet
deep web sites dark website
lyrica 25mg capsule
darknet websites darknet drugs
darknet markets deep web links
tor dark web deep web drug links
the dark internet bitcoin dark web
prednisone brand
black internet dark web search engines
citalopram 40 mg tablet
where to get modafinil online
generic lipitor 10 mg
darknet marketplace best darknet markets
reputable online pharmacy
canadian pharmacy service
dark web markets darknet drug links
darknet drugs dark web drug marketplace
blackweb dark web links
darknet links dark market list
best darknet markets darknet links
clindamycin cream where to buy
dark web sites darknet market list
deep web drug markets best darknet markets
darknet links dark web links
darknet markets darkmarkets
darknet drug links dark web sites links
dark market darknet market links
advair prescription
dark web drug marketplace dark web websites
deep web search darkweb marketplace
darknet drug market deep web links
dark website dark market url
deep web search dark market url
metformin 500 mg otc
darkmarket dark web search engines
deep dark web darknet marketplace
tor darknet blackweb official website
deep web drug links darknet market list
dark web link dark web access
deep web sites darknet links
dark market list dark web sites
dark web access darknet drug store
tor markets dark web market list
darknet sites darknet markets 2023
dark market 2023 dark websites
how to access dark web tor dark web
dark web access dark web search engines
tor marketplace darknet markets 2023
deep dark web darknet drug store
can i buy metformin over the counter in canada
dark web site darknet links
dark web drug marketplace dark market list
darknet seiten dark web links
dark web websites deep dark web
which pharmacy is cheaper
darknet links dark web search engines
diflucan 2 pills
how to access dark web dark market 2023
darknet sites dark web sites links
darkmarket link tor market
dark web site darknet site
prednisone 10mg
drug markets dark web darkmarket list
how to get on dark web darkmarket url
tor markets drug markets onion
darknet drugs darknet markets 2023
dark web market darknet market lists
darknet drugs darkmarkets
dark web links tor marketplace
darkmarket link darkmarkets
how to get on dark web darkmarket url
deep web drug store deep web search
black internet darkmarket 2023
dark web site darknet links
darknet market dark web markets
deep web markets dark website
deep web links tor darknet
darknet websites tor dark web
tor markets links dark web links
The examples you provided made the content more relatable and easy to understand.
dark web sites links darknet drug market
darknet drug store darknet markets
darknet markets 2023 darknet drug links
5000 mg amoxicillin
bitcoin dark web free dark web
dark web market deep web drug store
deep web drug markets dark market link
onion market darkmarket
darknet site dark web market links
onion market dark web links
dark web search engine darkmarket
deep web search darknet markets 2023
darkmarkets deep web links
darkmarket list darknet marketplace
deep web drug store deep web drug markets
dark web sites links tor market
synthroid buy online uk
buy metformin 500mg
darkmarkets darkmarket link
furosemide 3169
dark web sites links darkmarkets
tor markets links dark markets 2023
dark web links dark web sites
tor darknet darknet site
dark web site darknet markets
darknet drug links darknet sites
darkmarket link tor marketplace
darknet seiten darknet seiten
tor marketplace the dark internet
darknet websites deep web search
lyrica cap
dark web market list darknet markets 2023
how to access dark web dark market onion
dark market onion dark website
bitcoin dark web bitcoin dark web
dark web websites dark web sites links
darknet search engine dark net
dark website darknet markets 2023
deep web search dark web sites
clonidine 0.1mg without prescription
dark web site deep dark web
tor markets links dark web sites
dark web market links the dark internet
dark market link dark markets
darknet drug links tor markets links
black internet darknet site
darknet search engine darknet market lists
trimox 250 mg
dark web market list darkmarket url
deep dark web free dark web
tor market dark web market list
dark web search engines dark web access
best price cialis 20 mg
dark market 2023 tor dark web
how to access dark web tor markets links
generic prednisone otc
deep web markets dark web drug marketplace
order cymbalta
deep web search dark web sites
where can i buy elimite
darknet marketplace blackweb
prednisone discount
onion market darknet search engine
tor market links dark web market links
drug markets onion dark market list
dark market link deep web drug links
dark website darkmarket url
dark web search engine the dark internet
darkmarket list black internet
deep web drug store onion market
dark market url darknet market lists
canada discount pharmacy
onion market dark web websites
the dark internet drug markets dark web
tor markets links the dark internet
dark web links blackweb official website
darknet drug market darknet drug store
darknet market lists tor darknet
deep web drug markets darknet market links
darknet drugs dark web sites
deep web markets onion market
buy genuine cialis
dark market onion darkmarket link
deep web sites dark web sites
darknet market darkmarket link
tor markets deep web sites
deep web drug store dark market
deep web drug markets darkweb marketplace
dark markets dark market link
dark market list darknet seiten
dark web link deep web markets
propecia discount
how to get clindamycin over the counter
deep web search darknet drug links
darknet market lists blackweb
baclofen brand
darknet markets 2023 dark web market list
dark web drug marketplace tor market url
tor market url the dark internet
safe canadian pharmacy
darknet site darknet seiten
dark website free dark web
how to get on dark web dark websites
dark web markets darknet websites
tor markets darknet drug store
darkmarket link tor markets
tor markets darknet links
dark web access onion market
darknet seiten darknet drug market
darknet websites dark market 2023
dark market 2023 drug markets onion
azithromycin from mexico
darknet links deep web drug store
dark web sites links darknet drugs
darknet market dark market link
dark market onion dark market 2023
deep web sites darknet marketplace
dark web drug marketplace deep web search
dark market url dark websites
dark market url tor marketplace
dark websites dark website
darknet seiten darknet websites
benicar lisinopril
the dark internet drug markets dark web
best darknet markets darknet market
how to get on dark web dark web market links
deep web links dark web markets
tor market links darkweb marketplace
free dark web deep web drug url
dark market list darknet marketplace
blackweb darkmarket url
darknet sites darkmarket
darknet drug store darkmarket
price of levaquin
deep web search darkmarket url
tor market free dark web
dark web link darkmarket 2023
lipitor 10mg generic
blackweb dark markets
tor darknet darknet drug links
dark web search engines best darknet markets
buy diflucan no prescription
best darknet markets dark market link
deep web drug links dark web search engine
dark market link darknet marketplace
dark market onion darknet markets
darkmarket list deep web drug links
the dark internet dark web drug marketplace
darknet search engine tor market url
dark web market links dark web link
tor dark web tor market links
the dark internet tor darknet
darknet market lists onion market
glucophage 1000 mg tablet
darknet site tor dark web
darkmarket link darknet marketplace
darknet markets deep web links
dark market link darknet market
dark web market list dark web market
deep web search deep web drug url
dark web link dark net
dark web markets dark web markets
dark web market list blackweb
dark market darkmarket link
blackweb darkmarket 2023
darknet drug store tor market links
tor dark web how to get on dark web
dark web market list dark web market list
darknet websites dark web sites
deep web drug links darkweb marketplace
dark internet deep web sites
how to access dark web darkmarket url
strattera 100mg cost
deep web drug url darknet marketplace
darkmarket url dark web market list
tor marketplace dark web search engines
black internet darknet site
dark websites dark web sites
dark net drug markets onion
dark web access dark internet
darknet drugs dark markets
darknet drug store deep web search
dark web market list dark web search engines
deep web drug links tor market
darknet drug market darknet markets 2023
darknet market list dark market list
deep web drug markets dark internet
darknet drug market dark web site
dark website how to get on dark web
darknet market bitcoin dark web
deep web sites dark websites
darknet markets darknet market links
darknet market drug markets dark web
darkweb marketplace darknet search engine
drug markets dark web darknet links
xenical generic brand
dark market deep web markets
seroquel 200 pill
darknet search engine dark web websites
dark web drug marketplace blackweb official website
dark market deep web search
darkmarket list deep web drug links
best darknet markets dark web access
tor marketplace tor markets links
deep dark web darknet market lists
finasteride tablets 1mg price in india
dark web site dark web sites
blackweb official website best darknet markets
deep web drug url deep web drug markets
dark web sites links darknet search engine
darknet market links darknet search engine
darknet markets 2023 darknet drug store
dark web link darkmarket url
darknet sites how to access dark web
deep web drug links the dark internet
drug markets onion dark web market list
darkmarkets dark web websites
drug markets onion blackweb official website
dark web market links tor market links
darknet websites darknet drugs
gabapentin 800 mg tablet
tor markets dark web search engine
tor darknet deep web markets
best darknet markets dark web search engine
tor marketplace blackweb
tor markets 2023 dark websites
brand name drug prednisone
blackweb official website dark market url
darkmarket link dark market url
dark web sites links darknet drug store
darknet search engine tor markets 2023
darknet links darkmarkets
darkmarkets darknet marketplace
100 mg lasix no prescription
bitcoin dark web tor markets
tor market url tor market url
dark market onion darknet websites
blackweb deep dark web
darknet sites darknet markets 2023
dark web websites the dark internet
tor markets links darknet drugs
no prescription required pharmacy
darknet links dark market 2023
how to access dark web darknet market links
dark website darknet markets 2023
onion market darknet links
deep web drug store deep web drug url
tor market links darknet drug market
darknet markets darknet site
darknet links darknet drug store
dark market link tor markets
bitcoin dark web dark web markets
dark market tor dark web
dark market 2023 tor market
darknet drug store dark web sites links
dark web search engines dark web markets
darknet links deep web drug url
how to get on dark web dark websites
dark web websites dark market
darknet site darkmarket list
darknet drug market dark internet
darkmarket link tor marketplace
darkmarket list dark market onion
dark web sites tor markets 2023
dark market dark market link
modafinil 100mg
darkweb marketplace darkmarket
blackweb official website tor market
darkweb marketplace dark websites
dark websites dark web site
darkmarket list darknet site
darknet marketplace tor market links
dark internet darkweb marketplace
darknet seiten dark web link
dark market onion darknet drugs
darkmarket url tor markets
deep web search darknet drugs
accutane cheapest price
darkmarket 2023 darknet markets
deep web drug links darknet market
darkmarket tor dark web
dark web search engines darkmarket url
dark websites tor markets 2023
furosemide 20 mg for sale
tor market links dark web market list
tor marketplace darknet links
darknet websites dark web site
dark web access bitcoin dark web
dark market onion darknet market
how to access dark web darkmarket url
darknet seiten darknet market lists
dark market link dark web site
levitra 10 mg tablet
tor market darknet site
darkmarkets dark web market
dark market deep web links
dark market url darknet markets
dark web websites darknet market list
prednisone drugs
darknet drug store dark web link
the dark internet darknet market links
dark web search engines darknet marketplace
darkmarket list drug markets dark web
darknet markets blackweb official website
accutane price in south africa
dark web markets tor markets
drug markets dark web darknet seiten
dark market url dark web markets
dark market dark web market links
dark web links tor markets links
tor dark web darkmarket list
drug markets dark web dark web access
darknet drug links onion market
darknet site black internet
dark markets darknet search engine
dark market url dark market list
darknet search engine dark web link
dark markets 2023 dark markets
how to get on dark web dark net
dark web sites dark web websites
darkweb marketplace deep web sites
tor market links darkmarket 2023
darkmarket url black internet
drug markets dark web darknet markets 2023
darknet market lists the dark internet
hydroxychloroquine 500 mg
neurontin 300mg caps
medicine clindamycin 150mg
lisinopril 3973
cost of vardenafil
advair 230
colchicine price in mexico
amoxicillin tablets
colchicine price comparison
buy generic viagra online
erythromycin buy
order seroquel online
synthroid 0.05 mg
cafergot cost
levaquin antibiotic
steroid prednisone
augmentin 750 mg
trental tablet
citalopram 20 mg tablets medicine
acyclovir cream over the counter canada
buying lexapro online
cost of amoxil
levaquin buy
buy prednisone without a prescription
amoxicillin 500mg canada
cialis compare prices
buy strattera uk
dark web markets darknet market links
dark web market bitcoin dark web
darknet drug store dark market list
dark markets 2023 the dark internet
deep dark web dark market link
dark market link dark market onion
dark web link dark internet
darknet links blackweb
dark web search engine blackweb official website
darkmarket list how to get on dark web
dark net dark market
deep web sites darkweb marketplace
darknet search engine darkmarket url
dark web websites dark market url
cheap gabapentin online
dark market deep web links
tor markets links darknet markets 2023
darknet market lists darknet seiten
dark web link darknet drug links
darknet markets 2023 tor dark web
dark web markets tor dark web
prednisone 20mg by mail without prescription
tor market dark website
darknet search engine dark market
darknet drugs blackweb
deep web sites black internet
tor market dark market list
deep web drug links bitcoin dark web
dark web site dark web search engines
blackweb official website dark market list
dark market blackweb
drug markets dark web darknet marketplace
dark market list onion market
tor darknet deep web drug markets
deep web markets tor markets links
darknet site darknet site
darkmarket list dark web links
tor marketplace tor market
how to access dark web dark markets 2023
darkmarkets deep web links
how to access dark web dark web market links
synthroid 275 mcg
zanaflex 2mg capsules
darkmarket link drug markets dark web
buy prinivil
where to buy modafinil online
cheap phenergan
advair diskus generic price
dark market onion darkweb marketplace
darkmarket darknet markets
tor markets links darknet drug store
deep web sites tor market url
darknet markets dark web drug marketplace
tor marketplace dark markets 2023
dark web websites tor markets
blackweb blackweb
dark web drug marketplace tor market links
dark market onion dark web drug marketplace
darkmarket list dark web sites
darknet market darknet drug market
deep web links blackweb
black internet darknet links
dark market onion darkmarket link
deep web links darknet drug links
darknet seiten deep web drug links
darknet drug store darknet drug market
dark internet deep web drug url
deep web drug markets tor markets
dark market onion tor darknet
darknet markets tor dark web
dark markets 2023 drug markets onion
dark web market links darkmarkets
darkmarket url darkmarket
dark market 2023 deep web search
darkmarket list tor markets 2023
lisinopril 2.5 mg cost
dark web market deep web links
drug markets onion the dark internet
darknet links dark web links
how to get on dark web drug markets dark web
tor dark web deep web search
clonidine tab 0.1mg
darkweb marketplace dark market onion
onion market deep web search
buy cheap tadacip
12mg tizanidine
onion market dark web markets
glucophage coupon
atarax 25mg online
prednisone tablets canada
buy tadacip tablets online
dark web market links darknet site
darkmarket 2023 how to get on dark web
drug markets dark web bitcoin dark web
deep web links darkmarket url
dark web search engines deep web drug links
how to access dark web tor markets links
dark web search engine darknet seiten
darknet market lists darkmarket list
darknet drugs darknet websites
free dark web dark web market list
deep web markets deep web markets
darknet websites bitcoin dark web
plaquenil 200mg
blackweb official website deep web links
best darknet markets dark market onion
dark market tor marketplace
tor market dark web market
dark market list dark market link
online pharmacy in turkey
darknet search engine darknet seiten
darknet websites tor markets
darkmarket url deep web markets
dark web sites darknet markets
dark market onion darkweb marketplace
bitcoin dark web dark web websites
darknet drug store tor market links
the dark internet darkmarket list
dark internet dark web market links
tor marketplace dark web market
darknet markets 2023 darkmarket
dark markets blackweb official website
black internet dark web market list
deep web drug store tor markets links
cost 50mg prednisone tablets
strattera 25 mg discount
how to get on dark web deep web drug url
tor market url black internet
furosemide cost price
dark web market list dark internet
finasteride coupon
synthroid 15 mcg
tor market links darknet drug links
darkmarkets darkmarket list
tor dark web onion market
tor market dark web market links
dark web sites darknet marketplace
deep web drug links darknet market links
bitcoin dark web deep web drug markets
darknet drug store dark markets 2023
dark internet how to get on dark web
I may need your help. I tried many ways but couldn’t solve it, but after reading your article, I think you have a way to help me. I’m looking forward for your reply. Thanks.
deep web drug url darknet market links
deep web drug store darknet seiten
free dark web tor market url
deep web drug store darknet drug store
onion market dark web access
vip medications buy lasix without prescription
drug markets dark web deep web drug store
how to get on dark web dark web links
dark web sites dark web sites links
darkmarket 2023 darknet market lists
darknet search engine deep web search
darknet drugs dark web markets
darknet markets 2023 dark website
bitcoin dark web darkweb marketplace
tor markets darknet drug store
tor markets links dark websites
how to get on dark web how to access dark web
dark web site dark website
darknet drugs darknet market list
darkmarket 2023 darknet site
darkmarkets free dark web
darknet drug store deep web links
xenical discount
deep web search how to access dark web
darknet markets 2023 deep web drug markets
onion market deep dark web
dark web links darknet market lists
bitcoin dark web best darknet markets
dark net dark web search engine
darknet drug market darknet market links
dark markets dark web search engine
darknet market list darknet site
cheap cialis online
bitcoin dark web tor markets
darknet marketplace darknet site
dark web search engines darknet markets
darknet seiten darkmarket list
dark market onion dark web site
deep web markets darkmarket list
the dark internet dark markets
retino 0.25 cream
tor markets links dark markets 2023
deep web search black internet
dark internet darkmarkets
tor market links dark web sites
zithromax cost pharmacy
darknet market links drug markets dark web
darknet market links dark web markets
dark market link darknet marketplace
dark web search engine darknet markets 2023
dark web market list dark web search engine
darknet drug market tor market
darkweb marketplace tor markets
darknet market dark web access
dark web market darknet markets
where can i buy diflucan otc
darkweb marketplace dark web market links
dark web market links blackweb
darknet websites dark web drug marketplace
drug markets dark web dark web search engines
costs of tetracycline
baclofen 75 mg
darknet search engine dark websites
vermox drug
dark web sites links tor market url
black internet dark web search engine
dark web links dark market
blackweb official website deep web drug store
tor market dark web site
darknet markets dark web market list
dark web drug marketplace deep web links
darknet drugs darkmarket 2023
dark web links darknet drug store
tor market links tor markets links
tor marketplace black internet
deep web drug links how to access dark web
tadacip uk
darknet links dark market url
dark markets 2023 dark web access
metformin online canada
darkmarket url dark web market
dark web search engine tor dark web
dark markets darknet websites
free dark web black internet
dark web sites links dark web market
deep web sites dark net
darknet markets darkmarkets
dark market onion deep web markets
darknet drug store tor markets
dark market list darknet drug market
dark web market darkmarket 2023
darknet marketplace tor market
dark web link darknet links
onion market tor marketplace
dark web link dark internet
darkmarkets dark market url
tor markets darknet drug links
dark markets 2023 dark website
darkmarket url darkmarket list
buy zithromax online without prescription
dark web site dark web search engine
darkmarkets darkmarket
dark web market list free dark web
dark market 2023 darkmarket
darkmarkets how to get on dark web
dark markets 2023 tor markets
tor market dark markets
deep web drug markets dark markets 2023
deep web search deep web markets
erythromycin 250mg tablet cost
deep web drug links dark web site
retino
drug markets dark web darknet drug links
tor dark web best darknet markets
dark web markets dark web sites
strattera pill generic
synthroid 0.175 mg
deep web drug links dark market onion
blackweb official website dark web site
darkmarket url tor markets 2023
dark web site darknet market list
dark web drug marketplace dark net
levaquin prices
darknet market list dark markets
dark web site black internet
tor marketplace dark net
zithromax cream
tor market url dark markets 2023
dark web sites blackweb
online pharmacy indonesia
darknet drug links deep web drug markets
darknet drug store darkmarket list
darknet search engine how to get on dark web
darknet market lists dark markets
deep dark web tor markets links
deep dark web darknet markets 2023
darknet markets 2023 bitcoin dark web
dark market 2023 darknet market list
darknet drug store dark web websites
tor darknet darknet market lists
dark net tor dark web
lexapro 56 pill
darknet sites dark market link
deep web sites tor marketplace
dark web search engine dark web site
darkmarket url the dark internet
phenergan price uk
deep web links dark web access
darkmarkets darknet market lists
tor markets dark web sites links
dark web market links bitcoin dark web
dark web access dark market link
lasix generic
darknet drugs darknet site
black internet dark web market list
blackweb official website darknet drug links
celexa 30 mg
darknet drugs dark web markets
dark web market list tor market url
dark websites dark website
tor market url dark web links
darkmarket url drug markets dark web
dark web search engines black internet
darkmarket list darkmarket link
deep web drug url tor market links
deep web search dark market link
deep web drug url darknet seiten
dark web access best darknet markets
dark web websites dark web market
darkmarket url dark markets
darkmarket url darkmarket 2023
darknet market list dark web sites
deep dark web deep web drug store
dark web link dark market 2023
dark web link dark web links
dark market url dark websites
blackweb tor market url
albendazole brand name india
darknet links darknet markets
drug markets dark web darkmarket list
how to buy modafinil australia
darknet drugs darknet drugs
tor markets 2023 the dark internet
erythromycin pills
dark markets 2023 dark internet
tor marketplace deep web drug markets
zovirax 200mg tablets price in india
darknet drug links dark market url
darknet links darknet market list
dark web sites links darknet market list
dark net dark web sites
dark internet darknet websites
darkweb marketplace dark market link
lasix 40mg to buy
dark web link darknet market
darkmarket darkmarket
dark web websites tor darknet
tor marketplace darknet drugs
deep web links darknet market links
darkmarket darknet site
darknet drugs dark web websites
deep web drug links dark net
tor markets 2023 tor marketplace
deep web drug markets darknet drug links
dark web drug marketplace darknet marketplace
onion market drug markets dark web
cost for metformin
darknet sites dark market url
dark web access tor markets links
fluoxetine prescription on line
dark websites dark web market
online pharmacy australia
deep web drug markets darkmarkets
darknet market list dark web search engine
best darknet markets dark markets
dark web websites dark market link
darknet drug market dark web markets
darkmarket 2023 drug markets onion
dark internet darknet market lists
modafinil tablet
dark internet darknet market lists
can i buy clonidine over the counter
darknet seiten deep web drug url
deep web drug url best darknet markets
darknet websites darknet websites
discount canadian viagra
tor darknet the dark internet
darknet drugs dark markets 2023
amoxicillin generic 150 mg
bitcoin dark web the dark internet
darknet links dark web markets
darknet seiten deep web drug url
free dark web dark markets 2023
dark web market list dark internet
best darknet markets dark market
tor markets tor market links
deep web drug url best darknet markets
dark websites dark web market
best price propranolol
deep web drug markets darknet links
dark websites dark market 2023
the dark internet black internet
darknet market how to access dark web
how to access dark web tor marketplace
darkmarket list darkmarket
dark web site blackweb
dark markets 2023 darknet market lists
darknet market list deep web sites
mail order pharmacy no prescription
dark web access best darknet markets
darkmarket url blackweb
darknet market lists dark markets 2023
gabapentin 6 cream
dark market link darknet markets 2023
darkweb marketplace dark web market list
tadalafil soft 20 mg
deep web drug links darknet markets 2023
dark web sites best darknet markets
dark web sites tor markets
antabuse uk prescription
dark websites dark web access
vermox 500mg
dark web links dark web drug marketplace
dark web site darknet seiten
dark market black internet
blackweb deep web markets
bitcoin dark web dark web market links
black internet tor dark web
darkmarket 2023 drug markets onion
free dark web dark market onion
deep web sites darkmarket url
black internet deep web markets
zovirax over the counter australia
dark market darkmarket url
darknet drugs dark web sites
dark website dark website
darknet markets darknet market list
darkmarket list dark web search engine
drug markets onion bitcoin dark web
dark web websites darknet markets 2023
tor market links darkmarket url
darkweb marketplace dark internet
deep web links dark market 2023
darknet drug store tor market
tor market links dark markets 2023
tor darknet deep web drug markets
deep web drug markets tor darknet
dark market url dark websites
dark web market dark web links
dark market list tor darknet
best price for advair
deltasone pill
10mg baclofen tablet
deep web markets deep web drug links
tor markets links dark web market links
blackweb official website dark web search engines
dark web site darknet links
tor market darkmarket 2023
robaxin 10mg
darkmarket dark net
tor markets 2023 dark market link
order seroquel online
dark market onion blackweb official website
darknet marketplace darknet marketplace
dark internet dark market onion
dark websites dark markets
atarax medicine 25 mg
dark market 2023 dark website
tor market url darkmarket 2023
how to access dark web deep web drug url
tor market url drug markets onion
tor market links how to get on dark web
darknet site dark web markets
dark market link dark website
deep dark web dark market url
dark web market links darkweb marketplace
dark market dark web market list
deep web drug store tor market url
dark markets darknet sites
darknet markets 2023 darknet drug market
darknet marketplace dark web market links
darknet seiten tor market
tor markets links deep web sites
darknet market darkmarket url
dark web search engine dark web market links
darknet site dark web market
orlistat capsules 120mg
black internet dark internet
darknet site blackweb official website
darkmarkets darknet sites
darknet market links how to get on dark web
cheap trazodone
generic celebrex for sale
darknet markets deep web drug url
darknet search engine darknet search engine
darknet drug links dark net
deep web sites dark web link
bitcoin dark web drug markets dark web
dark market dark market 2023
deep dark web dark market url
levaquin 500 mg levofloxacin antibiotics
propranolol purchase online
dark web market list dark web links
plaquenil 400 mg daily
dark market link tor markets 2023
deep web sites dark net
best darknet markets darkmarkets
dark markets 2023 dark market link
deep web markets dark web market list
dark market onion dark web drug marketplace
tor markets dark web search engines
darknet drug market darkmarket list
blackweb blackweb official website
blackweb tor market links
darkmarket deep web links
deep web drug url dark web sites links
tor darknet dark web market list
blackweb official website deep web drug links
darkmarket url darkmarkets
dark web market onion market
deep web drug markets deep web links
deep web drug store dark web market list
darkweb marketplace how to get on dark web
dark web market list darknet drug market
vardenafil uk
darknet websites dark web access
darknet market dark web search engines
trazodone 50mg capsules
onion market blackweb official website
deep web markets black internet
prednisone 200 mg tablets
robaxin v
darkmarket list darknet markets
tor markets links darkweb marketplace
erythromycin cream otc
dark web market list darkweb marketplace
the dark internet darknet site
buy trental 400
best darknet markets free dark web
how to get on dark web dark market 2023
tor darknet deep web drug markets
darknet market lists darknet drugs
dark web search engines tor market
black internet dark web market
deep dark web free dark web
dark web search engine dark market link
blackweb darknet drug store
metformin 40mg
dark web sites dark market onion
deep web links darknet marketplace
800 gabapentin
10 mg cialis cost
darknet markets dark web site
tor market url blackweb
bitcoin dark web dark web site
deep web markets dark web websites
dark web market free dark web
deep web links dark market link
deep dark web tor markets
darkmarket list darknet drug market
Thank you so much for sharing this excellent web page.
metformin 500mg with out presciption
dark web link dark web link
darknet market lists bitcoin dark web
dark web websites dark net
dark web websites dark website
darknet markets dark web sites
dark web search engine blackweb official website
darkmarkets tor markets 2023
dark market list darknet markets 2023
zovirax online
generic for diflucan
dark web markets deep web drug markets
tor darknet tor marketplace
tor market bitcoin dark web
dark web search engines dark market 2023
darkmarket 2023 darknet site
dark market onion dark market list
dark web market dark market link
darknet sites darknet market lists
darknet drug market how to access dark web
amoxil cost canada
deep web search dark web market links
onion market the dark internet
darkmarkets onion market
buy lyrica mexico
best darknet markets darknet market list
darknet search engine darknet sites
the dark internet tor market links
darknet market list dark website
onion market blackweb official website
dark web search engine tor market links
deep dark web dark websites
erythromycin 500 mg tablets
darknet market lists black internet
tor market links darknet drugs
canadian pharmacy antibiotics
darkmarkets deep web drug url
the dark internet dark web search engines
blackweb official website dark markets
darknet marketplace deep dark web
best darknet markets darkmarket link
darknet search engine darknet drug links
citalopram 10 mg cost
darknet links dark market 2023
dark market list tor darknet
blackweb darknet drug links
free dark web dark net
best darknet markets tor markets links
pharmacy discount coupons
darknet drug market dark web search engine
bitcoin dark web darkmarket 2023
dark market url darknet site
dark net darkmarkets
dark market link the dark internet
tor market url onion market
dark web links deep dark web
dark website darknet markets 2023
dark market url deep web markets
darkmarket url darknet drug store
dark web market dark market onion
deep web drug url tor markets
darknet market lists darknet sites
drug markets onion dark web search engine
tor markets deep web sites
darkmarket 2023 dark market url
tadacip 20 uk
deep web drug url dark internet
the dark internet darknet market lists
deep web drug url darknet markets
deep web drug markets deep dark web
darknet links darknet markets 2023
darknet markets darknet drug links
dark web websites drug markets dark web
generic synthroid online
wellbutrin 300 mg cost
darknet site dark market
dark web search engine dark net
darkmarket list blackweb
darkmarket 2023 darknet seiten
dark website dark web sites links
dark web links darknet markets 2023
glucophage tablet
dark market url tor market
dark internet dark web access
darknet websites best darknet markets
darkmarket list dark net
drug markets onion darknet drugs
darknet market lists dark market list
how to get on dark web darknet drug market
deep dark web deep web drug links
darknet markets dark market list
darkmarket url how to get on dark web
darknet search engine how to get on dark web
deep web drug url darknet drugs
dark web markets darknet drugs
darknet market lists blackweb official website
dark web sites darknet drug store
dark website darkweb marketplace
dark web sites links tor market
darknet market links deep web drug markets
bitcoin dark web darknet sites
prednisolone 3 mg
dark web websites deep web drug links
darknet seiten dark market 2023
darkmarket link tor markets links
synthroid purchase online
darknet marketplace blackweb
prednisone over the counter australia
dark web site darknet market list
darknet market list darknet site
darknet markets dark web search engine
propranolol 160 mg daily
deep web drug url drug markets dark web
deep web sites deep web links
dark markets 2023 drug markets onion
dark market 2023 how to access dark web
blackweb darkmarket
cheap colchicine online
uk pharmacy no prescription
dark market darkmarket url
deep web drug store dark websites
dark web links dark market onion
darkmarket link dark web drug marketplace
dark markets 2023 dark web market list
dark web markets darknet search engine
bitcoin dark web deep web drug links
tor darknet deep web drug markets
darknet drug links darknet markets 2023
darknet markets 2023 dark web search engine
order tadacip 20 mg
blackweb official website tor market url
darkmarket link dark internet
black internet darknet market
deep web search free dark web
tor market bitcoin dark web
darkmarket 2023 tor marketplace
robaxin pills
dark market dark web site
bitcoin dark web darknet market list
dark web link darknet markets 2023
darknet site onion market
dark web market list darkmarket 2023
darkmarkets dark market onion
darknet market links drug markets onion
prednisone 10mg online
deep web links tor marketplace
dark website dark market onion
tor markets links dark web markets
darknet marketplace dark market link
darknet market links dark market url
darknet drugs darkweb marketplace
dark markets 2023 darknet drugs
blackweb dark web markets
deep web search dark market link
dark web drug marketplace deep web drug markets
order tetracycline online
drug markets dark web darkmarket 2023
dark net darknet site
darknet drug market blackweb official website
the dark internet dark web market links
the dark internet dark web link
darkmarket darknet drug links
dark internet free dark web
darknet markets 2023 best darknet markets
darkmarket list deep web drug markets
darknet market list dark market 2023
tor markets 2023 darknet marketplace
025 mg synthroid
deep web drug links darknet search engine
generic cialis where to buy
darknet drug links dark web search engine
tor markets 2023 dark markets 2023
deep web markets dark web markets
tor markets 2023 dark website
dark market deep web search
the dark internet dark web market
dark web market tor dark web
darkmarket 2023 darknet drug market
darknet site darknet links
deep web links deep web drug links
dark web drug marketplace dark web market list
darknet market links darkmarket link
deep web markets dark net
dark web market links tor markets 2023
how to access dark web darkmarkets
synthroid 88
how to get synthroid
dark market link tor market
darknet marketplace deep web drug url
dark web links bitcoin dark web
drug markets dark web drug markets onion
darknet markets 2023 blackweb
darknet market list dark web access
amoxicillin buy online india
darknet markets darkmarket url
tor markets links tor markets 2023
darknet drug links dark markets 2023
darknet drugs drug markets dark web
deep web drug store deep web drug store
dark web market links dark markets
darknet markets 2023 dark market link
dark web access dark web sites
dark web sites links dark web search engines
tor markets 2023 dark web sites links
dark web market list darknet market links
onion market tor dark web
tor markets dark market 2023
darknet market links dark web sites links
usa pharmacy online
darknet site dark market list
drug markets dark web dark web site
tor markets 2023 tor dark web
deep web drug store dark web link
dark market dark web market
medication viagra online
wellbutrin brand name india
tor market how to access dark web
darkmarkets darknet websites
darknet market lists darkmarket url
tor markets links how to access dark web
deep web sites dark market 2023
dark markets 2023 dark websites
tor markets deep web search
deep web drug store darkmarkets
dark web market darkmarket url
darknet search engine dark internet
tor marketplace drug markets onion
darknet search engine how to access dark web
buy diflucan pill
darknet markets 2023 darkmarket link
black internet darknet market lists
darknet markets 2023 tor dark web
how to get on dark web the dark internet
dark markets 2023 deep web drug store
dark market 2023 dark web market links
darknet market lists dark markets 2023
darkmarket link drug markets onion
daily cialis online Among children younger than 5 years of age with nonsevere pneumonia, the frequency of treatment failure was higher in the placebo group than in the amoxicillin group, a difference that did not meet the noninferiority margin for placebo
tor markets links dark market 2023
deep web links dark web market
darknet market lists tor darknet
darknet market lists tor markets
overseas online pharmacy
deep web drug url dark web market links
dark market link dark web sites links
how to get on dark web deep web sites
darkmarket list dark market link
celebrex price south africa
tor marketplace darknet site
tor market darknet markets
dark market link deep web markets
dark website dark market onion
cost of strattera
darknet site drug markets dark web
dark web websites bitcoin dark web
darknet drug links darknet drug market
darknet market list dark web link
dark web drug marketplace deep web search
citalopram 15mg tablet
tor markets links how to access dark web
how to get on dark web darkmarket 2023
deep web drug url darknet seiten
dark web site darknet sites
buy amoxicillin over the counter uk
buy lyrica canada
dark web site deep web drug markets
dark web access blackweb
black internet dark web link
tor markets 2023 tor markets
dark websites darkmarket
drug markets dark web dark web markets
tor darknet dark web market list
darknet seiten darknet websites
darkmarket url drug markets onion
dark web markets deep web links
darknet site tor market links
deep web drug store dark market url
black internet drug markets onion
generic propecia 1mg
dark web drug marketplace darknet market
drug markets onion dark web market links
cheap levaquin
darknet markets darknet market
black internet tor darknet
dark web search engine darkweb marketplace
darkmarket list darkmarket link
darknet markets 2023 tor dark web
darknet search engine dark markets 2023
dark web links darknet links
buy generic accutane uk
darknet search engine tor market
deep web drug links darknet links
darknet websites black internet
darkmarket darknet markets 2023
dark web market deep web search
darknet market links bitcoin dark web
darknet market list dark internet
tor darknet onion market
dark web link darknet site
dark websites dark websites
deep web search darknet search engine
tadacip online canada
dark web search engine tor market links
tor markets 2023 darknet drug store
onion market darknet market
tor darknet drug markets dark web
darkmarket list tor markets
dark web markets darknet markets 2023
deep dark web darknet seiten
the dark internet deep web drug url
dark web link darknet market links
tor markets 2023 tor marketplace
where to order viagra online in canada
dark web websites darknet markets 2023
tor dark web deep web drug url
orlistat 120 drug
darknet marketplace dark websites
dark websites darknet markets 2023
dark websites how to get on dark web
dark web site blackweb
colchicine 0.3 mg daily
darknet drug links dark web search engine
synthroid 115 mcg
buy brand name cialis
dark websites darknet drug links
dark market link free dark web
cymbalta buy online usa
tor markets 2023 tor market links
dark market list deep web search
dark web sites links deep dark web
blackweb darknet site
blackweb darknet search engine
dark web access deep web drug store
where can i get prozac
darknet drug links deep web drug url
dark web market links onion market
dark markets bitcoin dark web
bitcoin dark web tor market links
tor markets dark markets 2023
darknet search engine dark web link
onion market dark website
darkmarket url dark web markets
dark markets dark markets 2023
deep web drug markets darkmarkets
deep web drug url dark web market list
tor market url darknet links
darknet site dark web drug marketplace
lisinopril 20 mg for sale
buy robaxin
dark web access dark web market list
antabuse pills for sale
order fluoxetine hcl 20 mg capsules online
dark internet darkmarket url
dark web access dark web sites links
tor market links deep web search
darknet markets darknet marketplace
vermox mexico
deep web drug links how to access dark web
dark market tor market links
dark web market links deep web search
darknet market dark markets
average cost of generic valtrex
tor market links deep web drug markets
dark markets 2023 darknet sites
onion market darkweb marketplace
blackweb official website deep web links
vermox purchase
darkmarket 2023 darknet market lists
dark web sites tor markets links
tor dark web darkmarket 2023
darknet links deep web sites
tor marketplace tor market links
free dark web darknet market list
valtrex generic otc
darknet seiten darknet websites
deep web drug markets deep dark web
bitcoin dark web darknet markets
dark market 2023 dark markets 2023
deep web sites onion market
darknet sites dark web market
how to access dark web darkmarkets
darkmarket list deep web markets
dark market onion dark web sites
tor markets dark web link
citalopram 80 mg
cheap generic synthroid
dark web site dark web websites
best online pet pharmacy
dark website darkmarkets
tor marketplace bitcoin dark web
black internet dark market onion
blackweb official website how to access dark web
dark market onion dark web site
how to get on dark web dark web access
darknet drug market free dark web
dark market 2023 how to access dark web
dark web market list darknet drugs
cleocin price
dark web access dark market 2023
darknet market list darknet search engine
dark market list tor markets 2023
dark market list tor market
dark web sites links deep web search
darknet search engine best darknet markets
drug markets onion darknet site
dark website tor market url
buy propecia online usa
darknet market lists deep web drug url
dark net tor market links
tor market url dark market onion
robaxin south africa
tor markets 2023 dark website
the dark internet darknet drug store
tor market darknet seiten
deep web links darknet drug market
the dark internet dark web market links
tadacip uk
how to access dark web darkweb marketplace
bupropion hcl 100 mg
darknet site dark website
purchase furosemide online
can i buy vermox over the counter uk
dark markets darknet markets 2023
2700 mg gabapentin
dark web drug marketplace darkmarket
how to get on dark web dark market 2023
dark web search engine tor darknet
dark market url deep web markets
darknet drug market dark web sites links
buy strattera online uk
buy seroquel 25 mg online uk
celebrex generic from india
darkmarkets onion market
darknet search engine deep web drug markets
deep web drug links darknet site
free dark web tor markets links
tor darknet darkweb marketplace
darknet drug store tor dark web
dark web sites links darknet drug store
dark websites dark internet
dark web access deep web drug url
amoxicillin
dark web link dark web sites
darknet market links deep web drug links
dark markets 2023 darkmarket 2023
how to get on dark web tor market url
dark web market list deep web links
how to access dark web drug markets onion
darknet links deep web drug url
darknet market links deep web drug markets
tor marketplace darknet market lists
darknet sites bitcoin dark web
dark website darknet market links
darknet market links dark website
dark web site darknet websites
clindamycin 450 mg cost
tor market url darkmarket
darknet seiten darknet drug market
dark market 2023 darknet market list
darknet drug store dark web websites
darknet market list free dark web
deep dark web tor marketplace
darkmarket best darknet markets
dark market 2023 free dark web
deep dark web tor markets
deep web sites darknet drugs
darknet market links dark net
darknet sites dark net
dark web markets darkmarkets
dark web links dark web drug marketplace
dark web access darkmarket 2023
darknet drugs darknet drug links
darknet drug market tor marketplace
dark market 2023 tor market links
darknet market links dark markets 2023
blackweb dark web websites
dark web link darknet search engine
darknet search engine darknet drug store
how to get on dark web darkmarket list
darknet markets dark web drug marketplace
deep web sites tor markets
dark web drug marketplace deep web drug url
diflucan singapore pharmacy
tor market links dark market onion
darkmarket list dark web sites links
darknet market lists how to access dark web
black internet tor market links
blackweb official website tor markets
tor dark web darkmarket url
dark web markets tor market
dark web access tor market url
dark markets 2023 tor dark web
pharmacy website
augmentin 875 generic price
Дешевые теплицы.
tor market url tor marketplace
tor marketplace dark web access
cafergot uk
tor marketplace deep web drug store
how to get on dark web darkmarket
darknet market list tor market links
black internet drug markets dark web
deep web drug links drug markets onion
darknet site black internet
dark web market links tor market url
dark web market list darknet sites
tor market url deep web markets
tor markets 2023 how to get on dark web
tor markets blackweb
free dark web dark web sites links
dark web access darknet site
dark web sites links dark web site
how to get on dark web how to get on dark web
dark markets dark net
tor markets 2023 darknet site
best darknet markets the dark internet
darkmarket url darkweb marketplace
darknet sites dark websites
generic zithromax
buy trazodone not generic without a prescription
dark web sites links tor marketplace
darknet websites dark web websites
darknet site tor marketplace
how to get on dark web black internet
tor market url darknet links
tor markets 2023 darknet links
darknet markets dark market url
tor markets links dark market url
dark web search engine how to access dark web
dark market url darknet websites
amoxicillin 250mg price in india
deep web search dark web sites links
onion market tor markets links
the dark internet dark market list
colchicine pill buy online
dark web websites dark web drug marketplace
darknet search engine tor market
darkmarket url darknet seiten
darkmarket link deep web drug markets
deep web markets deep web markets
darknet drugs how to access dark web
dark web sites tor market
tor marketplace darknet links
metformin online purchase uk
dark internet darkmarket link
otc lyrica
darkmarket list darknet seiten
dark market url dark websites
dark web links darknet drug links
phenergan 5mg
dark net drug markets dark web
dark market 2023 deep web drug links
dark web market darknet sites
darknet site dark web search engine
deep dark web darknet market links
robaxin 750 coupon
darknet links darkmarket link
dark web sites links deep web drug store
drug markets onion deep web markets
darknet drug store deep web drug url
dark market list dark web site
darknet drug market darknet drug store
dark market onion tor darknet
drug markets dark web darknet market list
dark market dark market link
dark web access darkmarket link
free dark web darknet drug store
dark web market links tor darknet
dark web drug marketplace dark web market links
how to get on dark web deep web links
darkmarket 2023 bitcoin dark web
darknet markets blackweb
darkmarket link dark web links
tor market dark market onion
deep dark web darknet drug store
legit online pharmacy
darknet drug store dark web site
how to get on dark web darkmarket url
darkmarkets deep web drug store
darknet markets 2023 free dark web
darknet drug store how to get on dark web
darknet drugs darknet market lists
blackweb official website black internet
lipitor 80
blackweb official website dark websites
blackweb darknet sites
tor markets drug markets dark web
tor dark web dark web markets
darkmarket 2023 deep web drug url
blackweb official website deep web drug store
dark market url deep web links
dark websites dark internet
darknet market list darkmarket 2023
darknet markets tor markets
darkmarket 2023 deep web drug url
how to get on dark web the dark internet
darkweb marketplace dark internet
dark web markets darknet drug links
dark web market list darknet market lists
dark web search engine darknet sites
dark net dark web market links
buy tadacip canada
dark web market list blackweb
best online foreign pharmacies
darkmarket deep web drug url
dark website how to get on dark web
albenza otc
dark web access black internet
tor market the dark internet
deep web links deep web links
dark web access deep web search
the dark internet darknet drug store
dark web market list tor marketplace
dark websites tor markets links
darknet site tor dark web
dark web access deep web markets
bitcoin dark web dark web link
darkmarket list dark net
deep web drug url darknet markets 2023
darknet market dark web drug marketplace
blackweb dark websites
dark market 2023 dark web websites
cost of zithromax
darkmarket url dark market onion
dark web websites deep dark web
dark web link dark web market links
darknet markets 2023 dark web sites links
dark market darknet sites
how to access dark web deep web drug store
dark web search engines deep web search
dark web websites tor market
cheap lioresal
generic strattera india
tor markets 2023 dark web markets
dark web sites dark market 2023
dark web search engine dark website
darknet drugs deep web links
darkmarket tor markets
deep web links deep web markets
dark websites tor market url
darkmarkets dark markets 2023
dark market list darknet drug links
prednisolone cost
darkmarket list onion market
darknet drug store darknet seiten
darknet market lists dark market url
clonidine from canada
darknet markets dark web site
dark web sites darknet market
darknet marketplace darknet links
darknet marketplace deep web drug links
the dark internet dark web search engines
bitcoin dark web darknet site
best darknet markets dark web links
deep web search deep web search
free dark web deep web drug store
valtrex online pharmacy
dark web access darknet drugs
dark web sites links darkmarket link
the dark internet darknet site
cafergot tablets buy online
synthroid pharmacy coupon
blackweb official website deep web markets
deep web links darknet markets 2023
how to access dark web dark market
tor marketplace blackweb
atarax 25 mg capsule
darknet sites dark markets
dark market dark web sites
deep web drug links dark web websites
dark web markets dark web market links
dark market list dark web search engine
darkmarket link deep web drug links
tor market url darknet websites
darkmarkets dark web links
best darknet markets blackweb official website
darkmarket url dark web link
darknet links tor dark web
dark web market deep dark web
dark market list dark market onion
darknet drug market deep web drug url
dark web site darknet site
price of strattera
deep web drug url darknet site
tor market links deep web links
deep web links darknet market list
deep web drug markets darknet market links
tor darknet dark web search engines
trazodone capsules 100mg
dark web access deep web drug url
deep web drug store dark market 2023
darkmarkets tor market url
deep dark web darkmarket 2023
tor market links dark web access
darkmarket list dark market list
onion market dark web access
dark market 2023 tor markets
darknet markets 2023 dark web markets
diflucan 75 mg
neurontin 300 mg tablets
deep web drug url dark market 2023
canada pharmacy 24h
dark web market list darknet site
blackweb dark web drug marketplace
dark web access tor marketplace
deep dark web dark market 2023
tor market darknet market
tor market links tor darknet
dark website darknet search engine
dark market link dark market 2023
tor markets links dark market
darkweb marketplace drug markets dark web
darknet markets 2023 darkmarket link
levitra 10mg e-medications.com
dark web drug marketplace tor market
dark market tor darknet
dark market list tor market url
darknet drug store tor market links
tor markets 2023 darknet markets
tor dark web dark web site
darkmarket link darknet seiten
darknet markets 2023 tor market
the dark internet darkmarket url
deep web drug links deep web drug url
darknet markets 2023 darknet marketplace
dark web access black internet
darkmarket darknet markets
dark market onion drug markets onion
acyclovir 400mg tablet no prescription
darknet drugs dark web sites links
darknet market links dark web websites
how to get on dark web dark web search engines
dark web link tor markets
darknet drug store dark market
darknet websites tor markets 2023
dark market list tor darknet
dark web site dark web websites
tor marketplace dark market list
darknet market dark web drug marketplace
dark web links tor darknet
deep web drug url darknet drug store
darknet sites deep dark web
where to buy vermox
darkmarkets free dark web
darkmarkets onion market
black internet dark market url
deep web markets darkmarket list
dark web link deep web drug links
deep web search dark net
dark web drug marketplace darkmarket list
dark web access dark web access
deep web search deep web drug markets
darknet drug market darknet drug market
dark web access darknet search engine
the dark internet dark web links
dark web search engine deep web drug markets
dark market 2023 deep dark web
buy robaxin canada
blackweb official website dark web drug marketplace
dark web sites darkweb marketplace
deep web sites darknet market
drug markets dark web darknet seiten
dark web search engines dark market link
buy augmentin online no prescription
valtrex over the counter uk
metformin without script in usa
deep dark web darknet market list
deep web drug store dark website
deep web markets deep web drug links
dark website how to get on dark web
darkmarket dark markets 2023
dark web market dark web market links
darknet market links darknet links
dark web drug marketplace tor markets
darknet market lists deep web links
onion market dark markets 2023
the dark internet dark web search engine
darknet drug market deep dark web
dark internet drug markets onion
dark web link darknet links
darknet marketplace dark web drug marketplace
darkmarket list dark web market links
dark web links blackweb official website
darknet sites deep web drug store
dark internet darknet markets
darknet websites darknet websites
free dark web dark web links
darkmarket 2023 darknet drug store
darknet drugs deep web drug markets
amoxicillin 500 mg tablet price in india
darknet seiten black internet
synthroid 150 mcg price
darkmarkets dark web link
deep web drug links bitcoin dark web
darknet links dark web websites
deep web links deep web search
darknet marketplace tor darknet
dark market onion bitcoin dark web
dark web drug marketplace deep web drug store
dark web search engine darknet drugs
deep dark web how to get on dark web
dark net darknet site
tor markets 2023 dark web site
drug markets dark web dark web search engine
dark web links darknet marketplace
darkmarkets bitcoin dark web
blackweb official website darknet sites
dark website deep web links
onion market darkmarket url
onion market dark website
tor markets 2023 tor markets 2023
darknet drugs deep web markets
dark market link darknet sites
dark web search engine deep web links
onion market tor markets
darknet market lists darkmarket
amoxil capsules 500mg
dark internet dark markets 2023
advair diskus 160 90 mcg
dark market tor markets links
darknet site dark web markets
deep web links dark net
darknet market drug markets onion
where can i buy diflucan without a prescription
tor marketplace tor market
darknet market links darknet markets 2023
dark web search engine tor market url
dark web link tor darknet
darknet seiten deep web links
deep web sites how to access dark web
ampicillin 5g
darkmarket list dark market
darknet seiten drug markets onion
albendazole nz
darknet market lists deep dark web
how to get on dark web darknet drug market
deep web drug store onion market
acyclovir buy online canada
darkmarket list darknet market list
darknet markets 2023 tor marketplace
cheap lexapro 20 mg
tor dark web darkmarket 2023
deep web drug links dark web links
bitcoin dark web dark web sites
darknet seiten darknet site
dark web markets darknet markets 2023
how to get on dark web darkmarkets
darknet drug links dark market 2023
onion market dark net
darknet markets 2023 darknet markets
dark web sites links drug markets dark web
dark web site dark web market list
darkmarket link dark web market list
how to get on dark web free dark web
dark website dark web links
blackweb dark net
dark web markets deep web drug markets
dark websites tor market url
dark web market links darknet market lists
tor market links tor market
darknet site darkmarket
dark web market dark market
darknet websites dark web markets
dark web search engine tor marketplace
tor dark web dark web market list
how to get on dark web tor darknet
albendazole otc canada
tor markets 2023 dark web sites
4 mg abilify
propecia generic australia
how to access dark web deep web markets
deep web sites dark net
darknet market links dark web links
dark web access tor markets links
blackweb official website dark market list
dark markets 2023 darkweb marketplace
dark websites dark web links
free dark web drug markets onion
deep web drug url dark web market
dark web search engines deep web links
darkmarkets dark market onion
how to access dark web dark market link
tor marketplace tor dark web
dark market list dark market
darknet sites drug markets dark web
how to get on dark web dark market link
free dark web darkmarket list
dark web market dark market onion
albendazole 400 mg cost
darkmarket list bitcoin dark web
darknet drug links darknet markets 2023
dark market list best darknet markets
dark web sites dark market url
dark web search engine dark website
darkmarket deep web search
free dark web dark web sites links
darknet market lists dark markets
hydroxychloroquine 4 mg
dark market url darknet market
dark web search engines tor market links
where to buy strattera in canada
dark internet darknet drug market
darkmarket dark market
darknet site dark web search engine
celebrex 60 mg
real cialis prices
darknet market list best darknet markets
free dark web dark web websites
black internet tor markets
strattera 18 mg price
how to access dark web dark web sites links
buy strattera online pharmacy
dark market list deep web drug url
tor market url dark web drug marketplace
dark web sites links tor markets
darknet market list dark web site
deep web search dark net
dark web search engine dark website
tor market bitcoin dark web
tor dark web free dark web
darknet drug store darknet seiten
bitcoin dark web darkweb marketplace
dipyridamole 200 mg
dark market url darknet market lists
darkmarkets darknet seiten
cheap acyclovir online
deep web drug store tor marketplace
generic albenza cost
darknet market lists darknet seiten
dark web market list darkmarket link
dark internet dark web market links
fluconazole buy online without prescription
darknet seiten deep web drug markets
buy online pharmacy uk
darkmarket 2023 black internet
dark web sites best darknet markets
blackweb darknet search engine
darknet sites darknet links
dark web links onion market
dark market onion dark market list
celebrex.com
dark web link dark markets 2023
tor darknet dark net
how to buy finasteride
lexapro 40 mg daily
hydroxychloroquine 700 mg
dark web market links darknet links
dark market free dark web
tor markets links tor darknet
tor markets links dark markets 2023
baclofen drug
tor marketplace dark web sites
deep web drug markets darknet marketplace
order buspar no prescription
darknet drug market dark web drug marketplace
daily baclofen
how to access dark web tor markets links
dark web market dark web access
can you diflucan over the counter
where can i get acyclovir over the counter
generic levaquin
baclofen online
buy buspar no prescription
tadacip usa
albendazole 2g
buy lexapro brand name online
dipyridamole 200 mg
darknet markets darknet market links
avodart 1mg
drug markets onion dark web access
propecia how to buy
dark web links darknet site
acyclovir tablet
baclofen over the counter usa
buy avodart online uk
buy laxis with mastercard
dark markets 2023 best darknet markets
blackweb official website dark web links
dark web markets black internet
celebrex capsule 100mg
best darknet markets how to get on dark web
lexapro celexa
dipyridamole aspirin
dark market list dark web site
plaquenil skin rash
can i buy lexapro medicine online
dipyridamole 75 mg
darknet search engine darknet markets
celebrex prices
medicine lexapro
baclofen 2018
albendazole buy
celebrex without prescription
diflucan 200 mg price south africa
buspar discount
darknet market links darknet drug store
darkmarkets tor market links
deep web drug url drug markets onion
deep web links darkmarket url
dark market url darknet markets
dark web site darknet drug links
tor darknet darknet market list
dipyridamole 50 mg
dark market url darknet marketplace
generic anafranil cost
tor markets 2023 darkmarket 2023
deep web search blackweb official website
dark web search engine tor market links
dark web markets dark web drug marketplace
deep dark web darknet websites
blackweb darknet websites
dark market darknet seiten
darknet market lists tor market url
darknet websites darknet marketplace
esfrhmajh kccom llixmfn ksuf nfawkqvkyolmcne
avodart capsules 0.5 mg
atarax 10mg prescription
dark websites tor market url
drug markets dark web darknet site
dark web search engines dark web drug marketplace
dark web search engine best darknet markets
ampicillin medication
tor market links dark market list
dark web sites links dark market
drug markets onion dark website
dark web search engines dark web link
darknet market lists dark web search engines
tor market url darkmarket list
tor dark web drug markets dark web
how to access dark web tor marketplace
tor dark web darknet markets 2023
how to get on dark web darknet links
dark web market list darknet markets 2023
onion market dark web link
darknet drug store dark web market links
abilify 5mg tablet price
90 mg abilify
deep dark web dark web drug marketplace
darkmarket url darkmarket list
darknet sites darknet websites
tor marketplace dark web search engines
darknet drug links darknet search engine
tor marketplace best darknet markets
deep web links deep dark web
free dark web dark web sites links
strattera 10 mg coupon
atarax otc usa
dark web sites links darknet websites
dark market 2023 dark web search engine
darknet drug store darknet market links
tor market url darknet markets 2023
drug markets onion tor market url
dark web link deep web drug markets
darknet drug links dark web markets
dipyridamole brand name australia
dark web market list darknet search engine
tor markets 2023 darknet links
tor darknet dark web drug marketplace
diflucan generic brand
cialis cost in mexico
darknet market onion market
darkmarket 2023 darknet drug links
tor markets 2023 darknet websites
dark market url dark web sites
dark web site deep web drug url
darknet drug market deep web search
deep web links drug markets dark web
darknet market lists darknet drug links
dark web sites dark web websites
36048 197077extremely nice post, i definitely enjoy this fabulous internet site, persist with it 348991
tor dark web darkweb marketplace
dark market darknet markets 2023
blackweb tor market
dark market 2023 deep web sites
darkmarket url dark web search engine
dark web drug marketplace tor markets
dark web sites links dark web market
drug markets onion darkmarket url
dark market list dark web market links
tor marketplace dark web links
black internet deep web drug markets
tor market url dark web link
darknet marketplace dark websites
dark markets deep web drug url
blackweb official website tor market links
blackweb dark web site
blackweb dark web site
dark websites dark web market
darknet site tor darknet
deep web sites darknet markets
how to get on dark web black internet
tor markets black internet
best price lexapro 20 mg
tor markets best darknet markets
onion market darkmarket link
darknet sites drug markets dark web
darknet market lists darknet markets 2023
darknet drugs darknet sites
darkmarket link tor market url
drug markets onion darknet sites
darkmarket 2023 darknet websites
darknet site dark web markets
darknet links darknet market lists
the dark internet drug markets dark web
tor darknet darknet markets 2023
darknet market list black internet
dark market url blackweb official website
dark web sites links bitcoin dark web
darknet marketplace how to get on dark web
dark market link dark net
dark website darknet seiten
darkmarket dark web markets
dark web search engines dark markets 2023
deep web sites dark market link
buy avodart online uk
buspar for sale
darknet drug store darkmarket list
buy cheap synthroid
celebrex canada prices
darknet search engine dark web link
darkweb marketplace tor markets
blackweb dark website
darknet markets 2023 dark market url
dark web links tor markets links
dark web sites links dark web market list
acyclovir pills over the counter
tor marketplace darkmarket url
darkmarket 2023 dark web link
darknet drugs onion market
dark market 2023 the dark internet
darknet drug links dark web links
darkmarket link deep web drug url
deep web search darknet market lists
deep dark web darknet links
25 mg anafranil online
dark market list drug markets onion
darknet market list tor marketplace
how to get on dark web darkmarket url
darknet markets tor marketplace
avodart for sale online
dark web access dark web link
dark market link dark internet
generic tadalafil from uk
darknet site deep web search
darknet drugs dark market onion
onion market deep web drug markets
darknet drugs dark web search engines
dark web market links drug markets dark web
dark web link the dark internet
dark web market links darknet links
darkmarket 2023 darkmarket
darkmarket list deep web drug store
dark web links deep web markets
albendazole tablets online
darknet drug store dark market 2023
darkmarket link tor darknet
tor market onion market
darkmarket 2023 tor markets
dark web drug marketplace dark market
dark web market links dark web market list
darknet websites blackweb
darknet drugs dark web drug marketplace
dark market list dark web markets
dark internet dark web market
dark web sites dark web access
dark web search engine darknet drugs
strattera 18 mg
darknet market lists darknet websites
best darknet markets dark market url
dark web search engines dark internet
tor market url black internet
darknet drug market dark web market list
tor market links how to access dark web
deep web drug store deep dark web
dark market url dark web sites
deep web drug store blackweb official website
deep web links drug markets onion
dark markets 2023 dark websites
free dark web darkmarkets
I may need your help. I tried many ways but couldn’t solve it, but after reading your article, I think you have a way to help me. I’m looking forward for your reply. Thanks.
colchicine 500 mcg tab
cheap albenza
darknet market links deep web drug links
dark web market tor darknet
how to get on dark web darknet marketplace
tor darknet dark web sites
tor darknet deep web drug url
dark web search engines darknet market
dark market url dark market url
dark web search engines dark market
cost of citalopram 40 mg uk
tor marketplace deep web drug markets
dark web drug marketplace darknet sites
dark web links deep dark web
dark web site dark market onion
darkmarket darknet drug store
darknet market dark websites
blackweb official website dark website
buy furosemide 40 mg tablets uk
cialis buy Hindmarch I, Johnson S, Meadows R, Kirkpatrick T, Shamsi Z
dark web market list dark web sites links
tor markets links drug markets onion
baclofen brand
dark web access tor markets 2023
darkmarket list tor markets links
darknet drug market darkmarket 2023
blackweb darkmarkets
acyclovir canada prescription
tor darknet dark web site
dark website darknet links
darknet market links darknet market links
darknet market list deep web search
dark web sites darkmarkets
dark web sites blackweb
darkmarkets darknet sites
dark web market list dark market onion
cost of cipralex daily
dark websites deep web drug links
black internet dark web drug marketplace
tor marketplace drug markets onion
darknet market deep web search
darknet market list dark web market links
darknet links tor markets links
blackweb darknet drug store
propecia 1mg tabs
darkmarket url deep dark web
darknet drug market dark web sites links
blackweb dark market url
dark market onion tor darknet
anafranil online
dark market list tor market
dark website darknet markets
deep web drug store darknet drug store
darknet search engine free dark web
black internet darkmarkets
dark internet dark web market
dark web markets tor market
darknet drug store deep web drug url
tadacip cipla
deep web drug markets dark web search engines
diflucan 100 mg tablet
dark web market links darknet market list
baclofen buy
darknet drug market dark market 2023
dark net darkweb marketplace
buy generic buspar price
darknet websites dark market list
tor marketplace blackweb
dark market 2023 darknet markets 2023
colchicine online canada
darknet sites darkmarket 2023
deep web markets drug markets dark web
darkmarket 2023 dark websites
deep web sites darknet market list
dark markets dark web market list
darknet seiten tor marketplace
dark net dark web markets
dark market link dark web site
dark web market deep web links
dark web search engines dark web search engine
avodart 500mg
dark web site darknet market list
dark market url best darknet markets
dark web market links darknet drugs
black internet free dark web
dark web links darknet markets
where can i buy acyclovir over the counter
darknet drugs black internet
abilify
tor darknet dark web access
tor markets links darknet market lists
dark market dark web link
buy anafranil online australia
drug markets dark web tor darknet
free dark web dark market list
dark web sites links darknet links
best darknet markets dark web websites
dark web link dark web drug marketplace
darknet site dark market url
darknet drug market darkmarket 2023
tor market dark markets
blackweb dark markets 2023
darknet markets tor market links
darkmarket 2023 bitcoin dark web
the dark internet bitcoin dark web
darkmarket list dark market
darkweb marketplace dark web search engines
dark web sites tor markets links
darknet sites darkmarket url
free dark web darknet marketplace
dark web search engine deep dark web
darkmarket url darkmarket link
blackweb dark market
dark market dark web sites links
dark web websites darknet sites
dark market url how to access dark web
tor market url tor marketplace
dark web search engine dark web market links
onion market dark web link
bitcoin dark web drug markets dark web
tadacip 20 mg uk
darknet drug store darkweb marketplace
generic clopidogrel cost
tor markets links deep web markets
dark market onion how to get on dark web
dark internet blackweb official website
onion market dark web link
darknet seiten darkmarket url
tor market darknet seiten
darkmarket darknet sites
dark market 2023 drug markets dark web
dark web links drug markets dark web
tor market links darkweb marketplace
tor darknet dark market onion
darkweb marketplace darknet drug links
deep web drug url darknet drugs
dark web link tor marketplace
citalopram online
darknet market deep dark web
dark internet dark markets 2023
deep web drug store darknet drugs
kamagra paypal
how much is nolvadex in australia
best darknet markets dark market
buy xenical nz
dark web websites how to access dark web
tor markets darknet seiten
dark web access dark internet
darknet sites deep web drug markets
dark web access dark web market
phenergan australia prescription
deep web drug url darkmarket 2023
how to access dark web deep web drug markets
blackweb dark web websites
darknet drug market best darknet markets
tor market tor marketplace
darkmarket url tor markets links
dark web search engines how to get on dark web
dark market dark websites
drug markets dark web free dark web
fluconazole diflucan
darknet drug links free dark web
dark web market links dark web sites links
anafranil 25mg capsules
dark market onion darknet market lists
deep web drug markets dark market 2023
darknet drug store dark market list
dark web sites links tor market
tadacip 20 mg price
terramycin australia
darkmarket list dark web site
deep web drug links dark web market list
dark websites the dark internet
tamoxifen 10 mg tablet price
synthroid 125 mcg cost
dark market onion dark web sites
atarax price
avodart 50mg
bitcoin dark web dark net
deep web drug markets deep web search
darkmarket 2023 deep web drug url
tor markets dark market onion
deep dark web tor dark web
dark markets best darknet markets
dark market 2023 dark market 2023
darknet drugs darkmarket url
robaxin 750 pill
deep web drug store darkweb marketplace
deep web sites darkweb marketplace
darknet market lists the dark internet
darknet market list deep web sites
dark web drug marketplace darknet market links
deep web drug markets dark websites
dark web site how to get on dark web
bitcoin dark web dark web markets
darkmarket link deep web drug links
dark web links bitcoin dark web
trental tablet cost
darknet market links tor market links
blackweb dark web sites links
tor market url darkmarket 2023
dark web search engine darkweb marketplace
dark web sites dark market 2023
tor markets 2023 darkweb marketplace
kamagra oral jelly australia paypal
onion market deep web sites
deep web drug url deep web sites
deep web links blackweb official website
the dark internet dark web market list
deep web sites darkweb marketplace
tor marketplace darkmarket 2023
darknet websites deep dark web
deep web sites darknet market lists
onion market dark web websites
deep web search darkmarket url
dark web sites dark web markets
darknet drug store dark websites
deep web links dark websites
dark net blackweb
dark market list dark market url
deep web markets dark web site
darknet drugs tor market url
buspirone 5 mg
darknet marketplace darknet drug market
celebrex 50 mg
medrol tabs
free dark web how to get on dark web
dark net best darknet markets
tor markets links darknet market
darknet websites darknet markets
darknet websites tor darknet
dark web links blackweb
deep web drug store darkmarket 2023
dark web links darkmarket link
tor marketplace dark net
dark markets 2023 tor marketplace
darkmarkets dark web search engines
how to access dark web darkmarket
darknet drug market darknet drug links
trental price
deep web drug url dark websites
darkweb marketplace tor markets 2023
darknet drugs dark market link
singulair generic drugs
dark web site dark web search engine
dark market url dark web drug marketplace
darknet drug links dark web site
deep dark web best darknet markets
tor market links how to access dark web
trental coupon
dark market link deep web drug markets
clopidogrel 75 price
dark market url darknet marketplace
dark market url dark web site
dark market url dark internet
darknet markets deep web drug url
dark web sites deep web links
dark web websites tor market
darknet market lists dark web sites links
darknet market dark market link
best darknet markets tor markets
black internet darknet drugs
darknet site darknet drugs
dark website dark web drug marketplace
dark web websites dark web search engines
where can i buy xenical online
dark website dark web market
how to get on dark web darknet market lists
darknet seiten dark web websites
dark web link dark web market
how to access dark web darknet market links
celebrex tablet 200mg
darkmarket 2023 dark web market
dark web markets darknet drug market
darkmarket dark web sites links
free dark web darkmarket list
darkmarkets bitcoin dark web
darknet market darknet drugs
deep web drug markets darkmarket list
deep web drug store darknet markets
tor markets 2023 tor darknet
onion market dark web sites links
darknet search engine deep web search
tor marketplace darknet sites
darkmarket 2023 darknet markets 2023
dark web market darknet markets 2023
how to get on dark web dark web access
darkmarkets tor market
darknet search engine tor dark web
darknet drug store deep web sites
brand name phenergan
deep web drug markets dark market link
darknet market darknet links
tetracycline brand name
plavix rx
free dark web tor market
propecia cost nz
tor markets 2023 tor marketplace
dark market list tor markets links
tor dark web darknet market
dark market black internet
darknet search engine dark websites
deep web drug links dark markets
dark market onion dark market
dark web market list dark web access
deep web search darknet markets 2023
darknet websites deep web search
blackweb official website blackweb
dark web sites links darknet market
darkmarket link darknet sites
motilium otc australia
darknet market dark market 2023
suhagra 100
dark web drug marketplace darknet market list
darkmarket list the dark internet
elimite cream coupon
darknet links drug markets dark web
cost of zofran 4 mg
dark web search engine tor market url
deep web drug markets dark markets 2023
clopidogrel otc
deep web drug store tor markets
how to access dark web bitcoin dark web
blackweb deep web search
tor markets deep web sites
dark web link dark web market
darknet site dark web link
motilium cvs
the dark internet how to get on dark web
dark market link darknet drug store
motilium price in india
dark web search engines dark web markets
darknet drug links dark markets 2023
darkmarkets dark website
darknet links darknet links
darknet market list https://heineken-drugs-market.com/ deep dark web
tor darknet https://heineken-onlinedrugs.com/ blackweb
dark market 2023 https://heinekendrugsonline.com/ darknet drug store
darknet market list best darknet markets
tor markets 2023 https://heinekenoniondarkmarket.com/ dark web access
dark web link https://darkmarket-world.com/ bitcoin dark web
the dark internet https://world-onion-darkmarket.com/ darknet market lists
generic plavix canada
tor marketplace https://heineken-onion-market.com/ dark web site
dark internet https://worldmarketdrugsonline.com/ dark markets
darknet drug links https://worldmarketplace24.com/ dark net
dark markets https://heinekendrugsmarketplace.com/ tor markets links
darknet drug market https://world-drugs-market.com/ dark net
darknet drug market https://darkwebworldmarket.com/ darkmarket 2023
dark web websites https://world-onlinedrugs.com/ darknet market
darknet sites https://cypherdarkmarketonline.com/ darknet sites
blackweb official website https://darkmarket-cypher.com/ deep web search
tor markets 2023 https://darkweb-world.com/ deep web drug store
phenergan 2 cream
darkweb marketplace https://dark-market-heineken.com/ dark web market links
dark web search engine https://worldmarketplacee.com/ tor markets
dark market link https://world-darkmarketplace.com/ darkmarket 2023
dark web links https://cypher-market-onion.com/ blackweb official website
suhagra 50 tablet
dark markets https://worldmarket-url.com/ darknet sites
how to get on dark web https://kingdom-darkmarket.com/ darknet search engine
dark web link https://cyphermarket-url.com/ tor market links
deep web drug store https://world-darkweb.com/ black internet
darkweb marketplace https://heinekendarknetdrugstore.com/ deep web drug store
deep web links https://heineken-darknet-drugstore.com/ dark market link
darkmarket url https://worlddarkmarketonline.com/ dark market link
how to access dark web https://heinekenonionmarket.com/ the dark internet
deep web drug store https://worldonionmarket.com/ deep web drug url
darknet markets https://cypher-market-online.com/ darknet market links
darknet market list https://world-onion-darkweb.com/ darknet market lists
darknet market list https://heineken-drugsonline.com/ deep web markets
dark market list https://world-darknet-drugstore.com/ the dark internet
drug markets dark web https://heineken-onlinedrugs.com/ darknet sites
deep dark web https://heinekenonlinedrugs.com/ darkmarket list
xenical 120 mg online
dark websites https://worldoniondarkmarket.com/ tor markets
how to get on dark web https://dark-web-world.com/ darknet site
deep web drug links https://heinekenoniondarkmarket.com/ bitcoin dark web
onion market https://heineken-onion-market.com/ tor marketplace
darkmarket 2023 https://world-market-place1.com/ deep web sites
free dark web https://cypherdarknet.com/ tor markets
blackweb official website https://world-onion-darkmarket.com/ dark web search engines
darknet market list https://cypher-dark-market.com/ tor dark web
bitcoin dark web https://world-drugsonline.com/ dark web websites
dark web sites links https://heinekendrugsmarket.com/ deep web drug markets
elimite coupon
darknet sites https://cypher-darkwebmarket.com/ dark web search engine
darknet drug market https://darkmarketworld.com/ dark web markets
tor marketplace https://cypherdrugsmarket.com/ dark web websites
dark web links https://cypherdarkwebmarket.com/ deep web drug url
drug markets onion https://dark-market-world.com/ dark web markets
deep dark web https://world-onlinedrugs.com/ darknet drug market
dark market https://world-darkmarketplace.com/ darknet markets 2023
dark market https://heineken-darkweb-drugstore.com/ the dark internet
dark web sites links https://kingdom-darkmarket.com/ deep web links
dark web access https://cyphermarket-darknet.com/ dark web drug marketplace
deep web search https://dark-market-heineken.com/ darknet marketplace
buy trental 400 mg
darknet links https://worlddarkweb.com/ tor dark web
dark web drug marketplace https://cyphermarket-link.com/ best darknet markets
colchicine 0.6 mg without prescription
cost of gabapentin 600 mg
darknet market https://heinekendarknetdrugstore.com/ dark web market list
dark internet https://worlddarknetdrugstore.com/ darkmarket
dark market list https://worlddarkmarketonline.com/ darknet seiten
darknet links https://heineken-online-drugs.com/ darknet markets
drug markets onion https://world-online-drugs.com/ tor darknet
darknet websites https://world-darknet-drugstore.com/ dark web sites
dark website https://darkweb-cypher.com/ darkmarket url
tadacip 20 mg price
tor markets 2023 https://darkmarket-world.com/ free dark web
bitcoin dark web https://heineken-drugsonline.com/ dark markets 2023
dark markets 2023 https://heineken-drugs-online.com/ darknet marketplace
darknet market links https://worldoniondarkweb.com/ darknet market list
darknet market lists https://heinekenoniondarkmarket.com/ deep web drug links
dark internet https://heinekenonlinedrugs.com/ best darknet markets
darknet search engine https://cypherdarknet.com/ darknet marketplace
tetracycline 250mg
tor dark web https://world-market-place1.com/ darkmarkets
buy tamoxifen canada
dark web websites https://heineken-onion-darkmarket.com/ blackweb official website
blackweb https://cypher-dark-market.com/ dark market link
darknet site https://world-drugsonline.com/ dark websites
darknet drugs https://cypher-drugs-market.com/ darknet seiten
blackweb https://cypher-darkmarket.com/ dark net
dark web sites https://cypher-onlinedrugs.com/ dark web sites
buy kamagra jelly uk
dark market link https://cypher-darknet.com/ dark web search engine
dark web links https://darkwebworldmarket.com/ deep web drug links
how to get on dark web https://heinekendrugsmarketplace.com/ dark web markets
dark market url https://kingdomdarkwebmarket.com/ dark web market list
dark web access https://worldmarket-linkk.com/ free dark web
darknet drug store https://worldmarket-darknet.com/ darknet market list
deep dark web https://world-darkwebmarket.com/ tor marketplace
tor darknet https://heineken-darkweb-drugstore.com/ deep web drug url
bitcoin dark web https://darkweb-world.com/ bitcoin dark web
darknet market list https://world-drugs-online.com/ dark web drug marketplace
darkmarket url https://worlddarkweb.com/ black internet
darkmarket link https://cyphermarket-darknet.com/ darknet drugs
xenical for sale south africa
darknet marketplace https://dark-market-heineken.com/ darknet market lists
darknet market https://cypher-marketplace.com/ black internet
darknet market lists https://cyphermarket-link.com/ darknet site
dark web search engines https://heinekendarknetdrugstore.com/ darkmarket link
plavix generic price comparison
darknet markets 2023 https://worlddarkmarketonline.com/ darknet drug store
albendazole order online
darknet site https://cyphermarketplacee.com/ darknet markets 2023
dark web drug marketplace https://world-darknet-drugstore.com/ dark websites
deep web markets https://heinekenonionmarket.com/ dark market onion
buy singulair 10mg
tor markets links https://world-online-drugs.com/ darknet sites
dark net https://darkmarket-world.com/ dark market 2023
dark web link https://worldmarketdrugsonline.com/ dark market list
price of singulair
darknet marketplace https://dark-web-cypher.com/ darknet market links
motilium drug
dark website https://cypher-darkweb.com/ darknet sites
drug markets onion https://worldoniondarkweb.com/ dark web access
dark web access https://heinekenoniondarkweb.com/ darknet market links
dark market https://cypher-darkmarketplace.com/ tor markets links
dark website https://heineken-drugsonline.com/ best darknet markets
order medrol online
darkweb marketplace https://worldmarketplace24.com/ dark web search engines
darknet sites https://cypherdarkmarketx.com/ darknet websites
dark market https://heineken-drugs-online.com/ darknet drugs
black internet https://heineken-onion-market.com/ bitcoin dark web
dark market link https://cypher-drugsonline.com/ dark market onion
darkmarket link https://cypherdarkwebmarket.com/ darknet drug market
tor market https://world-darkmarketplace.com/ dark web links
deep web drug markets https://worldmarket-linkk.com/ dark web market links
dark web links https://world-darkmarket.com/ how to get on dark web
drug markets dark web https://darkmarketworld.com/ darknet market list
dark markets 2023 https://cypheronionmarket.com/ dark web links
darknet site https://dark-market-world.com/ darknet market
dark websites https://world-dark-market.com/ dark web market
tor market links https://worlddarkweb.com/ deep web drug markets
darkmarket link https://worldmarketplacee.com/ deep web links
deep dark web https://heinekendrugsmarket.com/ darknet drugs
darknet drug store https://world-drugs-online.com/ dark websites
dark web link https://worlddarknetdrugstore.com/ blackweb official website
dark markets https://cypher-market-onion.com/ dark net
darkmarkets https://cypherdrugsmarket.com/ deep web drug links
Good article. Keep writing! Is the Amazon app keeps on crashing and rendering you with Amazon CS11 Error code alert? If so, you are at the right place to buzz off the error. Just visit the given site to Fix Amazon CS11 Error Code on your iPhone.
yasmin 22
dark web search engine https://heineken-darknet-drugstore.com/ tor darknet
free dark web https://cyphermarket-url.com/ dark market
darkweb marketplace https://worlddarkwebdrugstore.com/ dark websites
dark web search engines https://dark-market-heineken.com/ dark market url
dark market list https://world-darkmarket-online.com/ dark market link
tor market links https://heinekenonionmarket.com/ darkmarkets
darknet seiten https://worldonlinedrugs.com/ deep web sites
dark web sites https://worlddrugsmarketplace.com/ dark web drug marketplace
dark web market list https://world-online-drugs.com/ darknet market lists
darknet market lists https://world-onion-darkmarket.com/ dark market 2023
where to buy terramycin ophthalmic ointment
blackweb official website https://cypher-darkmarket-online.com/ dark markets
dark web websites https://cypherdarkmarketplace.com/ darknet markets
kamagra oral jelly available in bangalore
dark web site https://dark-market-cypher.com/ dark web link
tor markets https://heinekenoniondarkmarket.com/ dark markets
dark website https://cypher-darknet.com/ darknet websites
blackweb https://worldmarketplace24.com/ drug markets dark web
darknet links https://heineken-drugs-market.com/ onion market
dark web link https://cypher-onion-market.com/ drug markets dark web
deep dark web https://cypherdarkmarketx.com/ darknet drug market
deep dark web https://heineken-onion-market.com/ dark websites
how to get zofran
bitcoin dark web https://worldmarket-url.com/ drug markets onion
dark market url https://world-darkmarketplace.com/ how to access dark web
dark internet https://world-darkweb.com/ how to get on dark web
darkmarket 2023 https://darkwebworldmarket.com/ darknet sites
xenical discount
deep web markets https://dark-market-world.com/ darknet site
darkmarkets https://world-dark-market.com/ dark website
dark web sites https://heineken-darkweb-drugstore.com/ darknet market lists
darkmarkets https://world-drugs-online.com/ darkmarket url
darkmarket url https://cypher-onlinedrugs.com/ darknet drug market
blackweb official website https://cypher-market-online.com/ dark web sites
darkweb marketplace https://cyphermarketplace24.com/ darkmarkets
darkmarkets https://heinekendrugsmarketplace.com/ deep web markets
plavix generic brand
suhagra 100 online buy
cheap clopidogrel
dark web websites https://cyphermarket-darknet.com/ darknet seiten
free dark web https://heinekendarkwebdrugstore.com/ tor market url
darkmarket url https://worlddarkwebdrugstore.com/ how to get on dark web
dark markets 2023 https://cypherdrugsmarket.com/ deep web sites
tor markets 2023 https://cyphermarket-link.com/ tor market links
darknet links https://dark-web-world.com/ dark web link
darknet markets https://world-darkmarket-online.com/ deep web drug url
dark web market https://heinekenonionmarket.com/ darknet market
deep web search https://worlddrugsmarketplace.com/ free dark web
deep web search https://dark-market-heineken.com/ onion market
darknet market lists https://worldonionmarket.com/ dark website
darknet drug store https://world-drugsonline.com/ dark web drug marketplace
darknet market links https://cypher-darkmarket.com/ best darknet markets
dark markets https://cypherdarkweb.com/ darknet drug links
deep web markets https://cypher-darknet.com/ darkmarket link
ajanta pharma limited kamagra oral jelly
buy levitra canada
darknet links https://heinekenoniondarkweb.com/ deep web drug markets
deep web search https://heinekendrugsonline.com/ dark web search engines
darknet market list https://worldmarket-url.com/ dark web links
darknet market lists https://cypher-onion-darkweb.com/ onion market
deep web search https://cypherdarkmarketx.com/ darknet markets
blackweb https://heineken-onion-market.com/ tor darknet
dark market 2023 https://world-darkweb.com/ deep web drug links
dark web site https://worlddarkwebmarket.com/ darknet sites
deep web drug store https://worlddarknetdrugstore.com/ darknet market lists
darknet markets https://darkmarketworld.com/ darknet websites
dark market url https://world-dark-market.com/ dark web link
dark markets https://darkweb-world.com/ tor markets 2023
tor marketplace https://world-drugs-online.com/ how to get on dark web
darkmarket link https://worldmarketplacee.com/ dark website
dark market link https://cyphermarketplace24.com/ how to access dark web
deep web drug markets https://heinekendrugsmarket.com/ darknet search engine
darknet links https://cypheroniondarkmarket.com/ best darknet markets
black internet https://heinekendarknetdrugstore.com/ dark websites
darknet drug links https://world-darknet-drugstore.com/ dark market onion
buy tadacip 20 india
black internet https://cypher-market-onion.com/ dark web market
levaquin 500mg
buy trental online
phenergan vc
zofran cost generic
tor marketplace https://darkmarket-world.com/ dark web site
drug markets dark web https://cypherdrugsmarketplace.com/ darknet drugs
dark internet https://worldonionmarket.com/ deep web markets
deep web drug url https://cyphermarket-url.com/ darknet market links
tor markets 2023 https://worlddarkmarketonline.com/ tor market url
dark market list https://heineken-online-drugs.com/ deep web drug links
darknet drug store https://worlddrugsmarket.com/ darknet links
blackweb official website https://dark-market-heineken.com/ deep web drug store
dark web drug marketplace https://cypherdarknet.com/ tor market links
dark web link https://kingdomdarkwebmarket.com/ deep dark web
darknet drug market https://world-market-place1.com/ dark web site
dark web websites https://darkmarket-cypher.com/ deep web markets
deep web drug markets https://heineken-drugsonline.com/ dark web links
darkmarket url https://cypher-drugs-market.com/ darknet sites
drug markets dark web https://worldmarketdarknets.com/ dark web market list
darknet links https://world-darkweb.com/ dark internet
phenergan price australia
darknet sites https://heinekenoniondarkmarket.com/ dark market url
darknet site https://cypherdarkmarketx.com/ tor market
deep web markets https://heineken-onion-darkmarket.com/ tor markets 2023
deep web drug url https://world-drugs-online.com/ dark web market
darkmarket list https://world-onion-darkweb.com/ deep web drug url
deep web drug links https://worlddarkwebmarket.com/ dark market 2023
darkmarket link https://worldmarket-darknet.com/ darknet search engine
darkmarket list https://heineken-darkweb-drugstore.com/ tor marketplace
dark websites https://darkwebworldmarket.com/ dark web websites
dark web sites https://darkweb-world.com/ tor markets 2023
darknet market links https://worlddarkwebdrugstore.com/ blackweb
dark web link https://cyphermarketplace24.com/ blackweb
dark web sites links https://cypheroniondarkmarket.com/ the dark internet
onion market https://world-drugs-market.com/ drug markets onion
dark web market list https://worldoniondarkweb.com/ dark web link
deep dark web https://heinekendrugsmarketplace.com/ darknet markets
zovirax cream for sale
deep web drug store https://heineken-onion-darkweb.com/ dark web link
dark web sites links https://cyphermarket-darknet.com/ dark web search engines
black internet https://dark-web-world.com/ dark web site
tor market url https://heinekendarkwebdrugstore.com/ darknet site
deep web search https://cypherdrugsmarketplace.com/ tor market
buy orlistat uk
dark web link https://cyphermarket-url.com/ darknet drug links
how much is nolvadex in uk
deep web markets https://worlddarkmarketonline.com/ dark website
how much is orlistat in australia
deep web drug url https://heinekenonionmarket.com/ dark web market links
darknet websites https://dark-market-heineken.com/ darknet sites
deep dark web https://worlddrugsmarket.com/ deep web drug markets
singulair over the counter canada
dark web sites https://cypher-darkweb.com/ tor markets
tor dark web https://darkwebcypher.com/ darknet market lists
blackweb https://worldmarket-url.com/ dark web drug marketplace
dark internet https://cypher-drugsonline.com/ darknet markets 2023
darkmarket link https://heineken-drugsonline.com/ darkweb marketplace
darknet marketplace https://world-drugs-online.com/ dark web search engines
dark web link https://worldmarketplace24.com/ deep web markets
how to access dark web https://world-darkmarketplace.com/ deep web drug url
best darknet markets https://world-darkweb.com/ darknet sites
darknet drug links https://world-drugsonline.com/ how to get on dark web
darknet search engine https://heinekenoniondarkmarket.com/ darknet drug links
darknet drug links https://world-onion-darkweb.com/ darknet marketplace
darknet seiten https://cypherdarkmarketx.com/ dark web websites
deep web drug links https://worldoniondarkmarket.com/ darknet seiten
how to access dark web https://heineken-onion-market.com/ darknet site
darkmarkets https://cypher-marketplace.com/ dark internet
darknet drug market https://darkweb-world.com/ deep web sites
darkmarket url https://world-darkmarket.com/ tor market
darknet websites https://world-dark-market.com/ dark market onion
dark web markets https://worldmarketplacee.com/ darkweb marketplace
dark web access https://cypheronionmarket.com/ dark web market list
deep web search https://darkmarket-world.com/ dark market 2023
darknet site https://cyphermarket-darknet.com/ dark markets 2023
darknet markets 2023 https://heinekendrugsmarketplace.com/ tor market url
dark web markets https://heineken-onion-darkweb.com/ blackweb official website
dark web sites links https://cypherdrugsmarket.com/ darknet drug store
blackweb official website https://heinekendarkwebdrugstore.com/ darknet site
darknet market https://cypher-darkmarket.com/ darknet search engine
drug markets dark web https://cypher-darknet.com/ tor markets links
cost of synthroid 100mcg
dark web site https://cypherdarkmarketonline.com/ how to get on dark web
lyrica from mexico
how to get on dark web https://darkwebcypher.com/ darknet markets 2023
free dark web https://cyphermarket-url.com/ dark market onion
darknet markets 2023 https://cypherdarkmarketplace.com/ dark web access
darknet links https://world-onlinedrugs.com/ blackweb official website
dark web market links https://worlddarkmarketonline.com/ darknet market lists
darknet market lists https://worlddrugsmarket.com/ darkmarket 2023
deep web drug markets https://dark-market-heineken.com/ dark markets 2023
drug markets onion https://dark-market-cypher.com/ darknet markets 2023
darknet websites https://kingdomdarkwebmarket.com/ deep web drug url
best darknet markets https://world-drugs-market.com/ dark market 2023
dark websites https://heineken-onlinedrugs.com/ dark web access
dark web search engines https://world-darkwebmarket.com/ deep web drug links
darknet market links https://worldoniondarkmarket.com/ dark web drug marketplace
trental 40 mg
deep web markets https://world-market-place1.com/ darknet seiten
darkmarket 2023 https://world-onion-darkweb.com/ dark web market list
black internet https://cypher-markett.com/ deep web drug markets
lasix 40 mg cost
darknet market lists https://cyphermarketplacee.com/ drug markets dark web
onion market https://heinekenoniondarkweb.com/ darkweb marketplace
blackweb official website https://world-darknet.com/ darknet drugs
tor marketplace https://cypher-dark-market.com/ tor marketplace
darknet site https://heineken-onion-darkmarket.com/ deep web links
darkmarket link https://dark-market-world.com/ tor darknet
drug markets onion https://cypheroniondarkmarket.com/ dark markets 2023
motilium cvs
darknet websites https://world-darkmarket.com/ darknet drugs
deep web drug links https://worldmarket-darknet.com/ darknet drugs
deep web sites https://worldmarketplacee.com/ darkmarket url
singulair insomnia
best darknet markets https://worldmarketdrugsonline.com/ dark market list
elimite coupon
darkmarket link https://cypherdrugsmarketplace.com/ darkweb marketplace
darkweb marketplace https://world-drugs-online.com/ deep web drug store
darknet drug links https://cypher-market-onion.com/ dark web drug marketplace
darknet search engine https://cypher-darkmarket-online.com/ dark website
dark web sites https://heineken-onion-darkweb.com/ darknet drug links
prescription zofran where to buy
darknet drug market https://heinekendrugsmarket.com/ darkweb marketplace
deep web markets https://world-drugsonline.com/ darknet market list
how to get on dark web https://heineken-darknet-drugstore.com/ darknet markets 2023
darknet websites https://cypher-darkwebmarket.com/ darkmarket url
motilium nz
dark market link https://cypherdarkweb.com/ the dark internet
darknet market https://cyphermarket-url.com/ darknet sites
can you buy elimite cream over the counter
tor market links https://darkmarket-cypher.com/ tor markets
darknet sites https://cypherdarknet.com/ dark website
how to get on dark web https://dark-web-cypher.com/ deep web drug markets
tor market links https://heineken-online-drugs.com/ deep web links
dark market url https://worldoniondarkmarket.com/ darkmarkets
onion market https://world-darkmarket-online.com/ darkmarket link
dark market 2023 https://kingdom-darkmarket.com/ darknet search engine
darkmarket https://worlddrugsmarketplace.com/ deep web search
darknet seiten https://dark-market-heineken.com/ dark website
darknet market list https://heineken-onlinedrugs.com/ darknet markets
drug markets dark web https://world-darkmarketplace.com/ the dark internet
dark website https://worldmarketdarknets.com/ dark market url
dark market link https://cypher-markett.com/ dark market
how to access dark web https://world-onion-darkweb.com/ deep web drug links
tor markets links https://world-market-place1.com/ dark market 2023
trental 400 online
dark net https://cyphermarketplace24.com/ tor market links
ajanta pharma kamagra jelly price
tadacip 20mg
how to access dark web https://heinekenoniondarkweb.com/ darknet site
deep dark web https://world-darknet.com/ darkmarkets
black internet https://dark-market-world.com/ dark web market
bitcoin dark web https://cypher-dark-market.com/ drug markets dark web
anafranil clomipramine
levaquin drug
dark market list https://heineken-onion-darkmarket.com/ onion market
dark websites https://world-onlinedrugs.com/ dark web market links
dark market onion https://cypheroniondarkmarket.com/ dark markets
dark markets 2023 https://world-drugsonline.com/ deep web sites
free dark web https://worldmarket-darknet.com/ blackweb
best darknet markets https://heineken-darkweb-drugstore.com/ free dark web
drug markets dark web https://darkmarket-world.com/ drug markets onion
darkmarket url https://cypherdrugsmarket.com/ dark market link
tor darknet https://cypherdarkwebmarket.com/ darknet drug store
deep web drug store https://cypher-market-onion.com/ darknet market links
dark markets 2023 https://worldoniondarkmarket.com/ bitcoin dark web
dark market 2023 https://heineken-onion-darkweb.com/ drug markets onion
dark market 2023 https://dark-web-cypher.com/ dark internet
dark web market https://cypher-drugs-online.com/ deep web markets
tor market https://cyphermarket-url.com/ deep web links
deep web drug store https://cypher-darkwebmarket.com/ how to access dark web
dark web market https://heinekendrugsmarketplace.com/ tor market url
dark market list https://heineken-darknet-drugstore.com/ black internet
darknet site https://darkwebcypher.com/ darkmarket
phenergan 10mg tablet india
dark market 2023 https://cypherdarknet.com/ tor markets 2023
tor markets 2023 https://kingdomdarkwebmarket.com/ dark web websites
darknet websites https://heinekenonionmarket.com/ dark web sites links
darknet sites https://world-darkmarket-online.com/ darkmarkets
dark market onion https://worlddrugsmarket.com/ darkmarket
darkmarket link https://dark-market-heineken.com/ dark web drug marketplace
dark web sites links https://heineken-drugs-market.com/ dark web market
darknet marketplace https://worldmarketdarknets.com/ tor market links
darknet market lists https://world-darkmarketplace.com/ deep web drug links
drug markets onion https://worlddarknetdrugstore.com/ deep web drug links
deep web sites https://cypher-marketplace.com/ tor markets
darknet market lists https://cypher-markett.com/ tor market links
tor markets links https://world-market-place1.com/ tor marketplace
acyclovir without prescription
dark web link https://darkwebworldmarket.com/ darknet marketplace
tor market url https://world-darkweb.com/ dark website
tor markets links https://heinekenoniondarkweb.com/ dark market list
blackweb https://cypher-dark-market.com/ dark net
dark web links https://cypher-onlinedrugs.com/ darkmarket link
onion market https://heineken-onion-darkmarket.com/ darknet seiten
tetracycline tablets for sale
blackweb official website https://world-dark-market.com/ black internet
tor markets https://cypher-darknet.com/ darkmarket 2023
darknet drugs https://darkmarket-world.com/ dark web links
darknet market https://cypherdrugsmarket.com/ darknet websites
dark market 2023 https://world-drugs-online.com/ deep web drug links
dark markets 2023 https://cypher-darkmarket.com/ tor markets links
dark market url https://world-drugsonline.com/ dark market
dark market url https://worldmarketplacee.com/ dark market url
dark net https://worlddarkwebmarket.com/ darkmarket 2023
where to buy nolvadex in australia
dark net https://cypher-drugs-online.com/ darknet market
dark market https://cypher-market-onion.com/ dark market onion
yasmin medicine
darkweb marketplace https://cyphermarket-link.com/ tor market links
medrol 4 mg dose pack
darkmarket url https://heinekendarknetdrugstore.com/ deep web drug store
tor market url https://cypher-darkwebmarket.com/ darkweb marketplace
tor darknet https://heinekendarkwebdrugstore.com/ darknet websites
darknet drug links https://heinekendrugsmarket.com/ darknet drug market
dark web sites https://darkwebcypher.com/ dark web link
dark web market https://kingdom-darkmarket.com/ dark web market list
how to access dark web https://worldoniondarkweb.com/ blackweb
tetracycline medicine price in india
darkmarket list https://worlddarkwebdrugstore.com/ tor marketplace
diflucan 200mg tab
cialis generic price in us
darkweb marketplace https://dark-market-heineken.com/ tor dark web
deep web drug markets https://heineken-onlinedrugs.com/ deep web search
deep web drug url https://cypherdarknet.com/ tor markets
tor market url https://heinekenonlinedrugs.com/ deep web drug store
tor darknet https://worlddarkweb.com/ darknet links
tor markets https://heineken-online-drugs.com/ darknet drugs
how to get on dark web https://world-onion-market.com/ tor market url
deep web links https://worlddrugsmarketplace.com/ bitcoin dark web
dark web sites links https://cypher-markett.com/ deep web drug links
tor dark web https://cyphermarketplacee.com/ the dark internet
darkmarket url https://heineken-drugs-market.com/ bitcoin dark web
tor markets 2023 https://worldmarketplace24.com/ darkmarket 2023
dark web websites https://darkwebworldmarket.com/ dark web sites
darkmarket list https://world-darkweb.com/ best darknet markets
darkmarket 2023 https://cypheronionmarket.com/ deep web links
darknet search engine https://heinekenoniondarkweb.com/ darknet markets 2023
tor market url https://cypher-dark-market.com/ blackweb official website
darkweb marketplace https://heineken-onion-darkmarket.com/ deep web links
deep web drug links https://cypher-darkmarket-online.com/ dark markets 2023
dark markets https://dark-web-world.com/ darknet site
dark web links https://worldonlinedrugs.com/ dark web links
levaquin drug
dark web sites links https://cypherdrugsonline.com/ black internet
black internet https://world-onlinedrugs.com/ best darknet markets
darkweb marketplace https://cypheronlinedrugs.com/ darkmarkets
blackweb https://worldmarket-darknet.com/ deep web drug links
darknet drugs https://worlddarkwebmarket.com/ darknet drug market
dark web search engines https://cypher-darkmarket.com/ dark market
deep web markets https://worldmarketplacee.com/ darkmarkets
dark internet https://cypher-market-onion.com/ tor darknet
synthroid 37.5 mg
dark web site https://heinekendarknetdrugstore.com/ darknet sites
dark web websites https://kingdomdarkwebmarket.com/ darknet websites
xenical 17.2 mg
drug markets dark web https://cypher-marketplace.com/ dark market list
where can i buy robaxin in canada
darknet markets https://dark-market-heineken.com/ dark web markets
darknet markets 2023 https://cypherdarkmarketonline.com/ darknet markets
darknet websites https://world-onion-darkmarket.com/ darknet marketplace
tor market links https://heinekendrugsmarket.com/ darkmarkets
dark market onion https://darkwebcypher.com/ drug markets onion
darkmarket link https://heineken-darknet-drugstore.com/ tor marketplace
dark web search engines https://world-darkmarketplace.com/ dark website
dark market 2023 https://worlddarkweb.com/ darknet drugs
darkmarket link https://heineken-onlinedrugs.com/ tor marketplace
dark net https://heinekendrugsonline.com/ deep web links
dark web sites links https://worlddarkmarketonline.com/ dark markets 2023
darknet drug store https://cypher-markett.com/ darknet links
dark market url https://cypherdarknet.com/ darkmarket
onion market https://heineken-online-drugs.com/ tor darknet
dark web search engines https://heineken-drugs-market.com/ deep web sites
blackweb https://worlddrugsmarket.com/ dark market link
motilium online
tor market links https://dark-market-world.com/ darkmarket 2023
dark market 2023 https://world-market-place1.com/ how to get on dark web
darkmarket https://cypher-onlinedrugs.com/ dark web sites
darknet sites https://world-darknet.com/ deep web drug url
dark web site https://cypherdarkmarketx.com/ darknet site
tor markets links https://cypher-drugs-online.com/ deep web links
singulair for allergies
darkmarket url https://heinekenoniondarkweb.com/ dark web drug marketplace
dark markets https://cypher-darknet.com/ dark web links
drug markets onion https://worldmarketdrugsonline.com/ dark market list
darkmarket url https://world-drugs-market.com/ dark market 2023
dark web search engines https://heineken-onion-darkmarket.com/ tor marketplace
dark internet https://cypherdarkweb.com/ dark web market list
darkmarket list https://world-dark-market.com/ drug markets dark web
motilium pills
darknet websites https://cypher-darkmarket.com/ dark market
darknet websites https://worldmarketplacee.com/ how to get on dark web
generic medrol online no prescription
darknet seiten https://world-darkmarket.com/ darkmarket list
online pharmacy augmentin
clopidogrel 20 mg
darknet websites https://world-onion-darkweb.com/ dark web market list
blackweb official website https://cyphermarketplace24.com/ drug markets onion
darknet market lists https://world-online-drugs.com/ dark web search engine
dark web market links https://kingdomdarkwebmarket.com/ dark market list
dark market 2023 https://heineken-onion-darkweb.com/ blackweb
darknet links https://heinekendrugsmarketplace.com/ black internet
gabapentin cost canada
dark web site https://cypher-markett.com/ dark web search engines
deep web drug store https://darkmarket-cypher.com/ dark market list
tor markets links https://world-darkmarketplace.com/ darknet links
darkmarket link https://heinekendarkwebdrugstore.com/ darknet market links
deep dark web https://heineken-drugs-market.com/ onion market
dark market https://worldmarketdarknets.com/ dark web drug marketplace
dark website https://worlddarkmarketonline.com/ tor dark web
dark web market list https://cypher-darkweb.com/ darknet market list
darknet drugs https://heineken-online-drugs.com/ free dark web
darkmarket 2023 https://worlddrugsmarket.com/ onion market
darknet websites https://darkmarketworld.com/ dark web markets
tor markets links https://cypher-online-drugs.com/ darknet market lists
buy trental
darknet drug links https://worldmarketplace24.com/ dark market
tor markets 2023 https://cypher-drugs-online.com/ how to access dark web
darknet drug store https://world-onlinedrugs.com/ dark web sites links
deep web sites https://cypher-dark-market.com/ black internet
deep web sites https://cypherdarkwebmarket.com/ dark web sites
dark market 2023 https://worldonlinedrugs.com/ dark web websites
dark market https://world-darkweb.com/ drug markets onion
deep web links https://cypherdarkmarketplace.com/ dark websites
deep web markets https://heinekenoniondarkmarket.com/ black internet
dark web websites https://heineken-onion-darkmarket.com/ dark market 2023
tor market url https://world-dark-market.com/ tor market url
the dark internet https://heineken-darkweb-drugstore.com/ darknet drug links
darkmarket list https://cypher-darkmarketplace.com/ darknet search engine
darkweb marketplace https://cyphermarketplace24.com/ tor markets links
deep dark web https://world-darkmarket.com/ deep web markets
dark web market https://world-online-drugs.com/ darkmarket link
synthroid 137 coupon
order nolvadex online
dark market 2023 https://worldmarket-linkk.com/ drug markets dark web
darknet market list https://heineken-onion-darkweb.com/ deep web drug url
how to access dark web https://world-darkweb-drugstore.com/ dark net
dark web search engines https://darkmarket-cypher.com/ dark web search engines
generic zovirax cream 5g
colchicine for gout
darknet seiten https://world-darkwebmarket.com/ deep web drug links
best darknet markets https://world-darkmarket-online.com/ tor darknet
tor markets links https://worldmarketdarknets.com/ dark web drug marketplace
dark web market links https://heineken-darknet-drugstore.com/ dark market url
tor market url https://cypher-darkweb.com/ tor market links
darknet websites https://darkmarketworld.com/ onion market
darkweb marketplace https://heinekenonionmarket.com/ darknet drugs
tetracycline capsule 250mg
dark web sites https://darkweb-cypher.com/ darkmarkets
phenergan 12.5 mg tablets
darknet market https://worldmarketplace24.com/ dark web links
best darknet markets https://world-drugsonline.com/ deep web links
deep web sites https://world-onlinedrugs.com/ darknet markets
dark web links https://worldmarketdrugsonline.com/ deep web drug links
dark market url https://cypher-dark-market.com/ darknet markets 2023
dark market onion https://cypher-darkmarket-online.com/ darknet site
darkmarket url https://cypher-market-onion.com/ darknet drug store
dark market url https://world-darkweb.com/ dark web drug marketplace
black internet https://worlddarknetdrugstore.com/ tor marketplace
bupropion sr 100 mg
tor markets 2023 https://world-dark-market.com/ tor market
tor market links https://heinekenoniondarkweb.com/ dark web market list
deep dark web https://worldoniondarkmarket.com/ deep web sites
motilium nz
deep web drug markets https://heineken-darkweb-drugstore.com/ tor market url
darkmarket https://world-online-drugs.com/ darknet websites
deep dark web https://heineken-onion-market.com/ darknet market links
darknet site https://cypher-darkmarketplace.com/ dark web sites
trental 400 mg
free dark web https://worldmarket-linkk.com/ darknet marketplace
darkweb marketplace https://heinekendrugsmarket.com/ deep web drug store
blackweb official website https://world-darkmarket.com/ best darknet markets
tor darknet https://heineken-drugsonline.com/ darknet market links
tor darknet https://heineken-drugs-online.com/ darkmarket
how much is diflucan 150 mg
112 mcg synthroid price
darkmarket 2023 https://cypher-markett.com/ tor market
canadianpharmacyworld
tor markets 2023 https://heinekendarknetdrugstore.com/ darknet seiten
dark market onion https://darkmarket-cypher.com/ tor market
dark web sites https://dark-market-cypher.com/ deep web search
darknet market lists https://cypherdrugsmarketplace.com/ darknet links
black internet https://darkwebworldmarket.com/ dark web market list
darknet markets https://worlddarkmarketonline.com/ tor dark web
darknet drug market https://world-darkmarketplace.com/ dark web search engines
darknet seiten https://worldmarketdarknets.com/ darkmarket link
kamagra 4 europe
tor market links https://cypherdarknet.com/ darknet marketplace
dark market onion https://heineken-darknet-drugstore.com/ darknet drug links
dark web access https://heineken-online-drugs.com/ tor dark web
free dark web https://world-market-place1.com/ blackweb official website
celebrex 100 tablet
how to get on dark web https://cypherdarkweb.com/ dark web markets
dark web drug marketplace https://world-onlinedrugs.com/ bitcoin dark web
tor darknet https://world-drugs-market.com/ dark website
darknet market links https://darkmarket-world.com/ darkmarket list
dark market list https://darkmarketcypher.com/ deep web drug markets
darknet seiten https://dark-market-heineken.com/ darkmarket
dark market 2023 https://cypher-market-onion.com/ onion market
where to buy orlistat in canada
darknet drug store https://cyphermarketplace24.com/ dark web search engine
dark web market https://worldoniondarkmarket.com/ deep dark web
darknet drug store https://world-dark-market.com/ dark market link
tor darknet https://world-darknet.com/ dark market 2023
darknet websites https://worldmarket-url.com/ darkmarkets
black internet https://heineken-darkweb-drugstore.com/ blackweb official website
buy robaxin australia
dark web links https://heinekenoniondarkweb.com/ tor market links
darknet markets https://heineken-drugsonline.com/ dark web drug marketplace
darknet websites https://worldonionmarket.com/ blackweb official website
dark web search engines https://cypher-darkmarket.com/ bitcoin dark web
darknet market lists https://heineken-onlinedrugs.com/ best darknet markets
tor darknet https://heineken-onion-darkmarket.com/ onion market
the dark internet https://world-darkmarket.com/ how to get on dark web
dark web links https://world-darkweb-drugstore.com/ deep web drug links
deep web drug store https://darkwebcypher.com/ darknet markets 2023
darknet markets 2023 https://heineken-onion-darkweb.com/ how to access dark web
dark web access https://world-darkwebmarket.com/ dark market link
darknet sites https://darkmarketworld.com/ how to access dark web
darknet market links https://darkweb-world.com/ darkmarket list
tor market https://worlddarkweb.com/ dark web websites
dark web websites https://worlddrugsmarket.com/ onion market
darknet seiten https://cypherdarknet.com/ dark market url
xenical nz pharmacy
darknet market lists https://heinekendarkwebdrugstore.com/ darkmarket url
best darknet markets https://heineken-online-drugs.com/ deep web search
dark web websites https://worldmarketplace24.com/ black internet
where to get zofran
dark web links https://cyphermarket-link.com/ dark web market links
dark web markets https://cypherdarkmarketplace.com/ darkmarket 2023
onion market https://world-drugsonline.com/ dark markets
dark web link https://darkmarket-world.com/ how to access dark web
dark markets 2023 https://darkmarketcypher.com/ dark web sites links
black internet https://world-onion-darkweb.com/ dark web search engines
darknet market lists https://worlddarkwebdrugstore.com/ how to access dark web
dark web site https://world-dark-market.com/ blackweb official website
onion market https://dark-market-heineken.com/ darknet markets 2023
free dark web https://heineken-darkweb-drugstore.com/ how to access dark web
darknet links https://kingdom-darkmarket.com/ dark net
tor market links https://cyphermarket-darknet.com/ deep web search
darknet search engine https://world-onion-market.com/ dark market link
darknet site https://worldoniondarkmarket.com/ darknet drugs
deep web sites https://world-darknet.com/ black internet
blackweb official website https://heineken-drugsonline.com/ darknet markets
how to get on dark web https://world-online-drugs.com/ deep web drug store
deep web drug url https://heinekenoniondarkweb.com/ dark web site
deep web drug url https://cypher-darkmarket.com/ dark market url
dark web site https://cypher-market-online.com/ tor markets
darkmarket link https://heineken-drugs-online.com/ darkmarket link
darknet seiten https://world-darkmarket.com/ deep web drug markets
phenergan without prescription
buy synthroid 150 mcg
darknet search engine https://cypher-darkwebmarket.com/ deep dark web
tor markets links https://world-darkmarketplace.com/ dark web search engines
black internet https://dark-market-world.com/ darknet sites
dark web sites https://worlddarkweb.com/ darknet search engine
dark web market https://worlddrugsmarketplace.com/ best darknet markets
levaquin 250
dark web market list https://cypher-darkweb.com/ tor market links
dark internet https://worldmarketplace24.com/ dark web websites
dark internet https://cypher-dark-market.com/ drug markets onion
darkweb marketplace https://world-drugs-online.com/ tor markets 2023
motilium 10 mg
onion market https://worldonlinedrugs.com/ dark web drug marketplace
deep web drug markets https://heineken-darkweb-drugstore.com/ drug markets dark web
darkmarket 2023 https://cypherdarkweb.com/ deep web drug markets
dark markets 2023 https://cypherdarkwebmarket.com/ dark market
tor markets 2023 https://worlddarkwebdrugstore.com/ best darknet markets
darkmarket https://dark-market-heineken.com/ dark web site
dark markets https://cyphermarketplace24.com/ deep web sites
deep web drug url https://kingdom-darkmarket.com/ blackweb
valacyclovir without a prescription
best darknet markets https://worldoniondarkmarket.com/ darkmarket link
yasmin rizvi
tor markets links https://heinekendrugsmarket.com/ tor marketplace
tor market url https://cyphermarket-darknet.com/ dark market
motilium 10g
dark web sites https://world-darkwebmarket.com/ dark market onion
robaxin usa
dark web drug marketplace https://cyphermarketplacee.com/ deep web markets
deep web search https://heineken-drugs-online.com/ dark net
best darknet markets https://worldonionmarket.com/ darkmarket url
darknet websites https://cypher-darkmarket.com/ darknet drug store
darknet links https://cypher-darkwebmarket.com/ dark web drug marketplace
deep web drug store https://dark-market-world.com/ dark web sites
levaquin cost
buy medrol online
black internet https://worldmarketplacee.com/ dark web link
dark markets 2023 https://worlddrugsmarketplace.com/ onion market
dark market list https://cypher-darkweb.com/ deep web links
darknet market links https://cypher-dark-market.com/ deep web markets
darknet sites https://world-drugs-online.com/ tor market url
trental
darkweb marketplace https://worldmarketdrugsonline.com/ tor market
onion market https://darkmarketcypher.com/ darknet drug store
darkmarkets https://world-darknet-drugstore.com/ the dark internet
free dark web https://cypherdarkmarketplace.com/ dark market
darknet drug store https://world-darknet.com/ dark web sites links
dark net https://heineken-drugsonline.com/ blackweb
dark websites https://world-onion-market.com/ dark market onion
singulair 5mg tab
darkmarket list https://heineken-onion-darkweb.com/ dark web site
price of 21 acyclovir 400mg tablets
darknet markets 2023 https://heinekendarkwebdrugstore.com/ onion market
dark market onion https://heinekendrugsmarketplace.com/ dark markets
deep web sites https://cyphermarketplace24.com/ dark web market list
dark markets https://cypher-market-onion.com/ tor markets links
deep web drug url https://cypher-markett.com/ dark web market list
dark website https://heineken-onlinedrugs.com/ darknet markets 2023
deep dark web https://cypher-darkmarket.com/ deep dark web
darknet markets https://darkmarket-cypher.com/ tor dark web
kamagra jelly usa
dark internet https://world-online-drugs.com/ dark market onion
phenergan over the counter nz
dark web sites links https://darkweb-world.com/ tor darknet
order levaquin
how to get on dark web https://cyphermarket-url.com/ dark web drug marketplace
trental medicine
dark web link https://world-onlinedrugs.com/ onion market
deep web markets https://worlddrugsmarket.com/ dark web market
darkmarket 2023 https://dark-web-world.com/ deep web links
dark market onion https://darkmarketcypher.com/ darknet links
darknet market links https://cypher-darknet.com/ tor market url
dark web sites links https://world-darknet-drugstore.com/ deep web drug markets
singulair australia
tor dark web https://cypherdarkweb.com/ dark web links
dark web websites https://heinekenoniondarkmarket.com/ drug markets onion
darknet search engine https://heineken-drugs-market.com/ drug markets dark web
dark market 2023 https://world-onion-market.com/ darknet market list
dark web site https://heineken-online-drugs.com/ tor marketplace
darkmarket url https://heinekenonlinedrugs.com/ dark web markets
darkmarket link https://heineken-onion-darkmarket.com/ deep web drug url
dark web market https://heineken-darknet-drugstore.com/ dark web site
tor market url https://heinekendrugsmarketplace.com/ dark web links
dark web links https://cyphermarketplace24.com/ deep web search
dark websites https://cyphermarket-darknet.com/ black internet
bitcoin dark web https://cypher-markett.com/ dark web site
darknet seiten https://cypher-darkmarketplace.com/ tor marketplace
darknet drug store https://cypherdarkmarketonline.com/ drug markets onion
deep web drug url https://heineken-drugs-online.com/ deep web sites
dark web site https://darkmarket-cypher.com/ darknet drug market
darkmarkets https://worldonionmarket.com/ dark web market links
darknet websites https://dark-market-world.com/ dark web links
darkmarket list https://darkmarketworld.com/ dark market list
zofran 30 tablets
deep web drug markets https://cypherdarknet.com/ tor markets links
dark market url https://cyphermarket-url.com/ deep web markets
silagra 25 mg price
dark web market list https://world-drugs-online.com/ darknet drug store
motrin tablets in india
dark web websites https://worlddrugsmarketplace.com/ dark net
darknet drug market darkweb marketplace
dark web websites https://darkmarketcypher.com/ darknet seiten
darkmarket url https://world-darknet-drugstore.com/ darkweb marketplace
tetracycline 500mg capsules cost
dark web market links https://cypherdarkmarketplace.com/ dark market list
tor dark web https://worldoniondarkmarket.com/ darknet market lists
buying valtrex in mexico
cialis medicine online
trental 400 mg
blackweb official website https://cyphermarketplace24.com/ deep web drug markets
darknet sites https://cypher-market-onion.com/ dark markets 2023
buy robaxin uk
levaquin antibiotic
tor market url https://cypher-darkmarketplace.com/ deep web drug markets
generic synthroid pill
plavix 150 mg
how to get on dark web https://darkwebworldmarket.com/ darknet market
tadalafil 30mg
darkmarket link https://darkwebcypher.com/ dark website
dark web market list https://world-online-drugs.com/ dark web access
darknet market list dark markets
azithromycin buy online
how to access dark web https://cypherdarkmarketx.com/ blackweb official website
how to access dark web https://cypherdarknet.com/ deep web drug url
how to get on dark web https://world-onlinedrugs.com/ the dark internet
darkmarket list https://darkmarket-world.com/ how to access dark web
darknet market lists https://cyphermarket-link.com/ deep web drug markets
darkweb marketplace https://worlddrugsmarket.com/ deep web drug links
160 bactrim
dark web link https://darkmarketcypher.com/ the dark internet
deep dark web https://worlddarkwebdrugstore.com/ dark web market links
tor marketplace https://world-onion-darkweb.com/ drug markets onion
buy ciprofloxacin over the counter
dark web sites https://worldoniondarkmarket.com/ blackweb
darknet seiten https://cypherdarkmarketplace.com/ dark web drug marketplace
darknet links dark markets 2023
darknet seiten https://world-darkweb-drugstore.com/ dark net
darknet links https://cypher-markett.com/ dark markets
deep web drug url https://cyphermarket-darknet.com/ dark markets
darknet site https://cypher-darkmarketplace.com/ dark websites
dark market url https://darkmarketworld.com/ deep web search
dark market https://worldonionmarket.com/ dark web drug marketplace
dark net https://darkwebcypher.com/ darknet site
darkmarkets https://cypherdarkmarketx.com/ drug markets onion
deep dark web https://world-onlinedrugs.com/ tor darknet
cheap kamagra jelly
darkmarket url https://worlddrugsmarketplace.com/ darknet seiten
dark web drug marketplace blackweb
tor market https://cyphermarket-url.com/ deep web sites
darknet market list https://world-darknet-drugstore.com/ tor markets
dark websites https://darkmarketcypher.com/ darknet markets
darknet market https://worldoniondarkweb.com/ black internet
dark market 2023 https://world-darkweb-drugstore.com/ how to get on dark web
darknet websites https://cypherdarkweb.com/ dark net
motilium 10
darknet markets 2023 https://cypher-darkmarket.com/ dark web market links
dark web sites https://cypher-market-onion.com/ dark websites
tor market links https://darkmarketworld.com/ onion market
tor market deep web search
lyrica
tadacip for sale uk
darknet drug market https://darkmarket-cypher.com/ how to access dark web
dark web access https://worldonionmarket.com/ deep web sites
darknet drug market https://world-drugsonline.com/ darkmarket list
darknet market links https://worldonlinedrugs.com/ darkmarket
darknet site https://cypherdarkmarketx.com/ darknet drug market
cheap generic strattera
deep web markets https://darkmarket-world.com/ deep web drug markets
darkmarkets https://world-onion-darkweb.com/ blackweb
dark web link https://cypher-darknet.com/ tor market links
darkmarket list https://cyphermarket-url.com/ darknet site
buy citalopram
dark web markets https://world-onion-darkmarket.com/ dark internet
onion market https://cypher-markett.com/ darknet links
darknet markets https://world-darkweb-drugstore.com/ dark website
hydroxychloroquine sulfate 200mg tablet
deep web links tor markets 2023
generic lyrica cost
dark web site https://cypherdarkweb.com/ dark market list
price of celebrex 200mg capsules
darkmarkets https://cypher-darkwebmarket.com/ bitcoin dark web
darknet websites darknet drug store
black internet tor market links
darknet websites tor market
tor markets https://cyphermarket-darknet.com/ dark web links
deep web drug url tor markets links
propecia 1mg tablets price
dark internet dark web websites
tor market url deep web drug links
robaxin generic price
drug markets onion https://darkmarket-cypher.com/ darknet drugs
tor market links https://cypherdarkmarketx.com/ deep web drug url
darknet seiten dark web access
darknet markets 2023 darknet drug store
darknet websites dark web websites
where to get flagyl
dark markets dark web access
5 mg buspar
darkmarket url https://world-darknet-drugstore.com/ dark web search engines
the dark internet https://heinekenonlinedrugs.com/ dark web market
strattera 18 mg coupon
darknet market list dark market
reputable online pharmacy reddit
cymbalta comparison
best darknet markets darkmarket url
dark web link https://cypher-darkmarket-online.com/ darknet markets 2023
fluoxetine 10 mg tablet
medrol 4 mg coupon
dark web markets https://cyphermarket-url.com/ dark market link
deep web markets https://cyphermarketplacee.com/ darkmarket list
deep dark web deep web sites
how to get on dark web darkmarket link
dark web market list tor market
dark web link dark web sites links
darkmarket tor darknet
buy phenergan online uk
deep web drug url tor market url
tor markets https://cypherdarkweb.com/ darknet drugs
deep web drug links dark web access
dark market 2023 https://cypher-darkmarketplace.com/ dark websites
buspar 10mg price
tor market dark web links
darknet markets darknet websites
darknet markets 2023 dark web sites links
phenergan over the counter usa
how to get on dark web dark internet
dark market darknet market lists
deep web drug links dark market list
phenergan 25 mg otc
deep web drug markets dark web search engines
darkweb marketplace dark web drug marketplace
strattera cheapest
drug markets onion darknet marketplace
dark web market list tor markets links
dark web search engines darkmarket
dark market url the dark internet
robaxin 750 mg tabs
darknet markets 2023 drug markets onion
dark web search engine darkmarket
onion market drug markets dark web
dark market link darknet websites
drug markets onion dark market list
deep web sites dark web site
tor markets 2023 darknet sites
darkweb marketplace tor markets
tor market links tor markets 2023
tor market url tor markets
tor markets deep web drug url
darknet markets 2023 https://heinekendrugsonline.com/ darknet drugs
deep web drug store darknet market list
darkmarket link best darknet markets
tor markets darkmarket 2023
darkmarket 2023 deep dark web
dark websites dark web market links
best darknet markets dark internet
darknet websites dark web websites
dark web drug marketplace darknet markets 2023
best darknet markets dark market list
darkmarket drug markets onion
drug markets onion dark web sites links
dark web market list drug markets onion
robaxin 500 mg tablets
deep web drug store darknet market links
dark web site dark web site
darknet links dark market 2023
lyrica no prescription
dark web links dark web access
tor marketplace dark web market links
generic for cymbalta
tor darknet tor dark web
dark website darknet market links
dark market list best darknet markets
onion market dark web search engines
onion market deep web markets
darknet sites darknet markets
darkmarkets dark web link
darkmarket link darknet drugs
darknet site tor market
dark web link deep web drug url
deep web drug store onion market
darkmarket darkmarket url
darknet market darknet marketplace
dark markets deep web drug links
blackweb official website darknet market list
darkmarket link dark web market
darkmarkets bitcoin dark web
dark websites tor markets
dark web search engine darknet marketplace
dark web websites darknet market links
tor markets https://heinekenonlinedrugs.com/ darknet market links
darknet markets dark web search engines
tor market tor marketplace
generic levaquin
darknet search engine darknet markets 2023
darkmarket url dark markets
free dark web dark market list
dark web drug marketplace darkmarkets
dark markets 2023 darknet site
dark market url tor market links
bactrim capsule
drug markets dark web dark web access
bactrim uk
darknet markets 2023 deep web drug store
best darknet markets darkweb marketplace
darknet markets 2023 deep web sites
tor market url tor markets
dark web search engines dark web market
darkmarket link dark market list
dark markets deep web drug markets
dark web websites dark web websites
motrin 800 pills
blackweb official website darknet seiten
onion market darknet market
darknet seiten dark web search engines
darknet drug market dark markets 2023
dark web search engines deep dark web
darknet markets deep web markets
deep web drug url dark web link
how to access dark web darkmarket url
tor darknet dark web search engine
darknet websites deep web drug markets
deep web sites darknet market lists
how to access dark web darkmarket 2023
escrow pharmacy online
dark net blackweb
dark web links darkmarket 2023
tor market url deep web markets
darknet drug market darknet seiten
cheap albuterol
dark markets darknet marketplace
dark market dark web markets
bitcoin dark web deep web markets
dark market link tor markets 2023
albendazole 2 tabs
how to get on dark web dark web market list
ciprofloxacin 500mg tablets price in india
blackweb https://heinekendrugsonline.com/ darknet market list
blackweb official website dark market list
tor darknet dark web link
bitcoin dark web blackweb official website
tor markets 2023 dark internet
dark internet darknet market lists
dark market link deep web drug url
darknet seiten dark website
dark market list dark web sites links
drug markets dark web darknet drug market
dark web markets dark markets
darknet marketplace darknet markets 2023
black internet tor markets links
darkweb marketplace deep web search
darknet market links darknet drugs
bitcoin dark web darkmarket
trental for sale
deep web markets drug markets dark web
darknet marketplace deep web drug store
dark web search engine dark web websites
darkweb marketplace deep web drug store
darkmarket how to access dark web
tor darknet darknet market links
black internet dark net
dark web sites links darknet sites
darkmarket the dark internet
darknet drug links darkmarket 2023
dark website darknet links
dark market 2023 tor markets links
dark web links darknet markets 2023
darknet drug links dark web websites
deep web links darkmarket
dark web websites free dark web
the dark internet darknet market list
dark web market dark web links
dark market url tor dark web
robaxin 750 canada
free dark web darkweb marketplace
colchicine otc uk
darkmarket deep web sites
darknet links deep web drug links
dark web market links darkmarket 2023
dark web sites darknet market lists
dark market 2023 darknet market
tor dark web https://heinekendrugsonline.com/ deep web drug links
black internet tor dark web
darknet marketplace tor market url
tor markets 2023 darknet sites
deep web drug store dark web market list
dark web sites links how to get on dark web
darknet sites dark web sites
phenergan uk otc
darknet site dark web market
tor darknet darknet seiten
tor marketplace dark web drug marketplace
dark web market links free dark web
tor markets 2023 drug markets dark web
darknet search engine dark web markets
dark market url dark net
deep web drug links tor market
deep web links dark web site
blackweb darknet markets 2023
dark web market tor market
darknet market links dark web websites
blackweb darknet markets 2023
dark web site dark web markets
tor dark web drug markets onion
tor marketplace tor markets links
black internet tor market url
darkmarket url the dark internet
darknet seiten deep web drug url
dark markets deep web links
black internet darknet market list
deep web drug links darknet search engine
darknet drugs dark market list
darkmarkets darkmarket 2023
diflucan 50
dark web websites dark web drug marketplace
bitcoin dark web darkmarket link
darknet drug market dark web market links
deep web drug url darknet site
dark web market list drug markets onion
dark websites deep web drug links
dark market 2023 dark web search engines
dark web sites links deep web search
dark web access tor market links
dark web access https://heinekenonlinedrugs.com/ deep dark web
dark market list dark internet
buy phenergan 10mg online
darknet markets 2023 best darknet markets
dark web link tor dark web
darkmarket darknet search engine
where can i get flagyl tablets
darkmarket url darknet websites
drug markets onion dark web websites
levaquin online
darknet websites dark web drug marketplace
dark web market list dark market list
phenergan tablets
deep web markets dark website
darknet websites dark market
trental
darkmarkets drug markets onion
darknet links dark market url
dark market list dark internet
dark web access free dark web
darknet drug links dark web markets
darknet websites black internet
dark web markets dark websites
how to get on dark web how to access dark web
dark web links darknet markets
darkmarket url dark web market
darknet marketplace dark web search engines
tor darknet dark market onion
price of generic strattera
deep web drug url deep web drug url
darknet seiten tor markets 2023
drug clopidogrel 75 mg
dark web market links deep web search
ampicillin cost in india
darknet search engine deep web drug links
darknet sites dark web link
darknet websites dark market 2023
how to get on dark web deep web sites
dark markets 2023 onion market
dark web sites the dark internet
dark web search engine darknet market
blackweb dark web drug marketplace
dark websites darkmarkets
darkmarket darkmarket
darknet drug store darknet market list
deep web drug links darknet market
darknet markets darkmarket url
dark web market tor market url
tor market darknet marketplace
dark web access deep dark web
dark web search engine https://heinekenonlinedrugs.com/ dark websites
blackweb official website darknet market
deep web markets deep dark web
deep web sites dark web sites links
deep web links drug markets onion
dark web link darkmarket
deep web links dark web links
tor market links dark net
albenza 200 mg coupon
best darknet markets deep web drug url
darknet market list free dark web
trental 400 australia
dark web sites links best darknet markets
dark market onion deep web drug links
darkmarkets darknet seiten
darkmarket 2023 darkmarket
how to get on dark web dark websites
dark websites darknet markets 2023
dark websites onion market
dark web link dark market url
dark markets darkmarkets
darkmarket link dark web sites
elimite cream over the counter
tamoxifen buy australia
dark websites tor marketplace
darknet search engine bitcoin dark web
cost of flagyl
cheap flagyl
darknet markets tor darknet
darkweb marketplace darkmarket 2023
free dark web darknet sites
darkmarkets blackweb official website
deep dark web darknet markets 2023
generic robaxin 500mg
the dark internet dark web sites links
cipro brand
dark markets 2023 black internet
deep dark web darkmarket list
dark web search engines bitcoin dark web
buy suhagra 100mg
cymbalta price canada
darknet drug market darknet marketplace
tor markets 2023 free dark web
dark net deep web markets
dark market list deep web search
dark markets 2023 tor markets 2023
darknet drug store blackweb official website
darknet market darkweb marketplace
dark web websites tor dark web
dark web search engine darknet site
darknet links dark web markets
deep web drug markets dark web links
dark web sites links tor market url
darkmarket url https://heinekenonlinedrugs.com/ deep web drug url
1200 mg motrin
dark market onion darknet marketplace
dark web market links darknet drug market
deep web drug links tor dark web
dark market darknet markets
darknet drugs dark market onion
tor dark web blackweb official website
how to access dark web deep web markets
generic tetracycline 500mg
dark web sites links tor market url
dark web websites dark website
tor market url darkmarket
dark markets 2023 darknet market
darknet drug links blackweb
darknet market list how to access dark web
darknet marketplace darknet market
darknet markets 2023 dark web search engine
darknet market lists tor markets
dark market drug markets dark web
dark market list tor market url
darknet drug links darknet search engine
dark web drug marketplace darknet market lists
anafranil 25g
dark web sites links darknet market
darknet site dark web search engine
dark market 2023 darknet drug links
deep web links darkmarket
how to get on dark web tor markets links
cymbalta online uk
dark market list dark markets 2023
deep web search dark websites
blackweb dark web search engine
dark market onion darknet markets 2023
best darknet markets darknet search engine
deep dark web dark market 2023
dark market dark market url
viagra coupon
darkmarkets tor marketplace
dipyridamole 100mg tablets
dark internet deep web markets
cost of buspar
erythromycin capsules
deep web links darknet seiten
darknet market lists dark web sites
darknet search engine deep web drug url
darknet search engine dark web market links
how to access dark web https://heinekenonlinedrugs.com/ dark web markets
deep web links tor market
dark market onion blackweb official website
bitcoin dark web dark web search engines
albendazole over the counter usa
furosemide drug
buy cheap levaquin
darkmarket list deep web links
dark internet dark web markets
dark web drug marketplace dark market onion
dark market link tor markets links
dark internet dark market
dark web search engine tor markets links
darknet drug store deep web drug links
dark web markets tor market
darkmarket deep web drug store
tor dark web darknet market lists
darknet links deep web sites
darkmarkets darkmarket
darknet market list the dark internet
dark web market list tor markets 2023
darknet site dark websites
dark markets how to access dark web
dark web link dark net
darknet site deep web drug markets
singulair depression
bactrim 40 mg
darknet site free dark web
darknet markets 2023 dark web markets
dark market url darknet drug market
tor dark web dark market
deep web drug markets darknet websites
dark markets darkmarket link
dark web site darkmarket url
1 mg synthroid
the dark internet dark market onion
dark web links tor dark web
4 motrin pills
tor markets 2023 dark web access
dark web market list dark web links
deep web drug store drug markets dark web
ampicillin 500mg capsule cost
blackweb darknet websites
dark web websites dark net
tor markets 2023 how to get on dark web
dark web sites links https://heinekendrugsonline.com/ dark market 2023
tor markets 2023 tor market
darknet market links free dark web
darknet marketplace dark web markets
tor marketplace dark market onion
darknet site dark websites
dark internet dark web links
dark internet dark market url
darknet drug market darknet search engine
dark market url darknet market list
darkmarket dark web drug marketplace
blackweb official website dark internet
dark web drug marketplace deep web drug store
blackweb free dark web
cheap buspar
darknet drugs darknet links
dark web market darknet markets 2023
deep web markets dark web sites links
darknet market best darknet markets
dark web websites darknet links
robaxin 500 mg coupon
dark web site dark web sites links
dark market 2023 deep dark web
tor market links darkmarket link
deep web sites tor marketplace
how to access dark web darknet drugs
tor dark web darknet seiten
tor market url darknet site
dark web access deep web drug links
dark market list darkmarket url
dark websites darknet drugs
dark web site darknet drug store
real metformin mexico
tadacip 20 tablet
generic ampicillin
tetracycline rx
tor markets 2023 dark website
drug markets onion dark web sites
darknet drugs darknet seiten
tor markets darknet drug links
how to get on dark web deep web drug url
dark web access dark web sites links
how to get on dark web darknet seiten
tor markets links dark markets
dark markets tor markets 2023
tor market url drug markets dark web
how to get on dark web dark web search engine
dark website drug markets dark web
darkmarket url tor marketplace
dark web markets https://heinekendrugsonline.com/ darknet sites
tor markets how to get on dark web
black internet darknet links
darknet sites dark market link
darknet websites blackweb official website
deep web drug url drug markets onion
bactrim ds generic
dark web markets dark web market list
darkweb marketplace tor market url
cialis 5mg daily buy online
dark web websites onion market
tor market url darknet drug market
darknet markets 2023 dark web site
dark web sites links dark web markets
deep web drug store darknet seiten
dark market 2023 darknet websites
vermox canada
dark websites dark markets 2023
black internet darknet marketplace
cymbalta price uk
dark website dark market url
lasix water pill 20 mg buy no prescription
dark web search engine darknet market list
dark web markets darknet market lists
albenza 200mg
dark web market how to get on dark web
buy tetracycline
dark web websites how to access dark web
dark website darknet markets 2023
cymbalta duloxetine hcl
buy generic cymbalta canada
deep dark web dark web market
darknet sites dark market list
dark web markets dark web websites
darknet sites black internet
black internet tor market links
tor markets 2023 darknet websites
dark web site bitcoin dark web
darkmarket 2023 dark web search engine
darkmarket 2023 darknet drugs
dark web market links darknet drug links
deep web drug markets dark market onion
dark web sites links tor darknet
darknet markets 2023 dark market link
trental price
the dark internet tor markets
darknet market lists dark web link
darknet drug market dark web markets
darknet search engine https://heinekendrugsonline.com/ darknet websites
darknet markets 2023 dark website
darknet drug market dark net
dark internet darknet drugs
dark net dark web sites
tor darknet deep dark web
darknet drug links dark markets 2023
dark web sites darkmarket 2023
darknet sites tor market
darknet market deep web drug markets
how to access dark web deep web sites
buy tetracycline online without a prescription from canada
darknet market links deep web drug links
tor marketplace black internet
darknet seiten darknet market links
dark internet darknet marketplace
phenergan prescription australia
accutane price nz
darknet market deep web drug store
dark web site drug markets dark web
dark net dark market onion
deep web links dark markets
silagra 25 mg
colchicine no prescription
deep web search dark net
darknet search engine how to access dark web
black internet deep web drug links
dark web links deep web links
dark market link darknet seiten
darknet markets 2023 drug markets dark web
dark websites dark web market list
Contemplating daily 80 mg accutane? Learn about its advantages at 80 mg accutane daily.
darknet markets darknet seiten
darknet links darknet links
synthroid.com
dipyridamole medication
dark web drug marketplace how to access dark web
darknet markets deep web links
dark web sites dark web link
tor darknet dark web market
generic medrol online no prescription
dark market list drug markets onion
darknet drug market dark web websites
bitcoin dark web dark web market
darkmarket link tor market
darknet seiten darknet market list
onion market black internet
deep web drug url dark net
blackweb https://heinekenonlinedrugs.com/ deep web drug store
tor market links dark web search engine
tor market url dark web websites
darknet market lists drug markets dark web
deep web drug links how to get on dark web
buy kamagra oral jelly online usa
synthroid 137 mg
darknet site darknet links
toradol for kidney stones
tor market dark web websites
accutane uk pre ion generic accutane costs can you buy accutane over the counter
dark net dark web market list
ampicillin 250
deep dark web dark internet
dark market link darknet site
darknet markets best darknet markets
azithromycin 500 mg coupon
dark website tor markets links
dark web sites links darknet drug market
tor markets links darkmarket list
darknet drug market dark web sites links
darknet market links blackweb
dark web links darknet market links
tor markets links best darknet markets
darknet markets tor markets
dark web markets dark market list
darknet seiten free dark web
darkmarket 2023 how to get on dark web
dark web markets how to get on dark web
synthroid 5 mcg
dark web sites links deep dark web
darknet seiten free dark web
dark web markets darknet sites
darknet seiten how to access dark web
darknet market darkmarket
dark net deep web drug markets
tor darknet bitcoin dark web
darkmarket 2023 deep web drug markets
dark web link deep dark web
darknet drug market dark web market
deep web drug url darknet seiten
how to access dark web dark market list
dark web market dark web links
dark market url https://heinekenonlinedrugs.com/ dark markets
elimite generic
deep web drug links dark web sites
dark internet deep dark web
darkmarket list tor darknet
darkmarket darknet drug store
dark web links dark market link
d X ray crystal structure of the DIX homodimer PDB 4WIP cheap finasteride Where To Find Arimidex For Sale
tor market url darknet marketplace
synthroid 125 mcg price
darkmarket darkmarket list
dark website darknet markets 2023
darknet marketplace free dark web
darknet market list dark web sites links
dark website dark web access
dark web drug marketplace tor marketplace
darknet markets 2023 dark net
tor marketplace dark websites
drug markets dark web how to access dark web
dark web site dark market url
drug markets dark web dark markets
onion market deep web drug markets
deep web sites dark markets
dark web links darkweb marketplace
dark web search engine dark web market list
dark markets 2023 darknet drug market
tor dark web drug markets onion
darknet drug links deep web search
tor market url darknet websites
buy aurogra 100
deep web markets tor markets
darkmarket link darknet markets
tor market url tor market
darknet sites tor markets 2023
drug markets dark web dark market onion
dark markets darknet market lists
deep web drug markets bitcoin dark web
dark web market dark web websites
tor marketplace the dark internet
dark web sites links drug markets onion
amoxicillin uk price
darknet site tor markets 2023
deep web markets onion market
plavix pills medication
foreign pharmacy no prescription
dark market 2023 dark website
dark web search engines free dark web
dark web search engines dark markets
tor dark web best darknet markets
darknet search engine dark website
dark internet how to get on dark web
tor dark web tor markets links
colchicine 0.6 coupon
bitcoin dark web tor dark web
dark market url dark website
prozac uk price
how to access dark web darkweb marketplace
best darknet markets dark web market links
deep web links dark web websites
tor marketplace dark websites
where to buy motilium 10mg
darknet site darknet drugs
dark web site free dark web
dark market link deep web drug links
tor darknet deep web drug url
valtrex order
dark internet darknet market lists
darknet sites bitcoin dark web
darknet websites darkmarket list
deep web drug store deep web sites
orlistat online uk
motilium usa
darknet websites darkmarket
dark web search engine darknet market list
dark web link tor darknet
atarax hydrochloride
hydroxychloroquine sulfate 200mg tablet
dark websites darknet site
dark market link dark web search engines
deep web drug markets deep web markets
darknet marketplace darknet search engine
dark web market links darknet marketplace
phenergan 25mg tablets
dark website dark websites
dark websites darknet markets
darkmarket url darknet seiten
dark net tor market url
darknet drug market dark web markets
best darknet markets bitcoin dark web
dark web drug marketplace blackweb
dark web link dark web sites links
dark market url darkmarket link
darknet markets free dark web
darknet markets dark web link
darknet search engine tor markets
darknet sites tor markets 2023
blackweb official website dark market 2023
If you suffered an auto accident injury, then you should speak with an attorney about seeking a car accident settlement. Though it may benefit your claim to file a personal injury lawsuit, most car accident cases are resolved through an insurance settlement, not at trial. Texas drivers are legally required to carry insurance that covers bodily injuries and property damage. If the insurance system works as it should, then you should receive an insurance payout from the liable party’s insurer that covers your economic and non-economic injuries. A statute of limitations is a period of time during which you have to file your accident injury lawsuit. If you fail to file your lawsuit during that window, you can lose your right to seek compensation. In Texas, this window is 2 years from the date of the accident. Though, there are a few exceptions to this rule, so the deadline may change depending on the details of your case. That’s another reason why it’s important to have an experienced Austin, TX, car accident lawyer from our Lorenz & Lorenz team in your corner. We’re on top of it!
http://ventasdiversas.com/user/profile/1165949
States with the highest annual mean wages for lawyers include: The most recent salary distribution curve, released by NALP in 2015, revealed that salaries between $40,000 and $65,000 accounted for about half of all reported first-year lawyer salaries. Yet, the mean salary for all graduates was $83,797, and the mean salary for all full-time law firm jobs was $94,591. The mean salaries were heavily influenced by salaries of $160,000, which accounted for about 17 percent of reported salaries. Relatively few of the reported salaries for the Class of 2015 were close to either mean salary. Top paying metropolitan areas for Lawyers: States with the highest annual mean wages for lawyers include: In court, Attorneys use their knowledge of the law and court procedures to advocate for their client in front of a judge and oftentimes a jury. The Attorney follows procedures and court room etiquette to argue against an opposing Lawyer represtenting their own client. Depending on the case, a trial may take several days or a few hours to resolve. Sometimes Attorneys help the parties involved reach an agreement before going to trial, avoiding court altogether. This is called “settling out of court.”
darknet market deep dark web
buy synthroid online canada
bitcoin dark web tor darknet
dark websites how to access dark web
toradol 10mg discount
darknet links darknet market
deep web drug store dark web drug marketplace
tor market url tor market links
drug markets dark web dark web market list
dark web search engines onion market
avodart soft capsules 0.5 mg
tor markets 2023 dark markets
how to access dark web free dark web
darknet markets deep web links
dark market 2023 darknet seiten
dark web search engine darkmarket url
tor markets darknet markets 2023
avodart canada buy
tor market url darkmarket 2023
deep web drug url bitcoin dark web
darknet market links dark web drug marketplace
darknet market drug markets dark web
tetracycline tablets price
darkmarket list dark net
darkmarket link deep web search
dark web market list https://heinekenonlinedrugs.com/ tor market links
dark web site how to access dark web
dark market link darknet search engine
tor dark web deep web drug markets
glucophage 750 mg
vermox united states
blackweb official website drug markets onion
cost of albenza medication
darknet market darknet market list
kamagra canada
darkmarket url drug markets onion
dark web sites links darknet site
dark web sites darkmarket link
darknet marketplace darknet drugs
darkmarket tor markets links
darknet market lists dark market
dark web drug marketplace blackweb
dark market link dark web link
dark net tor market
dark market dark web drug marketplace
darknet marketplace darknet site
darknet markets deep web drug links
dark web drug marketplace how to get on dark web
dark markets 2023 darknet market lists
tor market dark web link
dark web market bitcoin dark web
dark markets 2023 tor darknet
tadacip 20mg
blackweb official website dark markets
how to access dark web drug markets onion
black internet dark markets 2023
deep dark web dark market
drug markets dark web darknet search engine
onion market tor markets
darknet market list darkmarket 2023
dark market list tor marketplace
blackweb official website dark web sites
darknet marketplace dark market 2023
tor darknet tor marketplace
deep dark web drug markets onion
darknet websites dark web sites links
dark internet onion market
blackweb official website dark market url
blackweb official website darknet links
deep dark web dark web sites
darkweb marketplace https://heinekendrugsonline.com/ free dark web
darknet market list how to get on dark web
dark web search engines dark market 2023
darknet markets 2023 dark web websites
tor marketplace darknet seiten
drug markets dark web tor dark web
drug markets onion dark web sites links
darkmarket list darkmarket link
dark market onion darknet market lists
tor markets links darknet drug market
free dark web dark market link
dark market url dark web market
dark web market list deep web drug links
dark web access tor markets links
order albendazole
dark web market how to access dark web
darknet drug store darknet search engine
drug markets onion dark market url
darkmarket tor market links
deep web drug links darknet market
synthroid price
dark web site dark websites
darknet drug links dark market link
tor markets links dark web market list
dark web search engines deep web sites
dark web sites tor darknet
darknet sites dark web links
deep dark web dark web sites links
dark web websites deep web drug store
dark internet darknet links
medrol cost in uk
dark markets darknet search engine
deep web search deep web search
deep web drug store deep web search
dark web links dark web markets
onion market dark web websites
dark market list deep web drug links
darknet drug market dark web sites links
deep web drug links deep web drug links
dark websites bitcoin dark web
darknet market list darknet market lists
tor market links best darknet markets
dark web markets https://heinekendrugsonline.com/ darknet market links
darknet market list dark web drug marketplace
phenergan gel cost
darkmarket url darkmarket list
dark web links dark markets 2023
darknet drug store dark web market list
zofran over the counter
tor markets links drug markets dark web
dark web market list darkmarket url
dark net dark web access
how to get on dark web dark web sites
drug markets onion darkmarket link
dark website deep web search
onion market dark market list
deep web search dark web sites links
online pharmacy birth control pills
dark market 2023 deep web drug url
avodart sale
darknet marketplace dark web links
blackweb official website dark web site
dark market darkmarket link
tor market tor market links
dark web site darkmarket url
free dark web best darknet markets
dark web markets darkmarket
dark website free dark web
dark internet darknet search engine
darknet sites darkmarket list
darknet market links tor darknet
deep web search tor marketplace
best darknet markets dark market
darknet drugs dark markets 2023
darknet drug links darknet sites
darknet markets 2023 tor dark web
vermox medication
zoloft cheapest price
xenical capsules price
phenergan cream australia
darkweb marketplace deep web drug markets
dark market onion tor markets
darknet site tor darknet
albenza canada
dark web drug marketplace tor dark web
xenical online nz
drug markets onion dark web search engine
darkmarket list darkmarkets
dark web drug marketplace free dark web
dark web search engines dark web market list
darknet markets darknet drugs
darkmarket list blackweb official website
the dark internet dark market onion
buy cymbalta
darkmarket url dark web link
medrol 5mg
darknet markets darknet market
dark web websites darknet drug market
darkmarkets tor market
buy albendazole australia
deep web drug url https://heinekenonlinedrugs.com/ drug markets dark web
dark web market list darknet market
darkmarket link deep dark web
dark web market drug markets dark web
deep web drug store dark web websites
darknet market links darkmarket
buy tadacip 10
darknet drugs darknet sites
where to get cheap prozac
tor marketplace darknet links
bitcoin dark web dark market onion
dark web market darknet market
darkweb marketplace darknet sites
darknet seiten darkmarket
tor marketplace darkweb marketplace
drug markets onion darkmarket link
tor market url dark web sites
tor markets darkmarket url
vermox tablet india
dark market list the dark internet
deep web drug store darknet drug store
deep web search dark market onion
how to get on dark web dark market link
darknet markets 2023 darkmarket url
darknet markets dark market url
glucophage 1000 mg tablets
darknet site dark web websites
deep web search black internet
dark website how to access dark web
darkmarket link tor market links
strattera 18 mg buy online
buy lasix online no prescription
dark market list dark market list
darknet site best darknet markets
dark market dark web site
darknet drug store dark web search engines
darknet links tor marketplace
dark web sites links bitcoin dark web
dark web links how to get on dark web
tadalafil cheapest price
darknet market dark web search engines
black internet dark web market
dark web drug marketplace darknet marketplace
tor markets links darknet site
deep web search darkweb marketplace
tor market links darknet drug store
dark web search engine darkweb marketplace
deep web drug url tor markets 2023
bitcoin dark web onion market
drug markets dark web bitcoin dark web
can you buy antabuse over the counter
deep web drug url blackweb
darknet seiten dark web websites
darkmarket 2023 darknet websites
dark market link darknet drugs
darkweb marketplace deep web markets
tor darknet how to access dark web
darknet sites darknet drug store
darkweb marketplace onion market
dark web websites dark web access
how to get on dark web darknet market lists
dark market onion tor darknet
free dark web tor dark web
darknet websites tor markets links
tor marketplace darkmarket list
darknet marketplace dark web sites links
dark websites dark market onion
darknet drug links deep web sites
darknet site deep web drug url
deep web drug links deep dark web
tor marketplace dark web search engines
dark web websites darknet seiten
darkmarket 2023 drug markets onion
dark web sites links drug markets onion
dark web sites deep web drug store
deep web search free dark web
tor dark web dark website
zofran 8mg
dark market dark internet
darkmarket list dark web sites links
darknet search engine deep web drug links
deep web drug url dark web sites links
cost robaxin 750 mg
tor darknet dark web sites
lexapro 30 mg tablet
deep web drug url dark website
deep web sites darknet market lists
deep dark web darknet marketplace
darknet drug links how to get on dark web
black internet dark web sites links
darknet marketplace darknet drugs
tor market dark website
darknet drug links tor dark web
darkmarket 2023 free dark web
blackweb official website dark market
dark web sites dark markets 2023
deep web drug store dark web sites
darkmarkets onion market
darknet seiten onion market
darkweb marketplace darkmarket
free dark web dark market onion
dark web markets dark web search engines
dark market link darknet markets 2023
dark web drug marketplace dark web websites
darknet sites darknet market list
dark market link free dark web
blackweb free dark web
darknet market lists dark market onion
dark market 2023 drug markets dark web
medrol 4mg price in india
darkmarket url dark web site
bitcoin dark web best darknet markets
buy antabuse online
deep web search dark website
dark web websites darknet drugs
dark market onion dark web sites links
dark web market links dark market link
deep web drug url tor marketplace
darknet marketplace free dark web
strattera for sale
medrol 16mg tablets
best darknet markets darkmarket url
drug markets dark web tor markets
dark web drug marketplace dark internet
darkmarket link deep web markets
dark market link drug markets onion
darknet markets dark website
dark market list darknet market lists
onion market darknet websites
deep web drug url dark market
abilify 20 mg coupon
free dark web darknet markets
darknet market deep web markets
blackweb darknet drug market
dark web link blackweb
dark web access darkmarkets
deep web markets onion market
dark web search engines dark web market links
deep web sites dark web links
dark market url dark websites
dark net darknet drug store
dark web links blackweb official website
darknet websites dark web sites
dark website darknet seiten
how to access dark web darknet market
deep web drug links dark web search engine
deep web drug store free dark web
dark market 2023 darknet links
dark market darknet market lists
darknet marketplace blackweb
purchase amoxicillin online
dark market onion darknet drugs
80 mg accutane
dark internet dark web link
dark web site deep web markets
clomid online sale
no prescription needed canadian pharmacy
how to get on dark web darknet drugs
darkmarket list darknet site
dark web sites links deep web search
darkmarket dark net
darknet websites darknet drug store
celebrex cap
dark market onion tor markets
deep dark web deep dark web
darknet market blackweb official website
budesonide 250 mcg
dark web links deep web links
blackweb dark websites
buy clindamycin pills online uk
darknet seiten deep web drug url
deep web sites darknet sites
deep web search deep web markets
darkmarket link darknet drug market
buy sildalis
deep web search dark market 2023
dark web links darknet markets
darknet market lists onion market
darknet market deep web drug store
tor market url darknet market lists
can i buy nolvadex otc
darknet sites dark web site
darknet drugs dark web websites
disulfiram price
deep dark web dark market url
darknet search engine dark web search engine
dark market list deep web sites
best darknet markets tor market
vardenafil online no prescription
dark web sites links deep dark web
dark web sites links deep web drug markets
dark websites deep web search
dark web websites dark market link
deep web drug url dark web market
drug markets dark web tor markets 2023
darknet websites drug markets onion
deep web drug store deep web drug store
tor markets 2023 free dark web
darknet websites dark web links
singulair 10 mg buy online
augmentin 500 price
deep web drug store darkmarket 2023
blackweb official website dark website
sildalis cheap
dark market list dark web links
tor dark web darknet search engine
darknet links darknet market
darknet markets 2023 darknet seiten
darkmarket 2023 darknet market list
dark market onion darknet sites
darkmarket link free dark web
tor market links dark websites
can you buy disulfiram over the counter
darknet markets 2023 deep web drug markets
dark net tor darknet
darkweb marketplace darknet markets 2023
dark web link dark web site
darknet drug links darknet markets
elimite cream 5
dark internet dark web link
dark market tor darknet
dark market onion tor dark web
dark web market dark markets 2023
tor marketplace darknet websites
dark net tor markets
dark web search engine darknet marketplace
dark market onion best darknet markets
deep web links dark web access
deep web markets tor market url
darkmarket dark market link
deep web drug markets dark market link
tor dark web tor dark web
darknet seiten darkmarket list
darknet market lists darkmarket
darkweb marketplace dark web websites
cleocin generic
dark markets dark web site
deep web search dark market
best darknet markets darkmarket url
dark web links dark web sites links
how to get on dark web drug markets onion
deep web drug store dark web access
dark market 2023 dark web links
deep web drug links tor markets
buy malegra 50
darkmarket list deep web markets
darknet sites blackweb official website
deep web sites onion market
dark web drug marketplace dark internet
tor darknet deep web drug links
dark web search engine tor markets 2023
elimite price
buy malegra 100
darknet links tor market
tor markets links dark web search engine
best darknet markets dark market onion
dark web market onion market
darknet drugs darknet search engine
how much is elimite cream
darkmarket url onion market
bitcoin dark web deep dark web
darknet market tor darknet
sildenafil 20 mg prescription
dark website darknet websites
dark web websites darknet market links
best darknet markets dark web site
dark net darkmarkets
darknet seiten free dark web
onion market drug markets onion
deep web drug store dark internet
dark market url darkmarket list
dark web links dark market list
I’m gone to inform my little brother, that he should also go to see this webpage on regular basis to take updated from newest information.
deep dark web darkmarket 2023
dark web search engine dark web sites
drug markets onion darkmarket 2023
bitcoin dark web dark web links
deep web drug store tor marketplace
deep web drug markets dark web markets
blackweb darknet markets
darknet drugs tor markets
amoxicillin 250 mg tablet
darknet drug market dark web access
dark web market dark net
clindamycin penicillin
blackweb drug markets onion
tor markets black internet
darknet marketplace darkmarket url
deep web sites onion market
dark market 2023 darknet search engine
darknet search engine dark web market list
dark market onion dark market link
antabuse canadian pharmacy
clomid price in usa
daily cialis
budesonide 200 mg
darknet links darknet drug links
tor market links dark website
dark web drug marketplace darknet markets
blackweb official website dark websites
darknet websites tor markets
acticin 5 cream
blackweb darknet market
deep dark web tor dark web
tor market tor marketplace
darknet market list dark web links
darknet marketplace dark web sites
tor market url darknet drug market
darknet marketplace darknet markets 2023
darknet drug market dark web drug marketplace
deep dark web dark internet
dark web links dark web market links
dark web access tor market url
amoxicillin uk brand name
malegra 200
dark web search engines darkmarket 2023
deep web links dark internet
darknet sites darknet markets 2023
elimite
permethrin cost
rate online pharmacies
dark market onion darkmarket link
dark internet deep web markets
tor markets links darknet seiten
black internet darkmarkets
tor market links dark web search engine
tor darknet tor market links
lasix without prescriptions
malegra 180 on line
dark web sites deep web links
how to access dark web darkweb marketplace
blackweb official website dark web search engines
darknet websites deep web sites
darknet markets deep web sites
darkmarket list deep web markets
amoxicillin pills
tor markets 2023 dark web market list
free dark web dark web market links
dark web sites links tor market links
dark web link dark web drug marketplace
darknet market links dark web site
lasix 2 mg
northern pharmacy canada
drug markets onion deep web drug url
tor market url tor markets links
dark net dark markets
how to get on dark web dark web search engines
dark web market tor market
dark internet tor markets 2023
dark web websites dark market onion
dark web websites how to get on dark web
blackweb official website darknet market list
buy clindamycin gel
dark market onion deep web drug links
tor marketplace darknet site
dark website onion market
deep web links tor markets 2023
lasix coupon
aurogra 100 mg
generic for celebrex
dark market list dark internet
piroxicam 20
darkmarket link tor markets links
darknet markets 2023 dark markets 2023
tor darknet deep dark web
dark market 2023 dark websites
darknet seiten dark web search engine
dark web drug marketplace darknet drug market
darkmarket url deep web drug markets
darknet marketplace deep web search
darknet markets 2023 blackweb official website
darknet markets 2023 darknet drug store
dark market url dark markets 2023
dark market deep web drug url
darkmarket dark market url
darkmarket list darknet search engine
buy antabuse without prescripition
dark market link tor marketplace
darknet markets dark web market list
dark website darkmarket link
zestoretic 20 25mg
tor market url tor market
avodart 50 mg
malegra 150
dark market 2023 onion market
nolvadex online india
dark web site dark web drug marketplace
deep dark web dark websites
darknet site dark market url
dark web site free dark web
dark web markets dark market url
best darknet markets bitcoin dark web
budesonide 6 mg
antabuse prices
where can you buy clomid over the counter
lasix 12.5
deep web links darknet search engine
bitcoin dark web darknet seiten
deep web drug store darknet market lists
blackweb official website blackweb official website
dark web access dark web markets
dark markets deep web markets
levitra 20mg on line india
dark market dark internet
darkmarket list drug markets onion
dark web search engines darkmarket link
dark web sites dark web sites
dark net dark websites
deep web sites dark net
malegra 100mg
darknet drug market dark market link
tor markets 2023 how to access dark web
dark web search engine deep web drug markets
where can i get nolvadex
amoxicillin 500mg capsules online
darknet market list darkmarket list
dark market list dark web site
dark websites dark websites
dark web market links dark web market
dark internet darknet site
tor market links dark web websites
dark web links dark markets
darknet drug market tor markets links
dark web site onion market
tor markets 2023 darknet markets
celebrex 20 mg
amoxicillin 3109
piroxicam 20 mg
darknet links tor dark web
clomid online paypal
levitra cheapest price
augmentin 875 price in usa
dark net dark market onion
blackweb official website darknet market lists
how to get on dark web darkmarket
dark market 2023 deep web markets
the dark internet blackweb
dark market url deep web sites
free dark web darknet drug store
generic accutane prices
deep web links darknet links
usa price for tamoxifen
tor marketplace tor markets
levitra cost in usa
darknet sites tor marketplace
celebrex 50 mg tablet price
best darknet markets dark internet
dark market link dark web market
darknet market lists darkmarket
how to access dark web darknet sites
deep web drug markets darkmarket list
deep web sites dark market list
lyrica 5
dark market 2023 darknet market list
darkmarket url dark web drug marketplace
dark website dark web websites
bitcoin dark web dark web link
dark web link darknet market
tor market url darknet search engine
online clomid
blackweb darknet markets
black internet darknet markets 2023
where to buy nolvadex usa
dark web sites links tor markets links
darknet sites darkmarket list
clindamycin 600 mg tablets price
citalopram india
cheap levitra canadian pharmacy
fluoxetine buying online
dark market url dark market list
cost of permethrin cream
clomid rx discount
darknet markets best darknet markets
amoxicillin otc price
levitra online order
budesonide cost australia
dark market dark net
bitcoin dark web tor market url
darknet marketplace darknet market links
drug markets dark web drug markets dark web
darknet websites darknet markets 2023
vermox canada
darknet sites dark web site
darknet market list tor markets links
dark markets dark market url
deep web search tor markets
dark web site dark market url
free dark web darknet market
deep dark web best darknet markets
dark web links darknet seiten
dark markets 2023 deep web drug markets
order anafranil online
deep web links dark web market
buy vardenafil online without a prescription
tor market darkmarket list
tor market url drug markets onion
dark web market list darknet market list
tor markets links deep web drug url
darkmarket 2023 darknet market lists
feldene buy
dark web sites darkmarket list
darknet sites deep web drug store
dark web access dark web market list
darkmarket link deep web drug markets
darknet drug links dark websites
dark market onion darknet market lists
dark market darknet market
deep web drug store tor markets 2023
clomid 50 mg tablet price
darknet drug links darknet market lists
darkmarket list tor market url
darknet drug store dark web sites
free dark web dark web link
how to get antabuse online
darknet search engine darknet drug store
zestoretic 20 25 mg
darknet market https://alldarkmarkets.shop/ deep web drug url
darknet links tor darknet
deep web drug url darknet links
darknet websites dark markets
darknet drug market dark web link
deep web drug links drug markets onion
dark web drug marketplace deep web links
dark market deep web search
darknet market tor markets
tor markets links dark market
clomid capsules
darkmarket link darknet marketplace
tor darknet dark web market links
dark web access dark websites
darknet websites dark web sites links
darknet markets tor markets links
darknet market links dark web sites
tor markets links best darknet markets
bitcoin dark web bitcoin dark web
dark web search engine blackweb official website
deep web links darknet market links
dark web sites links darknet sites
budesonide 3 mg
dark web search engine deep dark web
deep web sites best darknet markets
darknet market lists dark markets 2023
drug markets dark web darknet sites
dark web market links dark websites
darknet market list darknet links
dark web links dark web drug marketplace
dark web access darknet market
darkmarket 2023 darknet drug links
dark market link tor dark web
darknet marketplace onion market
darknet markets dark web link
darknet links dark websites
dark web links darkmarket link
deep dark web dark web sites links
dark web market list deep web drug store
dark markets 2023 darkweb marketplace
tamoxifen pill
dark web search engine darkmarket
darkweb marketplace darkmarket
deep web search dark market list
dark net onion market
darknet markets dark website
piroxicam price in india
dark website deep dark web
darkmarket url darkmarkets
onion market https://onion-dark-markets.shop/ dark web markets
dark web market links darknet drug links
darknet websites dark web market list
blackweb official website darknet market
antabuse online canada
blackweb official website darknet search engine
darknet links darknet drugs
onion market dark web links
dark market dark web sites links
dark market tor market links
tor market url dark web websites
blackweb drug markets onion
how to get on dark web how to get on dark web
how much is celebrex
dark web search engines deep web sites
darknet markets 2023 darkmarket url
drug markets onion darknet drug market
seroquel 300 mg
clindamycin tablet india
darkmarket 2023 deep dark web
dark markets 2023 dark web sites
deep web sites dark web access
darkweb marketplace darkmarket link
darknet drugs dark internet
generic feldene
darknet links tor market
levitra for sale australia
deep web links dark market onion
dark web link tor markets
dark web link darknet drug links
darkmarket 2023 dark markets
dark web access tor market url
tor markets 2023 darknet sites
lasix tablets uk
deep web sites drug markets onion
phenergan brand name
darknet drugs how to get on dark web
tor dark web dark web websites
dark web search engines dark web drug marketplace
darknet markets 2023 darknet search engine
darknet links tor market url
dark market 2023 deep web links
amoxil 500mg
deep web drug url dark web drug marketplace
deep web drug links darknet market lists
deep dark web deep web drug url
darkmarket link tor markets 2023
avodart 0.5 mg tab
deep web drug links best darknet markets
nolvadex tablets
augmentin 800 mg
buy 150 mg clomid
dark internet darknet drug links
darknet seiten darknet links
deep web search dark web search engines
blackweb darkmarkets
dark market link bitcoin dark web
deep dark web https://alldarkmarkets.shop/ darknet market links
darknet markets 2023 dark web access
darknet market links darkmarket list
onion market drug markets onion
dark web market links dark internet
darknet market list tor market
generic clomid over the counter
tor market tor marketplace
dark web sites links darknet websites
dark web sites darknet seiten
dark websites dark market
how to get clomid over the counter
tor markets links dark net
deep web markets dark web markets
dark websites tor darknet
dark web search engines deep web drug markets
deep web drug markets how to access dark web
darkmarket 2023 dark markets
where to get nolvadex in canada
deep web drug links free dark web
free dark web dark web market
vermox tablets uk
free dark web darknet site
bitcoin dark web deep web markets
celebrex from canada without a prescription
drug markets onion deep web search
deep web links darknet market links
buy tamaxophen
darknet websites deep web markets
deep web markets dark net
darkmarkets darknet market lists
deep web markets darknet drug links
tor marketplace deep web search
how to access dark web deep web links
darkmarkets dark markets 2023
dark web links deep web drug markets
dark market url dark web site
dark market url dark market url
deep web search dark market url
dark web markets tor markets links
drug markets onion darknet market
tor market url darknet drug links
tor market url darkmarket
darknet sites darknet sites
dark web search engine dark web market
darknet search engine dark web access
darknet drug links https://onion-dark-markets.shop/ dark web drug marketplace
cialis soft 20mg
dark web market list tor market url
dark web market deep web markets
dark market 2023 darkmarket
tor marketplace deep web drug markets
darknet market lists blackweb official website
dark web access dark market link
deep web markets tor market url
tor markets tor markets links
darknet links darknet marketplace
tor markets 2023 free dark web
blackweb official website darknet seiten
blackweb darknet markets
darknet markets best darknet markets
best darknet markets tor market
darknet drug market darknet markets 2023
deep web markets best darknet markets
deep web sites dark website
darknet drug links darknet market links
deep web search drug markets onion
drug markets onion tor dark web
deep web links black internet
darkmarket url deep web markets
dark market url tor market links
deep dark web dark market 2023
dark markets 2023 blackweb official website
dark web link tor marketplace
dark websites dark web market list
dark markets darknet marketplace
darkmarket url darkmarket link
deep web drug store how to access dark web
dark internet darknet search engine
darkmarket list dark market
feldene capsule 20mg
the dark internet dark websites
dark markets 2023 darknet market links
darknet site dark web search engine
dark web sites links https://alldarkmarkets.shop/ deep web links
dark web link tor markets links
deep web drug markets tor markets 2023
darknet links deep web search
dark market 2023 darknet drug store
deep web drug store darkmarket
darknet market links tor markets 2023
dark web sites tor markets
dark market list dark web market list
dark internet darknet site
deep web drug links darkmarket 2023
darkmarket 2023 free dark web
deep web sites tor marketplace
tor darknet dark web markets
dark market link how to get on dark web
dark web sites dark web markets
dark web search engine darknet market list
the dark internet dark market
bitcoin dark web dark web links
dark web sites drug markets dark web
darknet drug market tor market url
blackweb official website tor markets
tor marketplace darkmarket link
deep web drug links tor markets
dark websites dark web site
dark market list darknet drug store
tor marketplace free dark web
dark markets 2023 dark web sites links
dark web site dark web drug marketplace
darkmarket list darknet markets
canada discount pharmacy
dark web drug marketplace dark website
tor markets tor markets links
can you buy elimite cream over the counter
blackweb official website tor markets links
dark market onion dark internet
the dark internet darknet search engine
tor markets links dark web markets
tor dark web darkmarket 2023
tor marketplace darknet drug market
darknet drug market https://onion-dark-markets.shop/ deep web drug markets
darknet market lists dark market onion
tor dark web darkweb marketplace
deep dark web deep web sites
dark market onion blackweb official website
dark websites dark net
buy levitra in canada
darknet markets 2023 tor market
nolvadex for men
darkmarket link tor markets 2023
dark web sites how to get on dark web
bitcoin dark web dark web market links
tor market links tor market url
malegra 100
tor market how to access dark web
dark web search engine darknet search engine
dark market onion bitcoin dark web
best darknet markets onion market
tadalafil 40 mg online india
tor darknet best darknet markets
darkmarket url darknet seiten
dark market list deep web links
cost of tamoxifen in canada
darkmarket list dark market 2023
darkmarket list onion market
darknet drug market deep web drug url
dark markets darknet markets
zestoretic generic
deep web sites darknet seiten
blackweb official website dark web links
dark web market links dark web access
deep web drug links darkmarket
dark markets darknet markets
deep dark web how to get on dark web
darkmarket url dark web links
darknet drug market dark web access
tor markets dark web access
how to get clomid uk
dark market link dark websites
tor darknet how to get on dark web
drug markets dark web darknet drug market
cheapest pharmacy canada
celebrex 200mg
darknet links dark market url
how to access dark web dark market
dark website https://alldarkmarkets.shop/ dark market list
tor market links darknet websites
tor markets 2023 deep web markets
dark web search engine darknet links
blackweb official website deep web markets
bitcoin dark web darknet market
dark market url tor markets links
tor markets 2023 dark websites
disulfiram 200 mg
tor market darknet seiten
dark market link deep web links
order celebrex
dark market 2023 deep web search
the dark internet how to access dark web
where to buy generic viagra over the counter
dark market url deep web search
darkweb marketplace drug markets onion
darknet websites darknet drug store
tor markets tor market
darknet drug market deep web search
darknet marketplace the dark internet
darknet market links darknet links
dark web sites links darknet seiten
dark web sites dark web sites
lasix tablets online
clindamycin tablets 300mg
blackweb the dark internet
darknet market darknet markets 2023
dark website dark market
malegra cheap
dark web market links tor darknet
best darknet markets tor market
dark web market links dark market list
dark web search engine dark web sites
dark market 2023 the dark internet
free dark web darknet drug links
dark web market onion market
dark markets 2023 deep dark web
best darknet markets darknet sites
buy cheap sildalis fast shipping
dark web links drug markets dark web
dark market onion dark market link
drug markets dark web dark web search engines
tor market url blackweb
darknet drugs dark web sites links
tor markets links https://alldarkmarkets.shop/ darknet drug market
best darknet markets dark market 2023
tor markets links dark websites
darknet market lists darkmarket
dark web market list dark market list
tor markets links free dark web
dark market link darknet drug links
antabuse online
dark internet deep web markets
dark web markets drug markets onion
dark market onion dark web market list
deep web drug url darknet markets
purchase cheap viagra online
tor market url dark markets 2023
tor market dark web market
dark web market links deep web drug store
blackweb darkmarket
tor darknet darknet drug links
My spouse and I stumbled over here different page and thought I might as well check things out. I like what I see so now i’m following you. Look forward to checking out your web page again.
darknet marketplace blackweb
deep web drug links darknet drug market
dark markets 2023 dark web search engines
blackweb dark web links
darknet websites darkmarket link
onion market darkmarkets
tor markets links dark market 2023
tor market links deep web search
dark web market list dark internet
darkmarkets darknet websites
tor markets darknet market lists
dark website dark web site
zestoretic tabs
dark web market list dark internet
zestoretic price
price of tetracycline tablets in india
dark web market links dark markets
deep web links drug markets onion
deep web drug markets darkmarket 2023
darknet markets dark web search engine
darknet markets darknet markets
dark web market list deep web drug store
tor market darknet market lists
darknet market links how to get on dark web
dark web market deep web links
blackweb official website darknet seiten
tor market url https://onion-dark-markets.shop/ dark web access
30 trazodone 50 mg
celebrex 100mg capsule
dark web websites deep web drug links
deep web search deep web markets
dark web search engine tor marketplace
darkweb marketplace dark market list
cheap clomid online
darkmarkets black internet
tor darknet tor market
tor markets dark market url
deep web drug links dark websites
dark market onion dark web drug marketplace
darknet sites darknet search engine
viagra 200mg uk
dark web link dark web market
deep web drug links dark web drug marketplace
dark web sites onion market
dark web market links darkmarket link
dark web markets tor dark web
dark websites deep web drug store
dark web market deep web sites
dark market 2023 darknet websites
dark market 2023 how to access dark web
darknet market darknet drug market
deep web sites deep web drug links
darknet markets dark web link
dark web link darknet markets 2023
purchase augmentin
generic cialis fast delivery
darknet search engine darknet links
dark web market list black internet
darknet market links darknet drug links
can you buy tamoxifen over the counter
dark web drug marketplace darkmarket link
darknet seiten deep dark web
tor marketplace deep web drug url
dark web markets darkmarkets
tor market links darknet market links
deep web drug url tor market
cost amoxicillin 875 mg
darkmarkets darkmarkets
dark web search engines deep web drug store
dark net drug markets onion
blackweb official website darkmarket url
piroxicam cap 20mg
piroxicam tablets price in india
accutane for sale canada
dark web market darknet drug market
dark web market tor market
нужна медицинская справка
deep dark web deep dark web
darknet market lists https://alldarkmarkets.shop/ darknet markets 2023
darknet links dark web drug marketplace
how to get on dark web dark web search engines
dark web sites links darknet seiten
darknet seiten tor markets links
bitcoin dark web darknet seiten
darkmarket darknet drug store
buying cialis
dark web search engines dark market url
where to buy cheap clomid online
black internet dark market
drug markets onion dark web market
dark web markets tor market links
darkweb marketplace dark market
darknet market dark web websites
dark web search engine how to access dark web
dark markets 2023 dark web drug marketplace
onion market dark web search engine
darkweb marketplace darkmarket list
budesonide price in india
tor marketplace tor dark web
deep web drug store best darknet markets
darknet seiten deep web sites
clomid pills canada
buy lasixonline
tor markets links darknet drug links
darkweb marketplace darkmarket list
darkmarket link dark web link
dark website darknet market list
tor marketplace dark websites
darknet drug links deep web sites
tor markets 2023 blackweb official website
dark web drug marketplace darkmarket 2023
black internet darknet drug store
tamoxifen 20 mg
darknet sites drug markets dark web
deep dark web blackweb
darknet drug links darknet websites
onlinepharmaciescanada com
dark web markets dark web markets
blackweb darknet websites
tor market deep web drug store
feldene 10 mg tablets
darknet websites deep web drug url
tamoxifen tablets for sale
dark web search engine darknet websites
darknet market links dark market link
tor marketplace dark web link
online pharmacy store
dark web market https://onion-dark-markets.shop/ dark web sites
dark web websites tor market links
budesonide 3
zestoretic 20 12.5 mg
dark market list darkmarket list
tor markets 2023 dark web market
deep web drug links darknet site
dark web markets free dark web
cialis female viagra
dark websites deep web markets
dark web search engines dark market url
dark website darknet links
dark market link darknet markets
darknet sites dark web search engine
darknet market lists darknet sites
clomid cost uk
black internet darknet drugs
darkmarket link tor darknet
tor markets 2023 deep web links
dark web link dark web websites
dark web market darknet markets
darkmarkets darknet market list
free dark web tor market url
dark internet tor marketplace
tor market dark web markets
nolvadex for sale uk
dark web market list blackweb
how to access dark web darknet seiten
deep web drug markets tor markets
levitra no prescription
dark web market list dark market onion
darknet drugs dark web drug marketplace
deep web links dark market onion
darknet drug market tor markets links
deep dark web tor market links
darknet drug store darknet drug links
tor market url deep web sites
tor market dark market 2023
onion market dark market list
darkmarket 2023 deep web sites
dark web access https://onion-dark-markets.shop/ best darknet markets
tor markets darknet site
darknet markets 2023 deep dark web
accutane prices uk
dark market link darknet search engine
darknet market list dark market
dark web links blackweb official website
darknet drug store darknet market lists
dark web markets dark web market list
darknet market deep web drug store
darkmarket 2023 deep web search
tor markets 2023 darknet marketplace
tor markets drug markets dark web
dark web markets darknet drug store
the dark internet tor marketplace
dark markets 2023 dark market onion
darknet markets 2023 darknet markets 2023
darknet websites deep web drug markets
dark web drug marketplace dark web market
deep web links deep web drug markets
tor market url dark web search engine
darknet drug links darknet market lists
purchase tamoxifen online
tor darknet dark market list
dark web search engine dark web sites links
deep web drug store darknet websites
dark web sites darknet seiten
black internet tor marketplace
darknet site dark web search engine
generic levitra buy
blackweb black internet
viagra prescription usa
canadian pharmacy online ship to usa
deep web drug links dark market url
darknet sites darknet site
generic acticin
the dark internet tor marketplace
how to access dark web drug markets onion
best darknet markets tor dark web
darkmarket link dark market onion
budesonide 200
bitcoin dark web drug markets dark web
darknet websites darknet market list
dark market https://alldarkmarkets.shop/ dark market list
darknet market dark market url
deep web drug links darknet search engine
amoxicillin 825
darkmarket 2023 deep web markets
dark web market links darknet market list
dark web site darknet drug store
disulfiram tablets in india
deep web drug url how to get on dark web
darknet market list deep web markets
drug markets onion dark web access
dark market list darknet sites
darkmarkets dark web links
darkmarket url darknet market lists
dark web search engine darkmarket url
dark internet dark market list
deep web links dark website
dark markets deep web drug url
dark web markets tor markets 2023
dark web markets deep dark web
darknet drug store darkweb marketplace
piroxicam over the counter
Thanks in favor of sharing such a pleasant idea, post is nice, thats why i have read it fully
darknet drugs darknet seiten
antabuse price uk
darknet market list drug markets onion
dark market url dark web market list
malegra fxt
darkmarket link dark web search engines
generic tadalafil us
dark website darknet market list
dark web search engine deep web drug url
deep web drug links darkmarket link
darkmarket 2023 tor markets
clindamycin gel coupon
buy generic viagra
dark web market list how to get on dark web
dark market 2023 dark market
darkmarket url deep web drug markets
deep web links dark web market
darknet drugs darknet market list
darkmarket 2023 dark market link
bitcoin dark web black internet
dark web links dark web market
dark market onion darknet search engine
dark website dark market url
deep web sites darknet seiten
dark market 2023 dark web search engines
drug markets onion tor markets 2023
deep web drug store free dark web
darknet sites https://alldarkmarkets.shop/ deep web search
darkmarkets tor marketplace
deep web markets how to access dark web
darkmarket darknet market links
free dark web dark net
darkweb marketplace dark internet
darknet seiten drug markets dark web
darknet drug market darknet markets
buy clomid tablet
dark markets 2023 tor market links
darknet search engine tor marketplace
deep web sites free dark web
best darknet markets free dark web
tor marketplace darknet search engine
onion market dark net
darknet drug links dark web drug marketplace
amoxicillin 1000 mg
deep web sites dark web links
darkmarket list darknet drugs
darkmarket black internet
how can i get clomid over the counter
tor markets darknet site
darknet drug links dark web links
dark market 2023 darknet drugs
darkweb marketplace dark web drug marketplace
drug markets onion dark market onion
darknet sites dark web access
darkmarket list darknet marketplace
dark web search engine how to access dark web
dark web sites darknet sites
dark web access dark market
darknet markets dark markets 2023
cleocin for sinus infection
darknet search engine deep web markets
darknet drug store deep web links
tor marketplace tor darknet
tor marketplace darknet site
dark web websites best darknet markets
deep dark web deep web drug markets
darknet site darknet market lists
robaxin in usa
darknet market links darknet markets
where to get generic cialis
clomid 100 mg tablet
acticin 5
darknet markets 2023 darknet market links
darknet sites free dark web
best darknet markets dark web sites links
dark web site deep web sites
buy malegra 25 mg
tor market dark web search engines
darkmarket 2023 darknet market links
dark website how to access dark web
deep web markets darkmarket list
darkmarket list tor marketplace
dark market link dark net
darknet market list dark web drug marketplace
dark web market list deep web links
darknet search engine darknet site
darkmarkets darknet links
darknet market links dark markets 2023
darkmarket url tor dark web
zestoretic online
tor market tor market links
darknet seiten darkweb marketplace
darkmarket list dark market onion
darknet drug links dark net
feldene tablets 20mg
dark websites dark web sites links
darknet search engine best darknet markets
blackweb darknet markets
tor marketplace darknet search engine
dark market url deep web drug links
tor markets dark markets
darkmarkets tor market
tor darknet darknet market links
feldene gel otc
dark web market darknet drug links
darkmarket dark web site
darknet marketplace darkmarket 2023
dark internet deep web sites
tor markets 2023 dark web sites
mail pharmacy
tor marketplace dark web market links
dark web market deep web links
darknet drug links dark web links
elimite purchase
buy cheap sildalis fast shipping
viagra in usa prescription
darkmarket darknet drugs
how to access dark web free dark web
darknet drug store darknet market
darknet market list deep dark web
dark web sites darkweb marketplace
darkmarket link tor darknet
celebrex 20 mg
darknet search engine deep web search
zovirax acyclovir
malegra fxt in india
cialis online for sale
buy clomid online pharmacy
black internet deep web markets
dark markets 2023 deep web search
us pharmacy no prescription
darknet search engine https://alldarkmarkets.shop/ darknet markets
darkweb marketplace dark web market
lyrica tablets 25mg
bactrim
strattera tablets
meclizine 25 mg cost meclizinex.com
darknet marketplace dark web link
dark website dark web sites links
metformin cost in usa
paroxetine 5 mg tablet
over the counter antabuse
bactrim capsule
buy generic valtrex without prescription
dark web sites links https://alldarkmarkets.shop/ how to access dark web
how to purchase amoxicillin online
where to buy amitriptyline online
tor markets links darkmarket list
amitriptyline drug 1500 mg
buy cheap bactrim
accutane 40 mg
zanaflex online
buy cheap generic valtrex
how to get on dark web deep web search
tor markets 2023 darkmarket link
how much is zofran 4mg
where can i buy generic valtrex
cost of amitriptyline uk
atarax tablet 10 mg
prazosin for insomnia
clomid australia online
tor market url https://onion-dark-markets.shop/ deep web drug url
darknet search engine blackweb
best modafinil
amoxicillin rx coupon
dark market url drug markets onion
atarax tablet medication
buy modafinil 200mg online
buy erectafil 20
budesonide canada
clomid over the counter south africa
bactrim tablet
how to get on dark web darknet market links
elavil for interstitial cystitis
what is aviator game aviator game tricks how to play aviator on sportybet
928 zofran
provigil online no prescription
darknet search engine https://onion-dark-markets.shop/ how to access dark web
tor dark web deep web drug links
prazosin 1 mg tablet
how to access dark web dark website
dark internet drug markets dark web
budesonide tablet brand name
antabuse online
propranolol 10mg cheap
cost of accutane in canada
paroxetine medicine in india
amoxil 875 125 mg
dark web sites dark web search engines
darkmarkets darknet drugs
dark market 2023 darknet marketplace
blackweb official website darkmarket link
tor markets links black internet
dark web search engine dark web market list
dark web search engines dark web site
deep web drug store blackweb
dark web market links dark web market links
dark web markets darkmarket url
dark market drug markets onion
onion market dark markets
onion market darknet search engine
darknet drug links dark web market links
free dark web dark market
dark web search engines dark websites
deep dark web tor darknet
how to access dark web darknet search engine
buy atarax 25mg
dark web sites darknet marketplace
deep web sites darknet links
antabuse canada
paxil anxiety
darknet drugs https://onion-dark-markets.shop/ tor market
darkmarket link darknet markets 2023
darkmarket list tor market url
zanaflex drug
dark web market list dark website
dark web link darknet markets
dark markets 2023 dark web market links
dark web websites dark web websites
deep web sites darkmarket url
darknet market links dark web markets
dark web search engine free dark web
dark web market links dark web websites
dark web sites links dark web websites
tor market url dark web drug marketplace
darknet drugs darknet links
onion market dark market list
darknet drugs dark web websites
tor markets links darknet links
darkmarket 2023 darknet sites
darknet sites darknet site
darknet websites drug markets dark web
darknet market dark market onion
darknet websites dark web links
dark web sites links darknet drug market
the dark internet darknet drugs
drug markets dark web deep web drug markets
darknet sites drug markets onion
tor dark web blackweb
dark web links dark web link
darknet sites deep dark web
tor dark web dark web sites
tor market url deep web drug links
paroxetine generic india
drug prazosin
blackweb deep web search
darknet market list how to access dark web
blackweb darknet search engine
dark web markets dark net
darknet drug market tor market url
dark web markets https://alldarkmarkets.shop/ blackweb
darknet drug market tor markets 2023
buy atarax 25mg
darknet sites deep web links
dark markets tor markets
dark web access tor markets 2023
drug markets dark web darknet drug links
dark market link dark website
deep web markets tor markets links
darkmarkets dark internet
darknet drug market deep dark web
darkmarkets darkmarket list
deep web markets tor market links
onion market darknet websites
darkmarkets darknet market links
best darknet markets dark market link
deep dark web deep web drug store
darknet marketplace dark web access
dark web sites darknet markets
dark market onion darknet drug store
darkmarket list dark market 2023
tor markets links drug markets dark web
dark web websites darknet drug market
deep dark web dark web site
tor marketplace dark markets 2023
deep web search dark web drug marketplace
dark market 2023 deep web search
tor darknet the dark internet
drug markets dark web blackweb official website
deep web markets dark web drug marketplace
darknet marketplace the dark internet
best accutane cream
valtrex medicine
darknet markets darknet websites
deep web drug store darknet sites
buy accutane 2017
drug markets onion tor market url
buy accutane pills online
drug markets onion dark market onion
darkmarket 2023 darknet links
the dark internet darknet market list
tor market url tor darknet
dark web site tor markets links
dark markets darknet sites
deep web drug url dark web websites
darknet market lists dark website
dark web site dark net
darknet market lists dark net
dark web search engines darknet drug market
dark web websites https://onion-dark-markets.shop/ darkmarket 2023
deep web search tor market links
dark web link dark web markets
deep web drug markets free dark web
darknet market lists tor market links
deep web markets deep web drug store
dark website black internet
dark web search engines dark website
darkmarket list dark web access
blackweb darkweb marketplace
deep dark web dark web search engine
valtrex order uk
darknet marketplace deep web markets
buy tetracycline online india
where can i buy lyrica cheap
dark website darknet drug market
how to get antabuse online
deep web search blackweb official website
dark market deep web drug markets
tor market tor darknet
darknet links dark market list
dark web sites tor dark web
dark markets 2023 darknet links
onion market tor markets links
tor markets links tor market links
darknet sites dark internet
budesonide brand name
dark web site darknet drug links
dark markets 2023 dark markets
dark web websites dark internet
darknet market links darkmarket list
dark market list how to access dark web
blackweb dark market 2023
tor market links dark web sites links
darkmarket list tor darknet
amoxicillin 250mg price
tor market dark website
dark market url darknet drug store
darknet search engine darknet markets
dark websites drug markets dark web
buy erectafil 5
dark web sites links tor markets links
bactrim tabs
dark web search engines deep web drug url
dark website black internet
dark websites darknet markets
darknet marketplace dark websites
tor markets 2023 darkmarket list
deep web drug links dark market link
4mg zanaflex
bitcoin dark web dark net
darknet marketplace https://alldarkmarkets.shop/ drug markets dark web
dark web market dark web access
darknet seiten dark website
dark web drug marketplace dark web sites
deep web drug store darknet websites
dark web markets best darknet markets
darknet market dark web sites
darknet drug links dark web sites
dark market onion tor markets links
blackweb official website dark markets
darknet site tor darknet
darkmarket 2023 how to get on dark web
dark web links tor market links
free dark web darkmarket
tor market links dark web drug marketplace
deep web markets deep dark web
deep web sites the dark internet
clomid discount
order valtrex from canada
bitcoin dark web dark market 2023
drug markets onion dark web search engines
paroxetine generic drug
amitriptyline uk brand name
dark websites tor dark web
darknet websites deep web drug url
darknet drugs darknet market links
provera clomid
deep web markets darknet market links
deep web links dark net
dark web sites darkweb marketplace
http://meclizinex.com/ order generic meclizine 25 mg
darknet marketplace darknet links
dark internet darknet markets 2023
darknet links tor market
atarax for children
darknet drug links darkmarket url
deep web markets darkweb marketplace
dark market dark websites
drug markets onion tor market url
darknet site darknet seiten
elavil canada
deep web markets tor marketplace
deep web drug links tor market
tor markets links blackweb official website
darknet sites darknet websites
tor markets links deep web drug store
deep web markets tor darknet
onion market free dark web
dark internet darknet markets 2023
dark web sites links https://onion-dark-markets.shop/ tor market url
drug markets dark web dark website
lexapro 5mg cost
deep web sites darknet drugs
tor dark web darknet links
darkweb marketplace tor markets links
dark market 2023 dark web access
dark web websites dark web markets
onion market deep web markets
blackweb official website how to get on dark web
buy xenical online cheap
dark internet dark web market list
propranolol 80mg
darknet sites deep web search
bactrim 200mg
metformin no prescription
darkmarkets darknet market
darknet marketplace dark net
clomid no prescription
dark market dark market url
dark web search engines free dark web
dark web markets darknet market
dark web site tor markets links
dark web market dark market link
dark web websites dark web links
dark market onion tor market
dark web drug marketplace deep web drug markets
darknet site dark net
darknet market tor market links
darkmarket link darknet site
tor market url tor markets 2023
onion market darkmarket link
darkmarket link tor market links
over the counter valtrex
how to access dark web tor dark web
dark web market list free dark web
dark web drug marketplace darknet search engine
tor marketplace darkmarket
tor markets links deep web drug store
black internet darknet drug market
augmentin 875 generic price
darknet market list darknet drugs
dark web site tor markets links
darknet drug store darkmarket link
tor market darknet search engine
dark web market list blackweb official website
tor dark web darknet marketplace
darkweb marketplace https://onion-dark-markets.shop/ dark web websites
tizanidine pill
darkmarket list dark web market
dark web market dark markets 2023
deep web links the dark internet
dark market 2023 darknet market lists
darknet drugs tor markets 2023
metformin 500 mg for sale
darknet websites deep dark web
drug endep 10
dark market onion darknet market
darknet drugs blackweb official website
dark market onion darknet markets 2023
tor markets 2023 tor dark web
deep web sites deep web markets
best darknet markets darknet drugs
darknet site dark net
darkmarket list darkmarket url
dark website tor market url
tor market links dark market link
drug markets dark web blackweb
darknet sites darkmarket 2023
darkmarket list darknet seiten
otc atarax
darkmarket 2023 drug markets dark web
dark market url how to access dark web
tor market url deep web drug markets
dark web site dark market 2023
darknet market deep web markets
buy bactrim pills
dark web access deep web drug url
anafranil 25mg capsules
best darknet markets dark web drug marketplace
darknet market lists deep web links
darknet market links dark internet
propranolol 10mg cheap
lyrica cost in india
darknet market lists https://alldarkmarkets.shop/ tor market url
darknet markets drug markets onion
deep web sites darknet market links
lyrica tablets
darknet marketplace deep web sites
buy clomid online safely uk
dark web search engine dark web sites
best darknet markets darknet markets
tor marketplace darkmarket 2023
darknet drug market darknet drugs
paxil for premature ejaculation
tor markets dark market list
metformin for sale canada
zanaflex 2mg tablet
deep dark web tor marketplace
dark websites deep web sites
tor market dark web market
darknet drug links darknet websites
darknet market lists tor darknet
dark market link dark market link
tor markets links dark websites
darknet sites darkmarket url
dark website tor markets
tor markets links darknet site
dark market onion tor market links
free dark web tor dark web
dark market 2023 tor dark web
darkmarket tor market url
dark market list tor darknet
tor market darknet markets
deep dark web deep web markets
buy lyrica online europe
tor markets links tor darknet
darkmarket 2023 dark internet
darknet site darknet markets 2023
dark internet https://onion-dark-markets.shop/ darknet market lists
darknet drug market darknet drug store
budesonide brand name
medicine augmentin 625
dark web drug marketplace bitcoin dark web
deep web drug links darknet sites
drug markets onion dark website
darkweb marketplace darkmarkets
dark market deep web drug markets
dark markets 2023 tor market url
blackweb how to get on dark web
deep web drug markets dark web drug marketplace
darknet drug links darkmarket list
dark market url darknet drug links
dark markets dark markets
order lyrica
drug markets dark web dark markets 2023
darkmarket 2023 darknet markets
tor market links darknet drug market
dark markets 2023 onion market
tor markets links dark web websites
deep web links darkmarket link
tor market url dark markets
darknet search engine dark market url
darknet site bitcoin dark web
dark web markets dark websites
darkweb marketplace dark web access
darknet markets 2023 darknet drug links
dark market link tor markets 2023
can i buy lyrica online
deep web search darknet sites
how to get on dark web darknet market links
dark website how to access dark web
tor market url dark web search engines
darkmarkets dark market 2023
how to get trazodone prescription
deep web sites https://onion-dark-markets.shop/ dark web market links
deep web markets dark market
buy innopran
atarax medication
dark websites darknet seiten
baclofen no preciption
price lyrica 300 mg
darknet markets 2023 deep web drug markets
deep web links darknet market lists
darknet drugs dark web search engine
darknet drugs best darknet markets
clomid canada
dark web search engine the dark internet
dark web websites blackweb official website
dark web search engines darkmarkets
dark web market dark web link
the dark internet dark web links
deep web search darkmarket 2023
dark markets darknet websites
how to get on dark web tor market
dark internet how to get on dark web
darknet markets 2023 deep web search
dark web sites links darknet market links
darknet market dark web access
dark markets darkmarkets
dark web market links deep web markets
darknet markets 2023 darkmarket
darkmarket dark web sites
how to order generic valtrex
deep web links dark markets 2023
darknet marketplace tor markets 2023
darknet websites darkweb marketplace
valtrex medication online
buy clomid cheap
darkmarket 2023 darknet market lists
dark web market links how to access dark web
darknet markets 2023 tor market
darknet search engine dark web search engines
bitcoin dark web dark market url
onion market dark web market
budesonide 9 mg capsules
onion market deep web markets
tizanidine 6 mg cost
dark web websites dark market
darknet markets 2023 dark market
elavil tablet
dark market darkmarket url
dark web access https://onion-dark-markets.shop/ dark net
modafinil for sale south africa
deep dark web deep web sites
darkweb marketplace darknet markets
tor dark web darknet links
propranolol 60 mg
dark web search engine darknet sites
dark web link bitcoin dark web
deep dark web tor marketplace
tor markets links darkmarket
tor dark web deep web drug markets
darknet market lists dark web market
best darknet markets tor markets 2023
erectafil 20 mg
blackweb deep web drug links
prazosin for nightmares
darknet drug links dark net
black internet dark web websites
tor dark web dark market list
darknet drug links darkweb marketplace
onion market deep web drug url
darkmarket dark market list
darknet drug market darknet drug store
dark web site darkweb marketplace
the dark internet darknet drug store
best darknet markets deep dark web
dark internet darknet drug market
dark web sites darkmarket list
dark web market links darkmarket list
darknet market links onion market
order zanaflex online
deep web drug links the dark internet
generic zanaflex
lyrica 300 mg capsule
darkmarket dark website
deep web drug store dark web site
darkweb marketplace dark markets
dark web sites darkmarket list
dark markets 2023 dark web websites
dark internet dark web websites
tor marketplace darknet links
darknet sites the dark internet
metformin canada brand name
paroxetine cost in india
cheap propecia uk
dark web markets darknet markets 2023
deep web drug url darknet marketplace
120mg accutane
zanaflex 40 mg
the dark internet drug markets onion
dark web site tor markets
darknet market links tor market
darknet sites https://alldarkmarkets.shop/ deep web markets
elavil for neuropathy
deep web drug store darknet site
blackweb official website darkmarket 2023
black internet dark web markets
dark web sites bitcoin dark web
generic paxil for sale
the dark internet deep web sites
blackweb deep web drug links
deep web search dark web drug marketplace
dark web market links dark web site
dark web drug marketplace tor market url
valtrex 2000 mg
tor markets links drug markets dark web
bitcoin dark web darknet drug market
dark web sites darkmarket list
dark web market darknet sites
how much is disulfiram cost
atarax usa
disulfiram 250 cost
the dark internet deep dark web
tor marketplace how to get on dark web
deep web sites darkmarket
tor market links darknet sites
deep web drug markets darknet markets
dark web drug marketplace darkweb marketplace
he wasnt bitter that she had moved on but from the radish city how googles ai search could impact ecommerc
deep web links darknet market list
the dark internet deep web search
dark web access darknet search engine
darkmarket link dark web websites
atarax 25mg without script
bitcoin dark web tor darknet
deep web drug store dark web access
tor market darknet drug links
darknet drug links darknet websites
cost of generic amoxicillin
where to get metformin in canada
dark net dark websites
deep web drug markets darkmarket link
darknet websites darknet drug market
tor market onion market
best darknet markets dark market 2023
drug markets onion dark web drug marketplace
darkweb marketplace deep dark web
dark market dark market onion
dark markets deep web drug url
dark market 2023 tor darknet
dark markets dark web links
dark markets 2023 tor darknet
tor market dark web drug marketplace
dark web sites links https://onion-dark-markets.shop/ darknet sites
darknet market links black internet
dark web search engine dark market list
dark web market dark markets 2023
where to buy clomid pills
darknet drug store darknet drug store
dark market onion dark web search engine
darknet links dark market url
dark web search engines the dark internet
dark website best darknet markets
tor market links dark markets 2023
darknet drug links deep web drug store
darknet market lists dark web market list
how to get on dark web tor market url
dark web sites best darknet markets
metformin 250 mg price
buy antivert 25mg without prescription meclizinex.com
deep web sites deep web search
darknet drug links darknet search engine
darknet markets 2023 darknet search engine
buy generic valtrex online cheap
dark web market bitcoin dark web
metformin 500 mg buy
provigil best price
dark market link dark market onion
darkmarkets darknet seiten
darkmarket dark web market list
2000mg amoxicillin
lyrica rx
atarax 100mg tablets
dark web links how to get on dark web
darkmarket dark web access
propranolol pill cost
darknet sites tor market url
dark web sites dark web websites
dark web sites deep web markets
dark market link darknet drugs
darknet search engine onion market
accutane pill 30 mg
amoxicillin 500mg no prescription
tor market links darknet markets 2023
dark web sites links deep web links
how to access dark web darknet site
darknet websites darknet market list
darknet marketplace dark market
blackweb free dark web
darkmarket 2023 blackweb
deep web drug markets darknet drug market
blackweb official website darkmarket 2023
tor dark web dark website
darknet marketplace best darknet markets
darknet site darknet market links
drug markets onion tor dark web
dark market list darknet drug store
darknet search engine tor market url
darknet site dark market url
deep web drug store https://onion-dark-markets.shop/ how to access dark web
darknet market lists drug markets dark web
tor markets 2023 dark web link
paxil breast cancer
zofran generic prices
darknet market dark web websites
dark web access dark markets
darkmarket 2023 dark web sites links
tor markets drug markets onion
deep web search tor markets
Thank you very much for the information, it helped me make the right choice. https://socialsocial.social/user/aviatorgame122/
dark web websites dark website
deep web links tor market url
dark websites dark web websites
dark web access darknet market links
dark market tor markets
darknet site deep dark web
darknet search engine darkmarket
dark websites darknet site
dark web market dark market url
tor markets 2023 dark web drug marketplace
darknet market list blackweb official website
dark markets 2023 dark web sites links
antabuse medicine
darknet websites dark web site
erectafil canada
buy amoxil online cheap
dark web drug marketplace black internet
darknet sites dark market
dark market list darknet marketplace
darknet search engine darknet links
darkmarket 2023 dark web site
free dark web deep web markets
accutane price
dark markets dark market list
dark web drug marketplace dark net
deep web search darknet market links
best darknet markets darknet drug store
dark market url dark internet
best darknet markets darknet seiten
tor dark web blackweb
darknet drug market dark website
tor markets 2023 darknet markets
50 mg prednisone from canada
darkmarket link https://alldarkmarkets.shop/ dark web search engines
dark market 2023 darkmarket list
medication metformin
darknet drug market dark market list
buy amoxicillin online
provigil 300 mg
tor dark web darknet marketplace
dark web link dark web links
trazodone 125 mg
dark website tor marketplace
dark web access deep web links
deep dark web darkmarkets
black internet dark markets
dark web link tor dark web
dark website dark web markets
darknet market lists darknet market list
darknet market deep dark web
dark markets 2023 darknet market links
dark websites dark web markets
darknet market links tor marketplace
cheapest on line valtrex without a prescription
deep web sites darknet seiten
darkmarket list darknet drug market
dark market dark market 2023
modafinil pill buy
amoxicillin 500 prescription
darkmarket list darknet market lists
darknet market list darknet search engine
darknet markets dark websites
lyrica cost
darknet search engine dark web link
tor market dark markets 2023
tor market onion market
dark markets 2023 darknet markets
dark web sites deep web drug markets
black internet bitcoin dark web
dark web site tor market url
dark market list dark web websites
deep web drug links darknet market links
darkmarket dark internet
deep web sites darknet drugs
paroxetine 50mg tablets
dark website darkmarkets
augmentin discount
the dark internet dark net
dark web access https://onion-dark-markets.shop/ dark market onion
cost of paroxetine without insurance
dark web search engine dark markets
dark internet darkweb marketplace
erectafil 5
best darknet markets blackweb official website
bitcoin dark web dark internet
tor market links darknet markets
dark web site darknet markets 2023
free dark web deep web drug store
best darknet markets tor market links
dark market link onion market
deep web drug url deep web drug url
darkmarket list tor market
tor dark web darknet market
darkmarket list tor markets 2023
darknet market lists darknet seiten
erectafil
darkweb marketplace dark net
dark web search engine dark web search engines
darknet drugs dark web search engine
dark market blackweb
dark market 2023 darknet marketplace
dark market list darknet site
deep web links the dark internet
where to buy valtrex over the counter
dark market list dark web market links
drug markets dark web darknet drug market
dark web markets darknet market list
dark web websites dark market
dark web links darkmarket 2023
dark web markets darknet websites
black internet darkmarkets
tor market url darknet market
darknet site dark market list
tor market darknet drug links
zanaflex for migraines
dark web links darknet drug links
dipyridamole tablets
darknet links tor markets
tor market how to get on dark web
how to get on dark web blackweb official website
deep dark web dark web market list
dark web search engine https://onion-dark-markets.shop/ darknet site
dark web market list darknet market
darknet drug links tor markets links
tizanidine tablet generic
darknet sites dark websites
best darknet markets dark web market links
darkmarket link darknet market list
dark markets 2023 tor darknet
darknet market links deep web drug markets
darknet websites deep web drug markets
darknet search engine darknet markets
dark market link darknet drugs
dark web market darknet seiten
how to access dark web darkweb marketplace
dark web sites links dark websites
tor darknet drug markets dark web
tor darknet dark web search engines
darknet market links deep web drug url
deep web search best darknet markets
darknet marketplace darknet links
dark markets 2023 darknet market
darknet markets 2023 tor market
dark website darkmarket link
lyrica canada cost
darknet market list dark internet
darkmarket deep web drug markets
dark web market links dark web markets
generic zofran coupon
tor marketplace deep web drug markets
the dark internet darknet drug market
price of accutane in mexico
bitcoin dark web dark markets 2023
dark web search engine dark market link
free dark web how to access dark web
deep web drug links drug markets dark web
buy amoxicillin otc
darknet drug links darknet market links
darkweb marketplace darknet market list
deep web links the dark internet
dark web sites onion market
metformin online uk
This is a topic that’s close to my heart… Many thanks! Where are your contact details though?
darknet sites dark web search engines
dark market url deep web markets
bitcoin dark web dark market url
deep web markets dark market
dark web access dark web link
darkmarket 2023 https://alldarkmarkets.shop/ darknet drug market
darkmarket darknet drugs
bactrim price in india
tor market links darknet sites
dark markets tor marketplace
darkmarket url darknet drug store
atarax cost
dark internet darknet market links
trazodone generic
onion market darknet drug store
dark market url deep web markets
dark web site how to access dark web
darkmarket darkweb marketplace
darknet links darknet market lists
dark web sites dark web market
deep web links deep web markets
the dark internet deep web drug links
tor market url dark web access
deep web search dark web sites links
darkmarket dark web links
drug markets onion dark web market
darknet market lists best darknet markets
deep web drug store deep web sites
dark web market links dark web drug marketplace
dark web market links deep web drug url
deep web drug markets dark web market list
dark market link dark web markets
metformin 1mg
can you buy valtrex online
erectafil 20
tor markets tor markets 2023
dark market url dark websites
This design is steller! You obviously know how to keep a reader entertained. Between your wit and your videos, I was almost moved to start my own blog (well, almost…HaHa!) Fantastic job. I really enjoyed what you had to say, and more than that, how you presented it. Too cool!
metformin tablet price in india
deep web drug url tor markets
darkmarkets darknet drug links
bitcoin dark web tor market links
deep web drug url tor market url
drug markets onion dark web link
dark market onion darkmarkets
darkmarket 2023 dark web markets
dark web drug marketplace deep web links
darknet links dark web markets
darkmarket 2023 darkmarket link
amitriptyline without rx
how to access dark web black internet
dark web drug marketplace darkmarket list
darkmarket list darknet market lists
darknet market lists darknet market
dark web sites https://onion-dark-markets.shop/ darkweb marketplace
bitcoin dark web black internet
dark market url darknet markets
darknet site tor market url
dark markets blackweb
drug markets dark web tor market links
onion market drug markets dark web
dark web search engines deep web drug markets
tor market darknet seiten
zofran 4mg price
amoxicillin price in canada
tor markets links tor markets 2023
blackweb official website dark web market links
tor dark web darkmarket list
augmentin 500 mg tablet
dark market onion darknet site
dark market list darknet search engine
lyrica 200 mg price
antabuse cost canada
dark websites dark web market
darknet search engine onion market
where to get zofran
dark web link darknet market links
blackweb dark web websites
synthroid pills
tor darknet deep web links
dark internet darkweb marketplace
dark web market links darkmarket 2023
dark internet deep web links
dark web drug marketplace tor market
darknet drug links dark web link
dark web search engine black internet
tor markets dark web drug marketplace
dark internet the dark internet
tor markets 2023 deep web markets
prazosin for cats
dark markets darkweb marketplace
tor markets 2023 deep dark web
cheap accutane uk
dark web link deep web markets
darknet market lists deep web markets
darknet seiten dark markets
the dark internet darknet links
tor markets links dark web market links
drug markets onion darkmarket url
the dark internet dark internet
deep web links black internet
darkmarket list https://onion-dark-markets.shop/ dark market onion
deep web links dark web market
drug markets onion deep web drug links
dark web sites links deep web drug markets
deep web markets darkmarkets
dark market onion dark web sites
deep web drug url dark internet
tor marketplace darknet sites
dark web markets drug markets onion
dark web market list bitcoin dark web
deep web sites darknet market links
tor markets 2023 dark market
amitriptyline cost in india
tor darknet dark web market links
cost of augmentin
dark market onion bitcoin dark web
black internet dark web market list
dark market onion tor darknet
darkmarket list deep web drug url
bitcoin dark web tor market links
deep dark web dark web access
dark web sites drug markets dark web
meclizine 25mg pills https://www.meclizinex.com meclizine 25mg sale
darknet sites darkweb marketplace
drug markets dark web black internet
how to access dark web darknet links
disulfiram pill
dark market list dark web link
blackweb official website dark web link
darknet links tor market
inderal cost canada
dark web market list dark web link
generic valtrex price comparison
deep web sites tor markets 2023
paroxetine brand name
deep web drug store darknet drugs
dark web market list dark web links
valtrex 500mg
blackweb bitcoin dark web
dark web search engine dark web link
deep web links dark market
dark market link dark web access
dark web site darkmarket url
darkmarket list darknet drug market
darkmarket 2023 dark market list
deep web sites darknet links
buy generic valtrex without prescription
best darknet markets darknet drug store
tor market tor markets
dark web link darkmarket link
tizanidine tab 2mg
tor marketplace the dark internet
dark web site https://onion-dark-markets.shop/ darknet market list
Write more, thats all I have to say. Literally, it seems as though you relied on the video to make your point. You definitely know what youre talking about, why waste your intelligence on just posting videos to your blog when you could be giving us something enlightening to read?
5 минутная почта аременная почта Получите бесплатный временный адрес электронной почты мгновенно
deep web drug store best darknet markets
blackweb official website blackweb
dark web sites links onion market
cost of generic paxil
black internet dark market
deep web links dark website
darknet drugs the dark internet
dark web access tor dark web
elavil for headaches
best darknet markets dark web search engines
darkmarket free dark web
dark market list tor markets 2023
drug markets onion darkmarkets
darknet market list deep web drug url
darknet drug store deep web drug store
dark web market links dark web drug marketplace
valtrex without prescription com
darknet seiten darknet markets
azithromycin cream
valtrex generic in mexico
dark internet best darknet markets
how much is amoxicillin 500 mg
darkmarket darkmarket url
darknet drug links darknet market links
dark websites tor dark web
free dark web tor markets links
dark internet dark market onion
darkmarket link darknet market
dark markets 2023 dark websites
where to buy provigil in canada
darkmarket url darknet markets
deep web search dark web links
zofran coupon
blackweb dark web search engine
black internet darknet market
dark web link black internet
deep web markets darknet market links
tor dark web blackweb official website
dark web market blackweb official website
dark web drug marketplace darknet drug market
deep web sites tor marketplace
darknet markets 2023 dark web links
tor market links how to get on dark web
dark market black internet
dark web site darknet markets
darknet seiten dark market onion
darkmarket url dark market list
erectafil 20 mg price
darknet websites deep web sites
tor markets dark web drug marketplace
tor dark web dark market url
tor markets links onion market
motrin ibuprofen
blackweb official website free dark web
tor markets 2023 dark market link
darknet seiten deep web drug store
blackweb tor darknet
darknet drug market dark market link
tor markets links dark markets 2023
onion market dark web access
amoxicillin tablet price
dark market url tor markets links
motrin drug
dark websites https://onion-dark-markets.shop/ darknet seiten
dark web websites how to access dark web
tor market dark website
erectafil 20 online
darknet websites bitcoin dark web
dark web search engine darknet marketplace
drug markets onion deep dark web
dark web sites links darknet market list
best darknet markets deep web drug store
the dark internet darknet market
darknet site dark web markets
dark web access darknet seiten
darknet market list dark websites
dark web links dark market
dark web search engine tor marketplace
drug markets dark web darknet market list
darkmarket list dark market list
darknet search engine tor marketplace
valtrex 500 mg
deep web links how to access dark web
deep web sites dark internet
darknet links dark internet
buy prednisolone online uk
darknet market links darkmarket
dark web sites the dark internet
darknet marketplace deep web drug store
darknet market lists darknet drug links
bitcoin dark web tor markets links
tor markets free dark web
drug markets dark web deep web markets
erectafil 2.5
darknet market darknet site
darkmarket deep web drug markets
dark web market links black internet
darknet sites darkmarkets
dark web markets tor marketplace
darknet drug links blackweb official website
tor market dark web links
dark web site tor marketplace
darknet search engine darknet seiten
deep web drug store deep web drug links
dark market list darknet market
darkmarket 2023 dark web markets
darknet links dark market
dark web markets dark market url
dark market 2023 the dark internet
diclofenac 50 mg
blackweb official website dark web sites links
amoxicillin 200 mg tablet
darknet drugs tor dark web
onion market tor market links
dark web websites the dark internet
amoxil coupon
deep web drug links dark web links
how to get on dark web dark web markets
darknet market links dark web links
darknet market list drug markets dark web
tor dark web darkweb marketplace
atarax price in india
indomethacin indocin
dark web drug marketplace darknet websites
tor markets links how to access dark web
dark market list darknet links
tor darknet bitcoin dark web
medicine atenolol 50 mg
tor markets links darkmarket url
darknet market deep web markets
darknet market links dark market list
darknet markets darknet drugs
darknet marketplace deep web links
how to get on dark web dark market 2023
cialis professional 20 mg
dark web link dark web link
erectafil 20 mg price
deep web links tor dark web
can i buy voltaren gel over the counter in canada
darkmarket link https://onion-dark-markets.shop/ deep web drug links
dark market darknet seiten
darknet links darknet drug links
blackweb official website dark markets 2023
tor markets links darkmarket 2023
drug markets dark web dark market 2023
erectafil canada
dark web market list dark web sites links
deep web drug links deep web markets
cialis online canadian pharmacy
darkmarket url dark web site
tizanidine 4 mg tablet
dark web drug marketplace onion market
deep web drug markets tor market
deep web drug markets darknet market
darknet search engine dark web link
dark web sites links deep web links
dark web websites deep web sites
darknet market lists bitcoin dark web
darkmarket link deep web search
deep web search darknet seiten
dark internet tor marketplace
darknet sites deep web sites
darkmarket list darknet seiten
tenormin 25
deep web drug store deep web search
black internet darkmarket 2023
onion market darknet markets
darknet seiten dark market onion
xenical 42
dark market onion dark market url
darknet links darknet markets
prednisolone 20 mg brand name
darkweb marketplace tor markets 2023
bitcoin dark web darknet sites
dark web market dark web websites
darknet sites darkmarkets
A thriving Women’s Solana NFT Collection focusing on Women Empowerment and Gender Equality.
Explore 100% Handmade NFT Collectibles & support women’s Worldwide.
We are a group of world of women’s who want women’s in all fields.
This is the perfect webpage for everyone who hopes
to find out about this topic. You understand a whole lot its almost
hard to argue with you (not that I really would want to…HaHa).
You definitely put a fresh spin on a topic which has been discussed for decades.
Wonderful stuff, just excellent!
darknet drugs darkmarket
darkmarket link dark web websites
This piece of writing provides clear idea designed for the new
users of blogging, that genuinely how to do blogging.
You’ve astonishing stuff these.
www
Great blog you have got here.. It’s hard to find good quality writing like yours
nowadays. I seriously appreciate people like you!
Take care!!
deep web drug url tor market
deep web drug store deep web search
dark web sites links darknet sites
elavil for neuropathy
drug markets onion dark market
price of augmentin 500mg
bitcoin dark web tor market url
deep web drug markets drug markets onion
dark web search engine darknet marketplace
darkmarket link deep web sites
lisinopril 0.5 mg
tor markets tor markets 2023
deep web links deep web markets
darknet marketplace deep web drug markets
dark web link deep dark web
best darknet markets dark market link
deep web search darkmarket url
blackweb official website darkmarket url
blackweb darknet drug market
dark markets 2023 best darknet markets
darknet drug store tor markets
dark internet darkweb marketplace
dark web access darknet drug market
dark market url darknet drug links
dark internet dark market 2023
dark web link darknet search engine
deep web sites bitcoin dark web
deep dark web drug markets onion
darknet seiten darkmarket 2023
deep web drug store dark web market
darkmarket link blackweb official website
amitriptyline 25 mg tablet price in india
darknet market list dark website
dark web site dark market link
darknet markets drug markets dark web
This design is spectacular! You most certainly know how to keep a reader entertained. Between your wit and your videos, I was almost moved to start my own blog (well, almost…HaHa!) Great job. I really enjoyed what you had to say, and more than that, how you presented it. Too cool!
darkmarket 2023 darknet market lists
darknet market list dark web market
dark web websites deep web links
dark web search engines tor marketplace
dark web sites how to access dark web
dark web sites links darkweb marketplace
erectafil 5 mg
dark websites deep web drug store
dark web search engines drug markets onion
diclofenac cream cost
darknet market lists darknet site
dark market 2023 dark websites
darkmarket link dark web search engines
deep web search darknet markets 2023
deep web links darkmarket list
darknet drug store dark market
dark web sites links deep web drug markets
dark web links tor market
darkmarkets dark web access
darknet market darknet market lists
darknet links darkmarket url
darkmarket deep web drug url
darknet market lists dark net
tor dark web dark web market
tor markets 2023 tor markets 2023
dark website drug markets dark web
darknet seiten dark web market links
dark website darkmarkets
dark internet darkmarket
erectafil from india
tadalafil 50mg
tor market links dark markets
price of lisinopril
deep web drug store dark web market links
darkmarket blackweb official website
dark markets 2023 dark web sites
bitcoin dark web drug markets onion
drug markets onion dark market link
xenical discount
darknet links tor market
dark web search engine dark market list
deep web sites darknet marketplace
darkmarket 2023 dark web site
inderal tablet price
darknet market lists dark web link
drug markets dark web dark internet
dark markets blackweb official website
darknet drug market dark web market
deep web links dark web websites
blackweb official website darknet markets 2023
lexapro canada
dark web sites tor markets links
dark market url tor marketplace
how to get orlistat
how much is prednisolone cost
azithromycin otc
dark website tor marketplace
tor marketplace dark market 2023
tor dark web dark web websites
tor markets links darknet markets
darknet search engine onion market
darknet drug market dark market list
bitcoin dark web deep web markets
black internet dark markets
deep web markets dark website
darknet market dark market link
bitcoin dark web deep dark web
darkmarket darknet market lists
deep web search darknet drug store
ampicillin brand
deep web links dark markets
the dark internet tor markets 2023
onion market dark websites
bitcoin dark web darknet drugs
how to get metformin without a prescription
darknet market list tor markets 2023
darkmarket link dark website
amitriptyline without prescription
purchase plavix
dark web market list dark web sites links
the dark internet dark web link
dark net dark website
acticin
paroxetine 40 mg price
deep dark web dark net
free dark web tor market links
how to get on dark web deep web drug links
black internet dark internet
dark market dark websites
تخضع تجهيزات مصنع إيليت بايب Elite Pipeلعمليات مراقبة جودة صارمة للتأكد من أنها تلبي متطلبات الأداء والمتانة الأكثر صرامة.
buy meclizine 25mg pill antivert medication
dark web websites dark web links
darknet marketplace darknet drugs
darknet drug market dark web site
darknet market links deep web markets
darknet websites tor darknet
tor dark web dark web websites
darknet market list free dark web
deep web markets dark net
dark web market deep web drug links
losartan lisinopril
darkmarket url darknet drug market
drug markets onion dark web link
dark web links dark internet
deep web drug links tor market links
darknet market tor markets 2023
dark net darknet market lists
darknet markets darkweb marketplace
tadalafil 5mg online india
darknet drug store dark web search engines
black internet darknet drug links
tor market darknet market links
darknet markets darkmarket url
dark web access dark web search engines
deep web links dark markets 2023
deep web drug store darknet drug links
darknet drug store darknet drug links
dark web market links drug markets dark web
deep web drug store darknet marketplace
dark web drug marketplace tor market url
blackweb official website deep web drug url
deep web sites darknet links
azithromycin tablet price
medicine valtrex
dark net dark web market links
darknet market darknet search engine
darknet drugs dark market onion
dark web sites links dark market onion
darknet seiten deep web drug store
dark website tor dark web
tor markets how to get on dark web
prazosin 2mg capsules
free dark web tor market links
darkweb marketplace darknet markets
darknet market links darknet markets
darknet seiten darkmarket link
diclofenac 3
lexapro brand name cost
darkweb marketplace dark market url
darknet markets how to access dark web
how to access dark web deep web drug links
free dark web darkmarket
darknet seiten dark web market list
dark market 2023 deep web search
amoxicillin 500mg price in usa
acticin over the counter
darknet sites darkmarkets
discount paxil
blackweb official website deep web drug store
acticin tablet
deep web search darknet market
tor markets links dark web search engines
atenolol 10 mg cost
orlistat where to buy
darknet market list dark market 2023
dark web drug marketplace how to get on dark web
tor markets 2023 darknet drug market
where to buy acticin
dark web market list tor markets 2023
how to access dark web onion market
the dark internet how to access dark web
tor marketplace deep web markets
If some one desires to be updated with most recent technologies then he must be pay a visit this website and be up to date everyday.
darknet market lists darknet drug links
dark web websites dark web market list
darknet market dark market url
lisinopril 40 mg tablet
darknet seiten darknet site
cialis price from canada
dark market darkweb marketplace
amitriptyline 25mg price
darknet websites black internet
dark web site tor markets 2023
tor dark web tor marketplace
darknet market how to get on dark web
zofran rx
atenolol 50 price
tor marketplace dark website
darknet search engine deep dark web
tor market url dark internet
order antivert sale
dark market dark web market list
dark web sites dark web market links
darknet search engine tor dark web
should i start my college essay with a quote cheap essay writing service uk does oxford college emory require sat essay
deep web drug links dark web websites
dark websites tor darknet
dark net how to get on dark web
darknet drugs dark net
buy lisinopril online uk
deep web markets tor darknet
deep web sites tor markets
ampicillian
dark market 2023 darknet markets
dark web market links dark web search engines
ampicillin 500 mg medicine
dark market onion tor dark web
erectafil 5 mg
darkmarket link tor darknet
darknet drug links darkmarket url
retin a 0.025 cream buy online
darknet links deep web sites
dark market onion darknet site
dark markets 2023 tor markets
acticin 250
darknet seiten drug markets dark web
darknet market lists darkmarkets
darknet sites best darknet markets
deep web search dark web search engine
indomethacin 25 mg
tor dark web dark web link
darknet markets 2023 darknet drug store
dark web search engine darknet search engine
drug markets onion darknet markets
dark website darknet market lists
tor dark web dark web access
deep web drug store dark web markets
8mg zanaflex
orlistat over the counter usa
dark web search engines dark web drug marketplace
how to get on dark web onion market
dark web access dark web access
tizanidine 44
deep web drug store darknet sites
best darknet markets dark market list
dark net blackweb official website
ampicillin 15
darkmarket url dark markets
deep web drug links darkmarket 2023
orlistat hexal
darknet search engine drug markets dark web
deep web drug links dark net
dark web sites links tor marketplace
prednisolone 20 mg buy online
deep web drug url dark web search engines
darknet search engine dark net
Heya i’m for the first time here. I came across this board and I find It truly useful & it helped me out a lot. I hope to give something back and help others like you helped me.
tor marketplace dark web links
tor markets bitcoin dark web
deep web drug url tor market url
darknet marketplace dark internet
dark market url dark web search engine
dark market dark market 2023
cheapest xenical orlistat
dark web market list dark web market links
motrin 60 mg
tor markets dark web search engine
tor markets 2023 the dark internet
dark web sites links dark web sites
dark web market links dark market link
darknet drug market tor market links
acticin cream
buy combivent from canada
dark internet tor marketplace
deep web drug url deep web search
paroxetine 20 mg tablet
dark web market list tor market
tor marketplace onion market
darknet drugs dark net
darknet drugs darknet sites
proair albuterol
generic for elavil
tor market links dark market link
paroxetine cr 12.5mg
dark web sites deep web drug store
drug markets onion dark web search engine
dark web site deep web sites
tor marketplace best darknet markets
tor market url dark web search engine
tor market darknet drug links
how to access dark web blackweb official website
tenormin pills
dark markets 2023 how to access dark web
darknet market links tor markets
deep web drug url darknet drugs
dark market 2023 bitcoin dark web
deep web markets dark web sites links
retin-a over the counter
dark web search engines deep dark web
dark web access dark web market links
dark web search engines darknet market list
trental er
blackweb dark web sites
dark web markets deep web drug url
paroxetine 40 mg coupon
dark web access dark market link
dark web sites links dark market 2023
dark web site deep web drug store
deep web drug markets dark web site
darknet links deep web drug store
tor darknet drug markets onion
darknet site dark web websites
dark web drug marketplace dark web market
darknet seiten tor markets links
free dark web tor market links
tor darknet dark web markets
dark web markets darknet seiten
tor darknet dark web sites links
tor markets links blackweb
free dark web darkmarket link
lisinopril pill 40 mg
darknet drug links darknet markets 2023
darknet drug links darknet site
atenolol 25 mg price uk
dark web websites dark web market
how to get on dark web the dark internet
tor darknet darkmarket url
tor darknet free dark web
1600 mg motrin
ventolin inhaler non prescription
tretinoin cream buy
the dark internet deep web search
deep web drug store tor market
prednisolone 5mg pharmacy
buy acticin online
blackweb darknet site
dark internet darknet websites
tor marketplace dark web links
dark markets 2023 deep web links
the dark internet darknet market
Thank you very much for sharing this useful article. Do you have a deep passion for cooking or a strong desire to enhance your culinary skills? If so, look no further! We have carefully curated a collection of the finest air fryers that will take your culinary creations to the next level and completely transform your kitchen experience. For more information, visit the article.
deep web drug links the dark internet
darkmarket url free dark web
dark market list darknet site
amitriptyline 100 mg cost
dark websites darknet sites
how to get on dark web best darknet markets
darknet sites darkmarket 2023
darkmarkets black internet
darkmarket url tor market
darknet marketplace dark internet
dark web sites darknet market
darknet markets tor markets
darknet marketplace onion market
darknet drug links darknet sites
atenolol chlorthalidone
darknet market lists bitcoin dark web
drug markets dark web darkmarket
dark web sites links dark web sites
dark market link tor dark web
darknet site tor market links
tor markets 2023 dark web search engines
ampicillin 200mg
dark web links deep web search
dark markets how to get on dark web
With havin so much content and articles do you ever run into any issues of plagorism or
copyright infringement? My website has a lot of exclusive content
I’ve either created myself or outsourced but it looks like a lot of it is popping
it up all over the web without my agreement.
Do you know any solutions to help protect against content from being stolen? I’d definitely appreciate it.
deep web sites dark web markets
darknet sites dark market list
can you buy lisinopril online
tor dark web dark market link
blackweb blackweb
darkweb marketplace deep web drug url
drug markets dark web drug markets onion
darkmarket list deep web drug markets
darknet marketplace dark web access
dark market darknet market
darkweb marketplace tor market url
bitcoin dark web dark web sites
darkweb marketplace dark internet
deep web sites dark markets 2023
dark web market links dark web market list
tor darknet dark web search engine
the dark internet tor markets 2023
tor dark web darknet markets 2023
tor market links deep web sites
buy retin a paypal
ampicillin capsules price
where can i buy tretinoin online
tor market url darknet site
darknet sites deep web markets
atarax 25 mg tablet price
dark web market darknet seiten
dark web market dark market link
tor markets dark web links
budesonide 200 mg
darknet links darknet links
how to get on dark web dark websites
darknet seiten dark web link
buy acticin
buy prednisolone 5mg tablets uk
deep web sites tor dark web
darknet drug market deep web markets
dark web site tor market
darkmarket url dark market list
darknet links onion market
dark web link dark web search engine
deep dark web darkweb marketplace
deep web drug markets dark web link
darkmarket link darknet market lists
drug markets onion dark web links
dark market onion deep dark web
drug markets onion dark web access
deep web sites dark web market list
blackweb official website free dark web
dark web market list darknet market
amitriptyline 2 cream
tor markets links dark web search engine
free dark web tor market links
tor marketplace deep web sites
dark internet deep web links
meclizine 25mg tablet meclizine generic
darkmarket dark web markets
tor market how to get on dark web
indocin for sale
dark web link deep web drug links
darkmarket list dark web drug marketplace
dark web markets the dark internet
drug markets dark web darknet drug market
darknet seiten deep web drug markets
lisinopril 20 25 mg
lowest price trazodone
dark web market list tor markets
dark web links dark markets 2023
dark website deep web sites
dark web sites links darknet market lists
darknet market links onion market
tor dark web dark market 2023
darknet drugs deep web drug store
deep web drug links dark web link
cheap trazodone
trazodone 50 mg tablet
darknet drugs darkmarket url
darknet marketplace dark web links
tor market links darkmarket list
generic lexapro canada
trazodone coupon
tor market darknet seiten
buy cheap ampicillin online
amoxicillin 2000 mg
tor market links deep web sites
tor markets 2023 best darknet markets
dark website the dark internet
dark web market links dark market url
prednisolone 5mg tablets for sale
diclofenac 25mg otc
dark web search engines darknet market links
lowest price cialis
tor markets links bitcoin dark web
darknet markets dark web websites
can you buy trazodone over the counter
dark market url deep web drug url
dark web sites darknet drugs
deep web search darkmarkets
darknet market links dark internet
deep dark web dark web market links
dark markets deep web markets
dark market link darknet markets 2023
deep web sites deep dark web
darknet market list bitcoin dark web
100 mg paxil
tretinoin gel prescription cost
darknet sites drug markets dark web
tor market url darknet market links
deep web drug markets dark market link
deep dark web dark web search engine
dark market link dark web search engines
dark markets best darknet markets
dark net dark web search engines
generic atenolol
how to get on dark web darknet market
prednisolone prednisone
price for combivent
endep 25 cost
dark market 2023 darkmarket link
drug markets dark web deep web search
dark markets how to get on dark web
tor marketplace dark market 2023
dark market link tor market links
where can i get albuterol
deep web drug store dark internet
drug markets dark web blackweb
darknet links bitcoin dark web
darknet marketplace bitcoin dark web
dark market onion darknet site
blackweb dark market link
purchase stattera
dark net darknet drugs
ampicillin capsule 500mg
dark web websites best darknet markets
dark market url dark web sites links
blackweb darknet drug store
darknet drug store darknet search engine
darkmarket url dark web site
darknet websites blackweb official website
dark internet best darknet markets
dark web site darknet market
darknet markets 2023 dark website
darkweb marketplace darknet drug store
I am really happy to read this webpage posts which includes lots of useful data, thanks for providing such data.
bactrim australia
free dark web dark web market
orlistat hexal
endep 25 25 mg
darknet drug market darkmarket 2023
dark web link tor markets
40 mg amitriptyline
where can i get paxil
dark market link dark internet
darknet market lists deep web drug links
dark web search engine blackweb official website
dark web markets dark web links
darknet market lists darkweb marketplace
deep web drug url how to get on dark web
deep web links darkmarket
can you buy ampicillin over the counter
dark market 2023 deep web markets
deep web drug markets deep web drug markets
12 mg zanaflex
darknet search engine darknet search engine
dark web websites darkmarket url
darkweb marketplace blackweb official website
lisinopril cost us
darknet sites darknet market list
darknet drug market blackweb official website
darknet market list deep web search
valtrex 500mg coupon
azithromycin capsules 250mg
can i buy ventolin over the counter in australia
deep web drug markets dark websites
darknet site dark web market
darknet markets 2023 blackweb
darknet marketplace dark web search engines
dark market url dark web markets
lyrica 2.0
dark net darknet drug store
darknet site deep web drug store
deep web drug markets darkmarket list
dark web access dark market link
diclofenac brand name drug
can we buy amoxcillin 500mg on ebay without prescription
tor markets 2023 darknet sites
dark web drug marketplace dark web market
40 mg amitriptyline
atenolol 5mg
prazosin sleep aid
dark web drug marketplace dark markets
darknet drug links onion market
dark market list darkmarket
dark market url dark websites
deep web drug markets darkmarket url
tor market links deep web drug url
dark market 2023 darkweb marketplace
azithromycin 500 mg tablets
darkmarket blackweb
tor market url the dark internet
erectafil canada
dark markets 2023 dark web drug marketplace
deep web sites dark market list
dark web websites deep web links
darknet marketplace deep web drug store
deep web drug store black internet
darkmarket deep web drug markets
indocin medicine
bactrim ds
dark market 2023 drug markets dark web
erectafil 20 mg price
purchase ventolin inhaler
dark web sites links darknet drug links
xenical price in south africa
buy lexapro in mexico
dark market 2023 deep dark web
prednisolone uk
ventolin price usa
dark internet tor market url
dark web market links dark markets 2023
how to access dark web darkweb marketplace
dark market onion dark market onion
dark web site dark markets 2023
albuterol otc canada
tor markets deep web markets
where to buy cialis in usa
indocin tab
price of amoxicillin without insurance
dark web market links tor darknet
bitcoin dark web dark websites
deep web sites darknet sites
generic prazosin
trazodone online prescription
black internet darknet links
darknet market lists dark web search engines
prescription price for lexapro
drug markets onion drug markets onion
dark website dark market onion
dark net blackweb official website
drug markets onion deep web search
best price for lexapro generic
dark market 2023 bitcoin dark web
deep web drug links darknet market list
antivert for sale
buy cheap generic cialis
lisinopril 5 mg tabs
darkweb marketplace darknet drugs
drug markets dark web dark web sites
paroxetine 30 mg
amitriptyline 5 mg
how to access dark web darknet drug links
robaxin over the counter
amoxicillin generic
ventolin canadian pharmacy
diflucan cream
darkweb marketplace deep web search
darknet market darknet market links
indocin nz
dark markets 2023 deep web drug url
darknet drug market dark web market links
https://meclizinex.com/ antivert tablet
can you buy trazodone over the counter
prednisolone buy
tor market dark markets
dark markets dark net
darknet drug market darknet market
darknet drug market darkmarket url
elavil online pharmacy
tor markets 2023 dark web search engine
deep web drug links dark web markets
tor market url darkmarket 2023
dark web link deep web drug markets
buy ventolin online cheap no prescription
dark market url darknet marketplace
300 mg atenolol
indocin sr 75 mg
darkmarket 2023 darknet drug links
atenolol canadian pharmacy
drug markets dark web deep web drug store
lisinopril 20
prednisolone 20 mg buy online
dark websites how to access dark web
dark markets 2023 dark market onion
indocin 75 mg drug
tor dark web darknet markets
dark market 2023 dark web markets
buy accutane online uk
discount zestril
paxil sleep
how to access dark web deep web drug url
dark web market list dark web links
atenolol without prescription
black internet dark market url
tor market url deep web markets
darkmarkets dark market
indocin drug
albuterol asthma
darkmarket url dark markets
amoxicillin price canada
erectafil 5mg
drug markets onion dark web markets
drug markets onion darknet market links
I savor, cause I found exactly what I used to be taking a look for. You have ended my 4 day long hunt! God Bless you man. Have a nice day. Bye
valtrex 10mg
tor market dark market url
lexapro generic 20 mg
dark web search engines dark web site
diclofenac price south africa
buy ampicillin no prescription
250mg amoxicillin capsules
lisinopril 20 mg purchase
dark website tor dark web
darknet websites dark web sites links
xenical roche
paxil 2 10mg
generic of paxil
antabuse to buy
orlistat price in india online purchase
atarax generic otc
orlistat no prescription
buy lexapro from canada
ordering lisinopril without a prescription uk
desyrel tablet
elavil 20 mg
online trazodone
generic lyrica medication
trazodone purchase online
buy atenolol online uk
paroxetine hcl 40 mg
amoxicillin 5 00mg
paxil 80 mg daily
atenolol 125 mg
paroxetine 20mg discount
acticin 650
ampicillin tablet 1mg
orlistat price in india online purchase
diclofenac 250mg
prednisolone 25
augmentin 750 mg
order xenical online
indocin prescription
how to get paroxetine
What a stuff of un-ambiguity and preserveness of precious familiarity about unexpected feelings.
online clomid prescription
purchase lexapro generic
innopran cheap
indocin 50
synthroid 0.100 mg
medication atenolol 25 mg
indocin 500mg
buy generic indocin
albuterol 26 mg
Pereira de Godoy JM, Azoubel LM, Guerreiro Godoy Mde F buy cialis online with a prescription Constitutional symptoms and signs are nonspecific, the most common being fever, diarrhea or constipation, weight loss, nausea, vomiting, pain, and sensation of a mass
acticin 650
buy antabuse online without prescription
buy online xenical
atenolol online without prescription
atenolol brand name canada
buy indocin
albuterol buy online australia
0.05 retin a
colchicine cost uk
metformin 850
cost of generic augmentin 875 mg
trazodone 50 mg pills
paxil uk
trazodone hcl
Hey I know this is off topic but I was wondering if you knew of any widgets I could add to my blog that automatically tweet my newest twitter updates. I’ve been looking for a plug-in like this for quite some time and was hoping maybe you would have some experience with something like this. Please let me know if you run into anything. I truly enjoy reading your blog and I look forward to your new updates.
lisinopril 5 mg tabs
tizanidine 4mg capsules
atenolol over the counter
atenolol 100 mg tablet
lioresal 10 mg
lyrica medicine price
lioresal cheap
effexor
where to buy diflucan over the counter
tizanidine online pharmacy
When I originally commented I seem to have clicked the -Notify me when new comments are added- checkbox and now each time a comment is added I recieve four emails with the same comment. Perhaps there is a way you can remove me from that service? Thanks a lot!
effexor buy
atenolol generic
motilium 10 mg
zanaflex for sale
buy diflucan 150 mg online
buy cafergot tablets
buy levothyroxine online
gabapentin 214
synthroid tab 112 mcg
cheapest tadalafil online uk
cost of valtrex in canada
tizanidine otc
tamoxifen tablets brand name
how to buy diflucan over the counter
medicine phenergan
cafergot online
cafergot medication
accutane by mail
zestril 20
making it simple to obtain your torrents onto your mobile gadget. The site olivia wilde nude itself has over 5-million recordsdata in its archives, making it some of the distinguished online.
motilium 10 mg tablet
motilium canada pharmacy
buy tretinoin australia
vermox otc canada
lyrica 500
rx zanaflex
cialis pills for men
diflucan 150 mg price in india
zestoretic 10 12.5 mg
lyrica for sale uk
effexor 37.5
where can i buy cafergot
amoxicillin 875 pill price
buy phenergan no prescription
diflucan cost australia
nolvadex 10 mg tablet
motilium tablets over the counter
cafergot no prescription
motilium pharmacy
zestoretic
diflucan generic
viagra 50 coupon
buy diflucan without a prescription
diflucan pills prescription
buy diflucan uk
tadacip uk
lyrica 75 mg price in usa
where can i buy cafergot tablets
gabapentin 400mg cap
buy cafergot australia
motilium over the counter
atenolol 15 mg
buy gabapentin online without prescription
vermox cost
modafinil uk
baclofen 25 mg
how to purchase provigil
can i buy diflucan over the counter
I know this web site gives quality dependent articles or reviews and additional information, is there any other site which provides such stuff in quality?
nolvadex no prescription
tamoxifen arimidex
ordering cafegot
zestoretic online
order generic viagra from india
tretinoin brand name
vermox otc canada
retin a rx
zanaflex cost
gabapentin generic brand
generic sildalis
price of atenolol
gabapentin 3600 mg
where to buy valtrex generic
can you buy vermox over the counter
how to get valtrex in mexico
50 mg effexor
It’s in fact very complex in this busy life to listen news on TV, so I only use internet for that purpose, and get the latest news.
motilium medication
generic viagra prices
tizanidine 2 tablet
synthroid 05 mg
cafegot
synthroid order
zanaflex canada
diflucan 200 mg
gabapentin 300mg coupon
atenolol 10 mg tablet
modafinil for sale uk
gabapentin 6
baclofen tablets 10 mg
where to buy elimite
zestoretic 10 12.5
atenolol medicine
diflucan price in india
how to get modafinil uk
sildalis without prescription
generic tizanidine
motilium 10mg
vermox online sale
effexor 225 mg tablet
synthroid 175 mcg price
where can you buy valtrex
cafergot canada
effexor 75 mg
zofran 8 mg price
lyrica 100 mg pill
zestoretic online
buy cafergot
vermox for sale
prescription for valtrex
gabapentin brand name in usa
cafergot tablets buy online
atenolol 50 mg
tizanidine 4mg
atenolol 50 mg cost
tizanidine 2mg tablets
buy real nolvadex
cost cialis
cafergot
motilium otc usa
synthroid 75 mg price
can i buy effexor online
effexor 37.5
where can i where to buy cafergot for migraines
buy modafinil online
zestoretic 20 25
retin a cream nz
sildalis canada
Howdy would you mind stating which blog platform you’re working with? I’m looking to start my own blog in the near future but I’m having a difficult time choosing between BlogEngine/Wordpress/B2evolution and Drupal. The reason I ask is because your design and style seems different then most blogs and I’m looking for something completely unique. P.S Apologies for getting off-topic but I had to ask!
buy vermox canada
vermox without prescription
cafergot tablets
levothyroxine synthroid
otc tamoxifen
zanaflex 2mg tablets
viagra australia
cafergot over the counter
nolvadex best price
motilium cvs
buy cafergot pills
Information such as their house tackle, where they school, omegle, or who their mother and father are. Chats containing these details may be saved as a link and converted to a picture on the Omegle server along with the IP handle.
tizanidine price
lyrica capsules price
vermox 100mg tablets
175 mg synthroid
100mg baclofen
synthroid tablets uk
And in this article, omegle we’re going to talk about these video chat sites. From mere texting based applications to photo-sharing applications, and now the video chat sites. omegle video chat These websites are getting in style day by day they usually have come a long way from the past few years.
motilium
vermox tablet
tizanidine 2mg tablet price
tretinoin 005
buy silagra online in india
order effexor online
vermox 500mg price
sildenafil 105 mg
sildalis
buy trental online
zestoretic 20 12.5
lyrica 100 mg price
buy lyrica online from mexico
buy ciprofloxacin
cost of medrol
order metformin
medicine medrol
how do u write an essay buy nothing day essay essay writing help for eng 101 farmington ct
best price for cymbalta
allopurinol cost uk
phenergan vc
ciprofloxacin over the counter canada
cheapest suhagra
propranolol 20 mg cost
medrol 500 mg
phenergan price
allopurinol online pharmacy
suhagra 50 mg tablet online purchase
generic atenolol 50 mg
cafergot 1mg 100mg
allopurinol 30 mg
medrol 5mg
otc generic cialis
buy cymbalta in india
cheap cymbalta generic
levitra india price
price of stromectol
medrol 16g
glucophage buying
buy allopurinol online
price of levitra in india
propranolol how to get
medrol generic
prazosin 5 mg capsules
suhagra 100mg price in india
atenolol 100 25 mg
prazosin anxiety
cymbalta generic
accutane rx
cipro generic cost
medrol online
metformin singapore
cafergot cost
tizanidine medicine
cost of neurontin
Paneliści biorący udział w debacie zgodnie podkreślali, że studenci, pozyskując wiedzę, stają się jednocześnie łącznikami między biznesem a światem nauki. Pan Casino oferuje również regularne promocje i bonusy dla istniejących graczy. Te bonusy mogą obejmować pan kasyno free spin, oferty cashback i bonusy reload. Często zdarzają się codzienne lub cotygodniowe promocje, z których gracze mogą skorzystać, a kasyno posiada również program lojalnościowy, który nagradza graczy za ich ciągłą opiekę. Pan Kasyno oferuje gry tylko od jednego developera – Microgaming, jednak jest ich ponad 500, dlatego ostatecznie na wybór nie powinniśmy wybierać. Niestety, nie są dostępne tu gry z krupierem live. Warto natomiast obserwować panel po prawej stronie. W ramce znajdziemy tam informacje o ostatnich wysokich wygranych, z możliwością przejścia od razu do zwycięskiej gry. Łatwo się w ten sposób zorientować, na jakich automatach grają inni.
http://www.gabiz.kr/g5/bbs/board.php?bo_table=free&wr_id=51712
Serwis internetowy GG bet w ostatnim czasie robi prawdziwą furorę wśród fanów szeroko rozumianego hazardu. Nasza strona internetowa wystartowała w 2016 roku i jest zarejestrowana na Cyprze. Na początku skupialiśmy się przede wszystkim na serwowaniu usług na zakłady sportowe. GG Bet był pierwszym wysokiej jakości bukmacherem o profilu e-sportowym. Ogromny sukces związany z nieustannie wzrastającym zainteresowaniem sceną e-sportową pozwolił na prężny rozwój portalu. W kompleksie Hotelu Arłamów uprawiać można aż 33 dyscypliny sportowe, w tym również gry zespołowe. Dla naszych Gości regularnie organizujemy wiele atrakcji i zabaw tematycznych, na terenie całego hotelu. Otwieramy również szerokie horyzonty i oferujemy wycieczki krajoznawcze czy fotograficzne na terenie Bieszczad.
over the counter allopurinol in mexico
aurogra 100 for sale
buying propranolol online
where to buy lyrica
tenormin 50 mg price
can you buy metformin over the counter in australia
lyrica 2019
Today, I went to the beach with my kids. I found a sea shell and gave it to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She put the shell to her ear and screamed. There was a hermit crab inside and it pinched her ear. She never wants to go back! LoL I know this is completely off topic but I had to tell someone!
cafergot pills
levitra prescription online
levitra 50mg tablets
aurogra 100mg tablets
buy propecia online canada
aurogra 200
generic lyrica online
propranolol 1000 mg
tizanidine 2 tablet
metformin 500 mg buy
glucophage cost in india
allopurinol 300 mg brand name
atenolol prices
zanaflex 4 mg medication
cymbalta 60mg
buy generic cymbalta 60 mg
can you buy lyrica online
cafergot canada
india levitra
cheap celebrex 200mg
buy suhagra 50 mg online india
lyrica prescription coupon
propranolol 10 mg price
cafergot 1 100 mg
After checking out a few of the blog articles on your website, I honestly appreciate your way of writing a blog.
I saved it to my bookmark webpage list and will be checking back in the near future.
Take a look at my website as well and let me know your
opinion.
buy lyrica online from mexico
propecia canada price
ネットショッピングでは、ほとんどがコンビニ後払い・銀行振り込みに対応しています。 チャージ・支払い方法は、Steam公式サイト・スマホアプリ・Steamクライアントのいずれも、まず「アカウント詳細」画面で「Steamウォレットに追加」を選択します。チャージ金額を設定後、クレジットカード・PayPal・Pay-easy・コンビニ支払い・Steamウォレットコード・Steamプリペイドカード・銀行振込・WebMoneyから、支払い方法を選択しましょう。 また、コンビニでPayPal残高をチャージすることもできません。そもそも日本では、PayPalに入金すること自体できません。支払い・送金の度に、PayPalに登録してあるクレジットカードもしくは銀行口座からお金が引き落とされる形になります。 Paypalをチェックしてください。 よくあるご質問 (FAQ)【お支払い】 コンビニ決済では、下記のコンビニエンスストアにて簡単にお支払ができます。 (ローソン、ミニストップ、デイリーヤマザキ、ヤマザキデイリーストア、セイコーマート[北海道・関東地区]、ファミリーマート) Paypalの決済画面へ遷移しますので、お持ちのPaypalアカウントでログインしていただき、決済を行なってください。 お気に入り 注文・支払い コンビニ決済の場合、注文日から7日以内※期限内にお支払いが完了されない場合、ご注文は自動キャンセルされますので、予めご了承ください。
https://damienksqn295295.buyoutblog.com/20652002/オンラインカジノ-100ドル
・ワンダーカジノ系列(ユースカジノ・ミラクルカジノ)のオンラインカジノを比較してみた 検索ボックスにお探しのコンテンツに該当するキーワードを入力して下さい。それに近しいページのリストが表示されます。 コンビニエンスストアによる特定任意講習手数料納付方法はこちら WOWPASSとは別ですが交通カードチャージなどにも備えて現金も多少は持っておきたいもの。ホームページからメールを登録しておくことで、現金両替手数料20%オフのクーポンコードを受け取ることができます。 クイーンカジノは、入出金手数料が一切かからないオンラインカジノです。 自社オリジナルのベッド・マットレスの通販専門店 オンラインカジノは、必ずしも全てのカジノが日本円に最適化されているわけではありません。例えば米ドルのみ利用可能ということもたまにあります。ですが、銀行振込に対応しているオンラインカジノの中には、国内送金に対応しているカジノもあるんです。 手数料が安い・無料で入出金できるオンラインカジノを厳選して13カジノ紹介!銀行振込やクレジットカード決済でもほとんど手数料がかからない、お得なオンカジです。入出金が多いプレイヤーにおすすめです。 まずはベラジョンカジノの入金で使えるVISAのデビットカードの一覧表です。
aurogra 100mg tablets
It’s going to be end of mine day, but before finish I am reading this great article to increase my experience.
best online pharmacy propecia
cipro 750 mg
Excellent weblog here! Also your web site loads up very fast!
What host are you the usage of? Can I get your associate hyperlink in your
host? I wish my web site loaded up as quickly as yours
lol
lyrica 50 mg cost
where to get metformin
suhagra 25 mg tablet
glucophage price usa
buy suhagra 100
lyrica price comparison
where can i buy levitra without prescription
medrol 16 mg cost
price ciprofloxacin 500mg
prazosin for nightmares
allopurinol 100 mg generic
buy suhagra online
buy suhagra online
Oh my goodness! Amazing article dude! Thank you, However I am experiencing issues with your RSS. I don’t know why I can’t subscribe to it. Is there anybody else getting the same RSS problems? Anybody who knows the solution will you kindly respond? Thanx!!
buy elimite
phenergan prescription australia
cheap propecia uk
brand name cipro
metformin 1000 mg cost
nursing assignment help health essay paper author main page 248 college essay writing what can a respectful response to a counterclaim help establish within your essay?
price of metformin 850 mg
suhagra 100 online
atenolol 50mg
allopurinol
zanaflex price uk
buy atenolol 25mg
cymbalta 2019
propranolol 200 mg
Thank you a bunch for sharing this with all folks you really understand what you are talking approximately! Bookmarked. Please also seek advice from my site =). We may have a link exchange contract among us
phenergan online nz
allopurinol 50
buy suhagra online
propranolol cost
buy amoxicillin canada
singulair for allergic rhinitis
buy levitra pills online
buy aurogra 100
suhagra 100mg in india
cafergot medication
metformin er 500 mg
buy ciprofloxacin tablets
where to order levitra online
aurogra 200
buy suhagra 50 mg
cafergot medicine
buy allopurinol online uk
metformin 500 mg prices
buy amoxicillin 500 mg without rx
medicine prazosin 1 mg capsule
suhagra 25 mg tablet
generic vardenafil uk
glucophage 850 online
medrol 16 mg tablet
medrol 50 mg
proscar coupon
order levitra online canada
cost of proscar in canada
how to get metformin without prescription
levitra 10 mg
30 prazosin 1mg cap
aurogra 100 prices
atenolol no prescription
prazosin 2 mg tablet
levitra online sale
phenergan 50 mg tablets
citalopram buy online australia
inderal 160 mg
allopurinol 10 mg tablet
can i purchase cymbalta in canada
Sketchup Free Download Full Version With Crack is usually a professional planning software employed by hundreds of countless numbers of sector pros throughout the environment. The software concentrates on
phenergan 12.5 mg tablets
8 mg zanaflex
medicine propranolol
cost of 1mg propecia
buy propranolol over the counter
medrol 16
atenolol tablet
inderal 10 mg online
metformin cost uk
how to buy levitra online
tizanidine online purchase
This article will help the internet viewers for building up new website or even a blog from start to end.
prazosin 1 mg cap
cheapest price for cymbalta
where can i buy allopurinol uk
lyrica 200 mg cost
lyrica 2019
ciprofloxacin 1g
inderal
ciprofloxacin 250
cipro xr 500
augmentin capsules 875 mg
buy propranolol tablets
lyrica 200 mg cost
merck propecia
suhagra 50 mg
inderal 10 tablet
augmentin 875 generic price
ivermectin 80 mg
amoxicillin over the counter australia
inderal medicine 20 mg
medrol generic pharmacy
ciprofloxacin price canada
allopurinol 135
price of phenergan
inderal 80 mg
tenormin brand name
cymbalta generic 60 mg
suhagra 100 pill
lyrica cap 75mg
please wait outside of the house friend the scent of freshly cut grass is refreshing
Hi my family member! I want to say that this article is awesome, great written and come with almost all important infos. I’d like to see more posts like this .
strattera 40 mg coupon
valtrex for sale online
buying ventolin in usa
best zoloft generic
medicine amoxicillin 500
mexican online mail order pharmacy
canadien pharmacies
phenergan price south africa
amoxicillin 500 mg buy online
tizanidine 2mg tablet price in india
phenergan gel over the counter
lasix order online uk
permethrin cost
augmentin tabs 625mg
plavix 50 mg
canadian neighbor pharmacy
can i buy zoloft online
prescription free canadian pharmacy
amoxicillin 625 price in india
strattera uk
100mg strattera
plaquenil depression
plavix 150 mg
noroxin pill
medical mall pharmacy
how much is cymbalta 60 mg
prozac 20 mg tablet price
elimite cream generic
buy kamagra tablets online
cymbalta without a prescription
canadapharmacyonline com
phenergan pill
phenergan medicine over the counter
buy ventolin on line
buy generic lasix online
zovirax herpes
strattera 60 mg tablets
where to buy acyclovir in singapore
Howdy, I believe your website could be having browser compatibility issues. When I look at your web site in Safari, it looks fine but when opening in IE, it has some overlapping issues. I simply wanted to give you a quick heads up! Apart from that, fantastic website!
60 mg prozac
buy furesimide
strattera 120 mg daily
furosemide brand name australia
hydroxychloroquine sulfate tabs
phenergan prices
cymbalta 90 mg tablets
where to buy terramycin in canada
amoxicillin 500 mg capsule
buy zoloft online australia
albuterol cheapest price
metformin hcl 1000mg
fluoxetine 20 mg tablet
cymbalta 20 mg
elimite purchase
levitra cost
cost of strattera generic
plaquenil eye
plaquenil coupon
phenergan tablets nz
plaquenil skin rash
strattera generic brand
how much is amoxil
buy hydroxychloroquine 200 mg
buy phenergan online uk
buy cymbalta online canada
cymbalta generic price usa
cymbalta prescription cost
hydroxychloroquine coupon
uk pharmacy
can you purchase phenergan over the counter
ventolin cost canada
pharmacy online track order
where to buy elimite cream over the counter
hydroxychloroquine plaquenil 200 mg tablet
medicine amoxicillin 500mg
price of acyclovir cream
generic zoloft online
prescription free canadian pharmacy
combivent respimat pi
acticin online
acticin online
amoxicillin buy
cymbalta cost generic
2500 mg amoxicillin
acyclovir cream for sale online
amoxil capsule price
order amoxicillin canada
combivent respimat pi
lasix 20g
can you buy phenergan over the counter nz
buy flomax canada
acyclovir 800mg coupon
canada cloud pharmacy
quineprox 75mg
average cost of zoloft prescription
cost of acyclovir 400 mg
combivent respimat inhaler spray
Hi there to every one, because I am in fact keen of reading this webpage’s post to be updated daily. It consists of good stuff.
onlinepharmaciescanada com
order lasix with no prescription
cymbalta 60 mg coupon
reliable canadian online pharmacy
buy lasix no prescription
hydroxychloroquine 100mg
phenergan generic brand
10 mg prozac
buy cheap acyclovir
fluoxetine 25 mg
rx online pharmacy
best pharmacy
prozac 80 mg tablet
ventolin price canada
albendazole canada pharmacy
zovirax cream price us
acticin over the counter
plaquenil for lupus
elimite price
metformin 3000 mg
buy generic flomax
flomax drug
generic medrol
ventolin buy online
flomax otc
zovirax 500
amoxicillin 45mg
fluoxetine 20 mg brand name
ventolin from india
amoxicillin capsules 500mg price in india
permethrin cost
can you buy lasix in mexico without a prescription
online pharmacy prescription
where can you buy amoxicillin over the counter in uk
buy phenergan 25mg
buy zovirax cream online no prescription
Hello! Someone in my Myspace group shared this site with us so I came to give it a look. I’m definitely enjoying the information. I’m book-marking and will be tweeting this to my followers! Fantastic blog and brilliant style and design.
buy phenergan australia
cipro 500mg best prices
plaquenil price singapore
tadacip for sale
indian pharmacy
elimite cost
purchase zoloft online
pharmacy store
tops pharmacy
can you buy furosemide over the counter in canada
canadian pharmacy online ship to usa
buy strattera online europe
augmentin order online uk
phenergan iv
discount pharmacy
flomax for women urinary retention
medical mall pharmacy
flomax purchase
reputable canadian online pharmacies
strattera no prescription
price of strattera
strattera 44 online
mexican pharmacy what to buy
combivent respimat price
zoloft generic 25mg
pharmacy website
acyclovir 400 mg price
clopidogrel 10 mg
fluoxetine 60 mg tablet
cost of strattera in australia
buy plaquenil online uk
best generic cymbalta
buy zovirax online
canadian pharmacies comparison
cymbalta discount
canada pharmacy world
suhagra 100mg online buy
canadian pharmacy 1 internet online drugstore
can you buy prozac over the counter usa
amoxil 500 mg mexico
best generic cymbalta
can you buy medrol over the counter
strattera over the counter
hydroxychloroquine sulfate oval pill
plavix generic in usa
flomax .4mg
amoxicillin order online canada
retin a buy online canada
acyclovir mexico
medrol 40mg
us pharmacy no prescription
plavix cost india
ventolin albuterol
order acyclovir 400 mg
hydroxy-chloroquine
plavix buy online uk
buy valtrex australia
elimite generic
canadian pharmacy store
hydroxychloroquine sulfate tabs
prazosin caps
cheap generic cymbalta
tizanidine 4 mg brand name
over the counter medication flomax
online fluoxetine prescription
where to buy fluoxetine online
clopidogrel coupon
otc amoxicillin uk
cheap cialis from canada
price for combivent
bitcoin pharmacy online
zovirax nz
how to order metformin online
cymbalta 30
nolvadex online australia
propranolol over the counter usa
elimite medication
ampicillin over the counter uk
avodart price
levaquin generic
buying cheap propecia Although the total number of DEGs was relatively low in our KO NEUROG2 neurons, some were validated in a different genetic background line 50B in Figure 4C and were previously associated with ASD, e
ampicillin 250 mg caps
elimite price
levaquin.com
clindamycin 300 mg capsule
gabapentin 100mg tablets
toradol for headaches
buy generic nolvadex
albendozale purchase
celebrex 400 mg price
levofloxacin
viagra 100 buy online
cleocin ointment
buy valtrex online india
propranolol prescription online
where can you buy elimite cream
clindamycin cap 150mg
buspar 30mg tabs
erythromycin 400mg
feldene 10 mg price
feldene tablet
Pretty! This was an extremely wonderful post. Thanks for providing this information.
buy avodart canada
avodart 0 5mg
cialis canada online
inderal buy online uk
buy tizanidine uk
ampicillin purchase
brand viagra online australia
elimite cream
feldene 20 mg capsules
triamterene 37.5 mg hctz 25mg caps
over the counter tizanidine
purchase levaquin
propranolol 80 mg cost
prednisone 5442
nolvadex otc
buy feldene gel
propranolol over the counter australia
price of ampicillin
clindamycin cream price in india
canada pharmacy not requiring prescription
triamterene 37.5 25 mg
valtrex without prescription
avodart without prescription
medrol 4mg price
canadian tadalafil online
cialis 5 mg daily use cost
canadian valtrex otc
I love what you guys are usually up too. Such clever work and exposure!
Keep up the superb works guys I’ve incorporated
you guys to blogroll.
Feel free to surf to my page – 2024 kalenteri
propranolol 40mg buy
erythromycin capsules 250mg
medrol buy
buspar
levaquin 750
buy viagra best price
ampicillin 250 mg tablet
zanaflex for back pain
medrol 16mg tab
best price for piroxicam
medrol tablet 8 mg
30 mg cialis
best accutane brand
piroxicam drug
albendazole online
buy yasmin without prescription
toradol for migraines
prazosin 2 mg caps
buy propranolol without prescription
where to buy elimite
zanaflex coupon
canadian cialis
online avodart without prescription
buspar 10 mg tablets
toradol for fever
buy erythromycin cream
generic viagra 100mg for sale
where can you buy valtrex
synthroid nz
erythromycin 40mg
generic elimite cream
otc toradol
cheap buspar
albendozale purchase
levaquin cost
cleocin vaginal ovules
elimite cream
propranolol 240 mg
prescription cialis uk
buspar sale
triamterene cheap
Excellent web site you have here.. It’s hard to find quality writing like yours these days. I truly appreciate people like you! Take care!!
where to buy prednisone without prescription
buspar 5mg tab
piroxicam 10 mg capsule
where to get albendazole
tamoxifen 100 mg
buy elimite cream
buy nolvadex 10mg
medrol tablet price
levaquin antibiotics
tizanidine 6 mg capsules
paypal cialis
tizanidine 4mg capsules
avodart online buy
bluechew tadalafil
albendazole cheap
where can you buy cialis online
erythromycin gel australia
price comparison tadalafil
buy tamoxifen paypal
avodart 5 mg price
prednisone cost in india
order levaquin online
It’s a shame you don’t have a donate button! I’d without a doubt donate to this excellent blog! I suppose for now i’ll settle for book-marking and adding your RSS feed to my Google account. I look forward to fresh updates and will talk about this blog with my Facebook group. Chat soon!
toradol generic cost
buspar 30 mg tablet
pfizer viagra sildenafil citrate 50mg viagra pill
generic feldene
buy buspar
tizanidine 44
clindamycin phosphate
generic triamterene
propranolol hcl
buying valtrex in mexico
where can i buy nolvadex
cleocin for sinus infection
viagra price per pill
how much is toradol
cleocin 300
where can i buy nolvadex in canada
elimite over the counter canada
buy valtrex without get a prescription online
tizanidine 4mg prices
can i purchase valtrex over the counter
tizanidine 6 mg
propranolol buy uk
cialis pills canada
levofloxacin
cheap cialis online pharmacy
albenza over the counter uk
buy nolvadex online no prescription
erectafil 40
online pharmacy in canada cialis
tadalafil 40 mg online india
inderal 40 mg cost
buspar buy online
tamoxifen generic brand name
avodart no prescription
where to get clindamycin
buy cialis generic india
triamterene 50 mg
valtrex online pharmacy
propranolol online purchase
how to order viagra in india
Everything is very open with a precise description of the issues. It was really informative. Your website is very useful. Thank you for sharing!
celebrex 200mg generic
cheap viagra 25mg
ampicillin coupon
where do you buy viagra
prednisone 20 mg online
buy tadalafil 10mg india
cheap medrol
cleocin topical for acne
best price for sildenafil
ampicillin capsule 500mg
albendazole 400 mg pills
where to buy feldene
where to buy acticin cream
prednisone 60 mg
tizanidine capsules
buy medrol online uk
ampicillin tablet 500mg
medrol 4mg tablets
toradol generic brand name
levaquin buy
tamoxifen 20 mg tablet price in india
buspar 150 mg daily
how much is valtrex prescription
toradol iv
ampicillin 500mg price
erythromycin 600 mg
albendazole tablets online
prednisone 10mg tablets
levofloxacin
What i do not realize is if truth be told how you’re now not really a lot more well-appreciated than you may be right now. You are so intelligent. You recognize therefore significantly with regards to this topic, produced me individually consider it from so many various angles. Its like men and women don’t seem to be fascinated until it’s something to accomplish with Woman gaga! Your own stuffs great. All the time deal with it up!
generic triamterene
erythromycin coupon
ampicillin iv
levaquin 250mg
triamterene 37.5mg hctz 25mg caps
clindamycin discount
tamoxifen uk online
avodart for sale
generic feldene
how to get valtrex prescription online
albendazole tablets 400 mg price
diflucan rx coupon
propecia prescription cost uk
wellbutrin xl 300 mg generic
plaquenil 200mg cost
buy tretinoin cream online india
lyrica brand name
diflucan rx coupon
retin a 0.1 cream for sale
hydroxychloroquine sulfate oval pill
hydroxychloroquine 900 mg
buy lyrica cheap online
over the counter lexapro
plaquenil 200 mg prices
lyrica coupon
biaxin cream
levitra cost mexico
augmentin buy canada
otc zyban
erectafil 10
plaquenil 200mg
hydroxychloroquine coupon
augmentin 875 pill
http://tuchkas.ru/
erectafil 2.5
colchicine daily
erectafil 10
biaxin canada
drug cost for plaquenil
finasteride hair
generic for wellbutrin
buy generic dapoxetine online
Great web site you have here.. It’s hard to find high-quality writing like yours these days. I truly appreciate people like you! Take care!!
buy erectafil 20
3131 avana
biaxin tablets
quineprox 60 mg
lyrica tablet price
erectafil 5 mg
price of retin a cream in india
budesonide capsules generic
propecia online prescription
clomid pills cost
You should take part in a contest for one of the highest quality blogs on the web. I am going to recommend this website!
buy generic lyrica
baclofen 10 mg tabs
biaxin bronchitis
best generic propecia
online dating simulator: date me site – free online dating sites with no fees
buy baclofen usa
bupropion discount
buy baclofen in uk
cost of propecia generic
desyrel generic
biaxin for uti
prednisone 0.5 mg: https://prednisone1st.store/# 1 mg prednisone cost
diflucan over counter
lyrica generic usa
ivermectin 0.5% lotion
buy lexapro online australia
propecia discount coupon
hydroxychloroquine sulfate tablet 200 mg
225 mg lyrica
lexapro 5mg tablet price
propecia cost comparison uk
augmentin 500 cost
where to get cialis in singapore
trazodone 100 mg tab
where to order albendazole
cheap propecia generic
zoloft 2017
generic stromectol
generic finasteride 1mg no prescription
finpecia online pharmacy
dapoxetine purchase in india
where can i get amoxicillin 500 mg
hydroxychloroquine 800mg
legit pharmacy websites
buy propecia online
ivermectin generic name
phenergan cost
ivermectin new zealand
phenergan tablets
cost of stromectol medication
order finasteride
lyrica for sale
how to buy amoxicillin online uk
propecia 1mg pill
erectafil 5 mg
trazodone 400 mg
medrol 4
diflucan canada prescription
cost of ivermectin medicine
hydroxychloroquine sulfate tablets
lexapro 20mg
baclofen tablets buy
erectafil 20 online
propecia prescription cost uk
covid ivermectin
cost of generic biaxin
lexapro 10 mg price australia
finasteride tablets
buy zyban tablets uk
propecia 1mg price in india
propecia generic australia
erectafil
ivermectin
buy albenza online uk
trazodone otc
buy cheap trazodone online
albendazole buy canada
us cost of dapoxetine
trazodone 300 mg tablet
wellbutrin 2018
tretinoin 0.025 canada
prescription valtrex online
finasteride online pharmacy india
tretinoin retin a cream
biaxin for pneumonia
diflucan prescription cost
amoxicillin order online
lyrica tablets 50mg
over the counter amoxicillin
buy zentiva hydroxychloroquine
buy erectafil
tadalafil 100
clomid price in india online
phenergan over the counter australia
10mg baclofen tablet
ivermectin buy nz
plaquenil tab 200mg
retin a 05
augmentin 500 generic
buy super avana
buy retin a over the counter
1.25 mg lexapro
purchase finasteride without a prescription
erectafil 5
Thank you for sharing your info. I truly appreciate your efforts and I am waiting for your next post thank you once again.
baclofen medicine in india
cafergot australia
albendazole over the counter
augmentin 1000 mg 62.5 mg
tretinoin cream from mexico
finasteride drug
erectafil 20
21 amoxicillin 500mg price
30 mg lexapro 20 mg
trazodone 300 mg tablet
It’s very trouble-free to find out any topic on net as compared to books, as I found this article at this site.
cialis order online usa
propecia cheapest india no prescription
biaxin 500 mg generic
6 mg tadalafil
tadalafil 20 mg price canada
50 mg of trazodone
avana singapore
baclofen prescription price
finasteride online bonus
02 retin a
albendazole cream
baclofen brand name in canada
baclofen 100mg
can you purchase propecia
propecia 1mg tablets price
propecia australia cost
elimite cream 5
quineprox 80
propecia 1mg online
brand cialis 20 mg
plaquenil uk price
phenergan uk pharmacy
amoxicillin 876 mg
cheap propecia singapore
dapoxetine india
avana 77064
buy lexapro online india
order trazodone
tadalafil uk cheap
trazodone drug
can i buy propecia over the counter
drug albendazole
order propecia online
erectafil 5 mg
glucophage 250 mg price
propecia canadian pharmacy
erectafil 20
dapoxetine for sale
erectafil 20 mg price
buy lyrica online europe
For newest news you have to go to see world-wide-web and on internet I found this web site as a most excellent website for latest updates.
where to buy amoxil
cialis price europe
It is perfect time to make a few plans for the longer term and it is time to be happy. I have read this submit and if I may I want to recommend you few interesting things or suggestions. Perhaps you could write next articles referring to this article. I want to read more things approximately it!
baclofen australia
buy avana 200 mg
generic propecia 1mg
buy propecia uk
wellbutrin drug
lexapro pharmacy
plaquenil 200mg cost
finasteride prescription uk
tretinoin 0.05 cream uk
prescription retin a
triamterene-hctz 75-50
how to order metformin online
atenolol order
metformin tablet
prazosin for sleep
triamterene 37.5mg hctz 25mg caps
phenergan 10mg cost
atenolol uk
metformin pharmacy coupon
canadian pharmacy coupon
buying prednisoline tablets
phenergan 25mg price
phenergan over the counter south africa
cymbalta 60 mg price in india
triamterene generic
can i buy dexamethasone over the counter
dexamethasone 1 mg
can i buy phenergan over the counter
tadalafil order online
dexamethasone 4 mg tablet india
cialis fast shipping
prazosin cost
baclofen tab 10mg
buy generic cialis online usa
phenergan generic price
50 prednisolone 15 mg
dexona medicine
prednisolone buy
dexamethasone buy online
atarax medicine price
lipitor 10 mg
levaquin buy
generic robaxin 500mg
phenergan 100mg
robaxin 750 mg price
canadian pharmacies not requiring prescription
buy metformin 500 mg without a rx
atarax generic otc
phenergan generic brand
triamterene-hctz 37.5-25 mg tb
baclofen 10 mg tablet online
online pharmacy cialis
where can i buy retin a gel online
cymbalta canadian pharmacy
buy lipitor 10 mg
dexamethasone discount
triamterene-hctz 37.5-25 mg cp
cheapest pharmacy for prescriptions without insurance
triamterene-hctz 37.5-25 mg cp
online pharmacy uk prednisolone
where to get metformin
levaquin antibiotic
buy baclofen australia
medication robaxin 500
tamoxifen for men
robaxin cost
atarax for eczema
cost of metformin 500 mg
express scripts com pharmacies
baclofen 10 mg tablet price
mail order pharmacy no prescription
buy prednisolone no prescription
cialis india
triamterene 37.5mg
tamoxifen tablets for sale
albendazole albenza
phenergan canada otc
buy levaquin online
robaxin generic
20 mg tamoxifen cost
write a good college essay accounting homework help how to write a claim statement for an essay
atenolol 787
atarax 25 mg price
metformin tablets 800mg
atarax medication
safe reliable canadian pharmacy
prednisolone cost uk
levaquin 750mg
australia price for valtrex
atarax 10mg
robaxin 750 uk
atarax eq
robaxin 250 mg
atenolol 50 prescription
retin a over the counter europe
trental 400 mg online
prazosin 8 mg 6 mg 8 mg
robaxin 1800 mg
where can i buy prednisolone uk
prazosin
cialis rx cost
buying metformin online
lipitor 0 5 mg
canadian pharmacy no rx needed
diflucan 100 mg daily
Запчасти стиральных машин китайских производителей из за низкого качества в наличии не держим, их продажей и поставкой компания не занимается, поэтому купить щетки электро двигателя за 300 рублей или сливной насос (помпу) за 450 рублей у нас нельзя!
water pill triamterene hctz
cost of prednisolone uk
Металлический хомутовый нагреватель представляет собой резистивную ленту шириной 3-4 мм, намотанную на слой миканита https://rusupakten.ru:443/product-category/electric-heaters/
И все это помещено в корпус из нержавеющей стали https://rusupakten.ru/product-category/electric-heaters/clamp-heaters/
Уточняйте наличие товара, оптовые и розничные цены на трубчатые нагреватели и стоимость доставки у компании поставщика, связавшись по контактным данным Поиск среди ,
tadalis sx soft
lipitor tablets
robaxin eq
zithromax otc usa
200 mg atenolol
online pharmacy prescription
purchase nolvadex
daily baclofen
phenergan 10mg uk
dexona 8mg tablet
best india pharmacy
baclofen tablets brand name
tretinoin gel price in india
tretinoin 0.5 cream
low cost online pharmacy
zithromax for sale cheap
phenergan 25mg
where to buy cialis over the counter uk
prazosin 2 mg capsules
how to buy tretinoin cream
script pharmacy
cheapest prescription pharmacy
levaquin buy online
your pharmacy online
atarax medication generic
medicine zithromax
robaxin tablets australia
dexona price
over the counter dexamethasone cream
atenolol 50 mg prescription
tretinoin gel over the counter
prazosin 2 mg caps
prednisone prescription
best online pharmacy india
where can i buy azithromycin online
baclofen over the counter usa
levaquin 500 mg levofloxacin antibiotics
baclofen price canada
atarax 25mg tab
how to get cymbalta
levaquin 500 mg tablets
robaxin 500 mg tablet
help write essay for me essays online exemplification essay help
pharmacy express
canada pharmacy not requiring prescription
dexamethasone 4 mg tablet buy online
triamterene
retin a 1 cream price
dexamethasone tablet
otc cialis pills
atarax 10mg price
legitimate online pharmacy usa
generic tadalafil 20mg india
atenolol pill
buy zoloft no prescription
cymbalta 30 mg
price of prednisolone
levaquin 750mg
zithromax 250mg tablets
retin a 06
cymbalta
На слух мотор работает неравномерно, с провалами, обороты нестабильны на холостых https://zapchasti-remont.ru/shop/goods/filtr_vozdushnyiy_BS_692519_dlya_dvigateley_VANGUARD_V_TWIN_RP_3527-10985
Появились посторонние шумы при работе, которых ранее не наблюдалось https://zapchasti-remont.ru/shop/goods/prokladka_golovki_tsilindra_592358-9097
no prescription required pharmacy
atenolol in europe
canadien pharmacies
cymbalta over the counter
robaxin 850 mg
triamterene-hctz 37.5
generic atenolol
where to get tretinoin cream
azithromycin over the counter south africa
lipitor generic over the counter
buy prednisolone tablets 5mg uk
dexamethasone medication
canadianpharmacymeds com
tretinoin uk prescription
metformin otc
cost of lipitor 90 tablet
price for robaxin
nolvadex tablets
atarax otc usa
online pharmacy 365 pills
phenergan 25
phenergan generic brand
generic levaquin
best online pharmacy for viagra
buy generic cymbalta 60 mg
cymbalta cost canada
reputable indian online pharmacy
dexamethasone 4 mg tablet
nolvadex for sale in south africa
dexamethasone 75 mg tablet
buy atarax tablets uk
order dexamethasone online
triamterene-hctz 37.5-25 mg
tenormin 3
metformin price south africa
discount robaxin
canadien pharmacies
online pharmacy 365
prazosin 5 mg
cymbalta 30 mg
atarax 25mg for sleep
tretinoin uk
canadian pharmacy ed medications
buying metformin canada
can you buy lipitor over the counter
atenolol 50 india
buy atarax 25mg
cost of lipitor in australia
triamterene 75 50 mg
cheapest prescription pharmacy
buy phenergan nz
canada online pharmacy no prescription
triamterene/hctz 37.5-25 mg
how to buy azithromycin online usa
dexamethasone 16 mg
baclofen 20 mg pill
levaquin tablets
how to get neurontin
cross border pharmacy canada
arimidex tamoxifen
cialis drug
american pharmacy
methocarbamol robaxin
global pharmacy
levaquin tablets
baclofen 30 mg tab
atenolol cheap
levaquin cost
tenormin 12.5 mg
triamterene-hctz
dexamethasone 1.5 tablet
phenergan 25mg for sale
tadalafil 2.5 mg
phenergan generic cost
drug levaquin
prednisolone 25mg price
purchase metformin online
triamterene price
tamoxifen prices
atenolol prescription
where can i get dexamethasone
phenergan over the counter canada
cialis professional
Представительский мужской эротический массаж Москва с сауной
dexamethasone 5 mg tablet
purchase azithromycin
tretinoin otc us
where to buy atarax
accutane buy
40 mg generic cialis
atarax 25 mg tablet
triamterene 37.5 mg tab
triamterene cream
cymbalta purchase
best value pharmacy
generic retin a from mexico
lipitor tabs
metformin 500 mg uk
cheap viagra online canadian pharmacy
cialis low price
triamterene 37.5mg hctz 25mg
prednisolone tablets 5mg price
prednisolone prednisone
triamterene 50 25 mg
online pharmacy search
baclofen 10 mg tablet brand name
robaxin without a prescription
cymbalta generic price comparison
glucophage 500mg cheap
metformin cost mexico
pharmacy mall
atenolol metoprolol
tretinoin cream purchase
canadian pharmacy mall
robaxin for back pain
pharmacy store
how much is diflucan
triamterene price
triamterene hctz 75 50 mg tab
atarax 25 mg 1mg
tamoxifen price in india
triamterene-hctz 37.5
tamoxifen cost canada
dexamethasone cream otc
atarax generic
where to buy atarax
nolvadex purchase online
compare prednisolone prices
buy generic levaquin
phenergan medication
cialis canada price
canadian online pharmacy no prescription
over the counter robaxin
dexamethasone 40 mg
metformin without a prescriptions online
tadalafil india
triamterene coupon
cheap levaquin
canadian pharmacy phenergan
where can i buy generic zithromax
dexamethasone
cymbalta online coupon
triamterene 75 mg
cost of 50mg furosemide tablets
generic phenergan
tenormin 50 mg price
lipitor 80 mg price
cost for prednisolone
robaxin generic
prednisolone over the counter australia
buy tretinoin without prescription
order metformin europe
best online foreign pharmacy
atarax 25 mg price
cymbalta 120 mg tablets
cymbalta 40 mg
buy atenolol 50 mg uk
canada pharmacy not requiring prescription
baclofen 10 mg tablet brand name
atenolol 787
cheap lioresal
tenormin medication
prices pharmacy
levaquin 500 mg tablets
atarax cost canada
lipitor no prescription
lipitor 40mg
levaquin pill
metformin 52080
tamoxifen tablet
buy atarax online
lipitor canada price
atarax price
atarax pill
robaxin generic brand
metformin cheapest price
nolvadex online south africa
azithromycin online no prescription usa
lipitor 10mg price
retin
cialis 5mg daily
prazosin sleep
rate online pharmacies
suhagra 50 mg tablet
medicine voltaren 75 mg
plavix 50 mg
tizanidine 4 mg brand name
lisinopril 20 mg 12.5 mg
lisinopril for sale online
Quality posts is the main to invite the viewers to pay a visit the web site, that’s what this site is providing.
can i buy fluconazole online
order lisinopril
purchase diflucan
northwestpharmacy
how to get propecia canada
brillx скачать
Brillx
Так что не упустите свой шанс — зайдите на официальный сайт Brillx Казино прямо сейчас, и погрузитесь в захватывающий мир азартных игр вместе с нами! Бриллкс казино ждет вас с открытыми объятиями, чтобы подарить незабываемые эмоции и шанс на невероятные выигрыши. Сделайте свою игру еще ярче и удачливее — играйте на Brillx Казино!Ощутите адреналин и азарт настоящей игры вместе с нами. Будьте готовы к захватывающим приключениям и невероятным сюрпризам. Brillx Казино приглашает вас испытать удачу и погрузиться в мир бесконечных возможностей. Не упустите шанс стать частью нашей игровой семьи и почувствовать всю прелесть игры в игровые аппараты в 2023 году!
lisinopril 2.5 mg medicine
lisinopril 20mg tablets price
order tizanidine
doxycycline 100 mg capsule
diclofenac gel cost canada
buy diflucan online
can i buy prednisone over the counter in mexico
voltaren otc in us
albuterol inhalers for sale
synthroid 0.0125 25mcg
amoxil 500 pill
celebrex cap
where can i buy bactrim over the counter
celebrex tablet 200mg
cheap accutane prescription
amoxicillin 400mg cost
plavix 20 mg
rx pharmacy no prescription
synthroid 137 mcg price
where to buy diflucan
buy zithromax online uk
buy celebrex online no prescription
phenergan promethazine
celebrex from canada without a prescription
buy generic lisinopril
lisinopril 25 mg
suhagra 50 price
suhagra 50 online purchase in india
buy lyrica canada
zestril tab 10mg
augmentin 625 mg in usa
where to buy prednisone without a prescription
strattera cap 100mg
azithromycin 500mg tablets for sale
lyrica 25 mg
cheap suhagra
hydroxychloroquine chloroquine
generic augmentin
amoxicillin 400 mg
plavix pharmacy
buy trimox online
prednisone online sale
celebrex 60 mg
azithromycin 250mg tablets cost
retino gel
cephalexin 150 mg
suhagra 25 mg tablet price
how much is generic flomax
how much is celebrex cost
doxycycline buy online india
keflex generic cephalexin
diflucan order online uk
best mail order pharmacy canada
celebrex cap 200mg
zanaflex 4mg cost
propranolol over the counter australia
price of flomax
clopidogrel 75 mg tablet price
where can i buy azithromycin online
lisinopril online
no prescription prenisone
lisinopril 12.5 mg 20 mg
no prescription pharmacy paypal
bactrim coupon
accutane cream
buy amoxicillin 500mg usa
diflucan 200 mg daily
synthroid 60 mcg
retino 0.025 gel
how to get propecia prescription online
augmentin cost in india
clopidogrel discount coupon
1 lisinopril
clopidogrel 75 mg cost
over the counter diflucan 150
amoxicillin without a script
cheap generic accutane
cephalexin for sale uk
buy diflucan 1
strattera prescription drug
azithromycin prescription cost
buy celebrex cheap
accutane india
cheap bactrim
best price for tizanidine 4mg
cephalexin 250 mg
candida diflucan
cheap deltasone
bactrim 200mg
buy online doxycycline without prescription
doxycycline 100mg capsules buy
where can i buy synthroid online
can i buy over the counter amoxicillin
cephalexin 500 mg over the counter
strattera 15 mg
diclofenac 80 mg
retino 0.05 gel
clopidogrel plavix
buy synthroid online no prescription
best canadian pharmacy
buy celebrex online australia
purchase zithromax z-pak
phenergan gel over the counter
bactrim over the counter uk
order synthroid from canada
blackweb dark net
lisinopril 2.5 mg tablet
generic celebrex online
doxycycline 75 mg tab
bactrim sale online
accutane 5 mg
lisinopril 40 mg purchase
retino 0.025 cream
buy lisinopril 40 mg online
strattera generic canada
strattera price south africa
plavix 25 mg
doxycycline 200 mg
cheapest price for lisinopril
zithromax 500mg canada
prednisone pharmacy
flomax purchase
can i buy zithromax online
amoxicillin 500mg prescription
lisinopril 10 mg buy
flomax sale
where can i buy diflucan online
cheap accutane for sale
buy phenergan 10mg
order amoxicillin 500mg
ventolin
amoxicillin 825 125 mg
where to buy plavix
diflucan price
diflucan 200 mg capsule
propranolol hydrochloride
diflucan 150 mg over the counter
suhagra 100 mg online
celebrex 400
where can you get accutane online
merck propecia
diflucan generic brand
flomax tablets in india
prednisone pak
plavix generic
merck propecia
suhagra 50mg tablet online
online pet pharmacy
celebrex tablets 100mg
canadian pharmacy world
safe online pharmacies in canada
propranolol order online
amoxicillin 250 mg pills
doxycycline 500mg price in india
cephalexin 750 mg capsule
propranolol inderal
indian trail pharmacy
proventil albuterol
azithromycin pills online
price of ventolin inhaler
accutane otc
augmentin discount
diflucan pill
buy generic celebrex online
phenergan tablets
augmentin canadian pharmacy
amoxicillin 500mg capsule price in india
canadapharmacyonline com
synthroid 0.15
synthroid cost
voltaren cream price
synthroid 150 mcg price
I am truly thankful to the owner of this site who has shared this great post at here.
retino 0.025 gel
can i buy lisinopril in mexico
diflucan tabs
retino 0.25 cream price
phenergan iv
lyrica for sale uk
zithromax over the counter uk
hydroxychloroquine coupon
synthroid pills from canada
how to buy doxycycline online
synthroid 188
clopidogrel 75 mg pill
flomax 4 mg cost
combivent mexico
where can i buy bactrim online
tizanidine 2 mg tabs
suhagra tablet
lyrica online uk
where to get accutane online
lisinopril 10 12.5 mg
doxycycline australia
plaquenil 200 mg 30 film tablet
cost of strattera in south africa
buy zithromax without prescription
save on pharmacy
diflucan medicine buy
inderal 40 cost
atomoxetine price
price for tizanidine 4mg
zestoretic 10 12.5 mg
suhagra 100mg price
can i buy keflex over the counter
lisinopril 10 mg price in india
reliable canadian online pharmacy
azithromycin 1g cost
where to buy accutane uk
strattera 60 mg tablets
Piece of writing writing is also a fun, if you be acquainted with then you can write or else it is complex to write.
plavix 300 mg
canadian pharmacy viagra 50 mg
propranolol 160 mg tablets
azithromycin 25 mg
prednisone pack
propecia cost india
buy diflucan otc
augmentin uk buy
137 mg synthroid
zithromax drug
celebrex cap
lisinopril hctz
buy phenergan 25mg
plavix 75 mg tablets
finasteride 5mg coupon
onlinecanadianpharmacy
prednisone 3 tablets daily
onlinepharmaciescanada
amoxicillin price in canada
buy diflucan online usa
brand name synthroid cheap
augmentin 625mg medicine
cost of zanaflex capsules
flomax 15
over the counter diflucan 150
suhagra 50 tablet price
buy suhagra 50 mg online india
synthroid 0.1 mcg
generic diflucan fluconazole
prednisone online
buy celebrex coupon
plaquenil cost
ventolin over the counter uk
retino 0.05 price
buy diflucan 150mg
prednisone 20mg no prescription
bactrim antibiotic
albuterol hfa
doxcyclene
amoxicillin tablets where to buy
price for augmentin
buy inderal 10mg
amoxicillin 500 125 mg
how to get zithromax
suhagra 50 mg tablet price
buying synthroid in mexico
average price of doxycycline
purchase lisinopril online
diflucan tablets buy online
flomax women
retino 0.25 cream
Wow, superb blog format! How long have you been blogging for? you make blogging glance easy. The entire glance of your web site is magnificent, let alonesmartly as the content!
canadian pharmacy generic viagra
price of accutane in australia
My partner and I absolutely love your blog and find most of your post’s to be precisely what I’m looking for. Do you offer guest writers to write content for yourself? I wouldn’t mind creating a post or elaborating on some of the subjects you write concerning here. Again, awesome web log!
amoxicillin buy no prescription
buy diflucan 150 mg
celebrex 200 capsules
zestril 20 mg price canadian pharmacy
prednisone 500 mg tablet
celebrex price canada
prednisone 20 mg without prescription
buy lisinopril 2.5 mg
proair albuterol sulfate online
propranolol purchase
prednisone steroids
bactrim tablets uk
cephalexin online canada
where to buy propranolol
how to get strattera
amoxicillin 500 mg capsule cost
how much is ventolin in canada
buy cephalexin 500mg
buy prednisone online no script
daily diclofenac
buy fluconazole online
strattera 10 mg coupon
tizanidine tab 4 mg
zanaflex 2mg tablet price
diflucan otc where to buy
cost of strattera in canada
flomax 0.4mg price
finpecia tablets online
buy cheap keflex
prednisone 475
strattera generic brand
cephalexin coupon
where to get bactrim
lyrica 500 mg
suhagra 100 mg online
synthroid cost generic
phenergan tablets online
strattera lowest price
diclofenac 35 mg
flomax 0.4
where can i get diflucan over the counter
augmentin 875 price in india
lyrica prices in canada
purchase albuterol online
cost of flomax
synthroid tab 88mcg
zanaflex caps 4mg
purchase bactrim online
prednisone purchase
azithromycin usa
accutane 50mg
diflucan prescription
buy doxycycline uk
price of cephalexin
flomax for kidney stones
tizanidine 4mg for sale
finasteride tablets 1mg price in india
albuterol hfa inhaler
cephalexin 500mg price
voltaren tablets south africa
price of lisinopril
doxycycline 100mg tablets
diflucan uk
where can i get accutane in singapore
where can i buy lyrica
how much is bactrim
accutane 30 mg cost
tizanidine buy
quineprox 30 mg
doxycycline 1mg
prednisone 9 mg
buy synthroid 175 mcg
where to buy flomax
synthroid generic brand
plaquenil hydroxychloroquine cost
azithromycin online no prescription
zanaflex 16 mg
retino 0.025
lyrica 200 mg price
voltaren gel 100 mg
lyrica drug
buy doxycycline online without prescription
buy suhagra 100mg online
can you buy albuterol
lisinopril 10 mg for sale
keflex 250mg capsule cost
prednisolone 5mg without prescription
baclofen 200 mg
albenza drug
buy vermox tablets
celebrex 200
can i buy valtrex over the counter in australia
drug tetracycline
gabapentin 100mg
propecia 1mg tablets price in india
silagra tablets
valtrex pills price
prozac tablet price
buy metformin 1000 mg online
medication cymbalta 60 mg
flomax prescription
valtrex script online
gabapentin from india
synthroid cost canada
synthroid 200 mcg tablet
provigil drug
how much is paxil pills
azithromycin cheap online
prednisolone sodium phosphate
prozac price in uk
generic for finasteride
buy augmentin online europe
cheap silagra
cheapest pharmacy to fill prescriptions with insurance
metformin 500 mg india
canadian prednisolone 5mg
buy sildalis
generic accutane prices
buy azithromycin
acyclovir online india
amoxicillin 500mg buy online
combivent nebulizer
1200 mg motrin
buy paxil from canada
sildalis tablets
phenergan nz pharmacy
albenza online pharmacy
vermox for sale online
buy gabapentin 300mg online
antabuse no prescription
celebrex over the counter canada
flomax otc
This article will help the internet people for creating new website or even a blog from start to end.
prednisolone 5mg buy online uk
vermox uk
zovirax ointment cost without insurance
buy silagra 100 mg
can you buy acyclovir over the counter
gabapentin 50 mg tablets
dexamethasone 10 mg tablet
motrin over the counter drug
buy provigil australia
buy provigil 100mg online
phenergan over the counter australia
prozac otc
albendazole pills
metformin pharmacy
cost of valtrex
I’ve read some just right stuff here. Definitely value bookmarking for revisiting. I wonder how much attempt you set to create one of these wonderful informative site.
50 cg synthroid
synthroid lowest prices
how to get valtrex
generic for augmentin
vermox for sale uk
silagra 50
motrin 600 pill
zovirax cream genital herpes
phenergan 25 mg tablets uk
silagra 100
can i buy azithromycin online usa
augmentin best price
augmentin 625 prices
gabapentin 103
You made some decent points there. I looked on the web for more information about the issue and found most individuals will go along with your views on this site.
phenergan 25g
prednisolone 1 cost
best price fluoxetine
sildalis 120 mg order canadian pharmacy
augmentin 500 mg coupon
buy silagra tablets
prednisolone 5mg for sale
vermox online uk
accutane online usa
legal online pharmacies in the us
zithromax capsules 500mg
vermox otc canada
zovirax cream canadian pharmacy
is albenza over the counter
purchase albuterol online
celebrex no prescription
gabapentin 350mg
cymbalta generic
flomax generic over the counter
how much is generic celebrex
where to get propecia
silagra without prescription
celebrex celecoxib
silagra 100mg tablets
motrin 800 mg rx coupon
augmentin tablet 625mg
silagra online india
canadian online pharmacy no prescription
Yes! Finally something about %keyword1%.
provigil prescription
silagra uk
metformin xl
albendazole brand name
over the counter antabuse
motrin tablets cost
usa online generic prozac no prescription
valtrex 1g tablets cost
disulfiram with no prescription
where can you buy antabuse
terramycin antibiotic
valtrex capsules
accutane without a prescription
buy valtrex no prescription
zovirax online uk
albendazole online canada
motrin 600 otc
valtrex without presciption
generic for zovirax
sildalis 120
Hi there, I found your web site by the use of Google whilst searching for a similar matter, your web site got here up, it appears good. I have bookmarked it in my google bookmarks.
antabuse over the counter
purchase gabapentin online
motrin 600 pill
celebrex online
how much is celebrex generic
discount pharmacy online
where to buy provigil online usa
paxil 50 mg
buy silagra 100
Ahaa, its pleasant conversation concerning this article here at this blog, I have read all that, so now me also commenting here.
provigil pharmacy
secure medical online pharmacy
legal canadian pharmacy online
silagra 100 mg tablet
where can i purchase modafinil
cymbalta prescription
amoxicillin tablets 400mg
zithromax order
baclofen 641956
canadian pharmacy prices
phenergan 5mg
After looking into a number of the blog articles on your site, I truly like your way of blogging. I added it to my bookmark site list and will be checking back soon. Take a look at my web site as well and let me know how you feel.
modafinil cost canada
motrin 80 mg
synthroid com
valtrex singapore
online pharmacy india
prednisolone 5mg tablets for sale
pharmacy rx
azithromycin 500 mg india
modafinil online pharmacy
provigil purchase
can i buy cymbalta in mexico
After looking over a few of the blog posts on your web page, I truly like your way of blogging. I saved it to my bookmark website list and will be checking back soon. Please check out my web site as well and let me know how you feel.
sildalis for sale
buy albendazole without prescription
how to get provigil prescription
propecia india online
buy albenza canada
buy sildalis 120 mg
modafinil uk
zithromax order online uk
Greetings from Ohio! I’m bored to tears at work so I decided to check out your website on my iphone during lunch break. I enjoy the info you present here and can’t wait to take a look when I get home. I’m amazed at how quick your blog loaded on my cell phone .. I’m not even using WIFI, just 3G .. Anyhow, wonderful site!
generic metformin prescription canada
motrin 80
zovirax cream canada
where to get ventolin cheap
motrin
where can i buy prednisolone in the uk
augmentin 625 in usa
dexamethasone 100 mg
finpecia 1mg
order tetracycline canada
buy propecia in canada
reddit canadian pharmacy
generic propecia 5mg
buy cymbalta
gabapentin pharmacy
synthroid 88 mg
medicine vermox
glucophage for sale
modafinil uk prescription
sildalis without prescription
dexamethasone 4 mg price
synthroid 0.075 mcg
purchase albuterol inhaler
can i buy zovirax tablets over the counter
modafinil singapore pharmacy
synthroid 50 mcg
motrin 400 mg price
phenergan 6.25 mg
singapore sildalis
dexamethasone 0.25 mg
amoxicillin uk
flomax online canada
buy azithromycin online no prescription
When I originally commented I seem to have clicked the -Notify me when new comments are added- checkbox and now every time a comment is added I get four emails with the same comment. Perhaps there is a way you can remove me from that service? Many thanks!
where can i get antabuse
albuterol prescription
phenergan 12.5 mg tablets
motrin 225
400mg modafinil
cost for celebrex
ventolin tablets australia
tetracycline price in canada
sildalis tablets
purchase generic valtrex online
flomax 0.4 mg cost
tetracycline 500mg brand name
order tetracycline online without prescription
how to order amoxicillin
valtrex over the counter
price of valtrex
modafinil prices online
buy sildalis 120 mg
buy accutane online cheap
synthroid 88 mg
albendazole prescription uk
dexamethasone brand name in usa
how to get antabuse
buy celebrex 200mg pills online
provigil price
motrin 800 pill
provigil generic south africa
buy prednisolone syrup for cats
gabapentin 215 capsule
prednisolone medication
Hey there would you mind stating which blog platform you’re working with? I’m planning to start my own blog in the near future but I’m having a difficult time making a decision between BlogEngine/Wordpress/B2evolution and Drupal. The reason I ask is because your design seems different then most blogs and I’m looking for something completely unique. P.S Apologies for getting off-topic but I had to ask!
which online pharmacy is the best
where to buy metformin 1000 mg
flomax 0.4 mg cost
terramycin for bees
generic terramycin
albuterol inhalers not prescription required
phenergan tablets uk
amoxicillin 875 tablet prices
sildalis 100mg 20mg
cost of paroxetine 20 mg
order valtrex online usa
modafinil generic canada
order albuterol from canada
where to purchase azithromycin
buy cheap amoxicillin online uk
prescription motrin pills
generic albenza cost
prednisolone 5mg price uk
cheap propecia pills
how much is generic celebrex
buy zovirax tablets
how to get neurontin
gabapentin 800 mg tablet
acyclovir 500 mg coupon
synthroid 137.5 mcg
buy ventolin online usa
accutane south africa
how to buy glucophage
vermox 500 mg tablet
phenergan gel prescription
terramycin crumbles
combivent buy
motrin 200 mg
terramycin for sale uk
where can i buy motrin 800
paroxetine 20 mg tablet price
antabuse disulfiram
cheap metaformin
pharmaceutical online ordering
metformin without a prescription
metformin cream
order ventolin online canada
vermox prescription
celebrex cost canada
modafinil australia prescription
modafinil over the counter uk
lioresal best price
WOW just what I was searching for. Came here by searching for %keyword%
pharmacy delivery
sildalis canada
disulfiram drug brand name
motrin sale
reputable online pharmacy uk
valtrex uk over the counter
paxil purchase online
celebrex cost canada
vermox tablets buy online
cymbalta otc
disulfiram price
sumycin online
sildalis 120
purchase tetracycline online
cymbalta 15 mg
valtrex 1000 mg daily
antabuse where to buy
buy propecia without prescription
provigil discount
synthroid discount
canadian pharmacy
provigil 100mg price
buy antabuse paypal
modafinil generic canada
generic accutane cost
buy baclofen canada
synthroid cheapest prices
cheap albendazole
antabuse cost
prednisolone 5mg capsules
phenergan gel cost
sildalis
sildalis 120
modafinil australia price
how to get propecia in australia
metformin hcl 500 mg without prescription
synthroid brand name cost
silagra 50 mg online
how much is modafinil
purchass of prednisolone tablets
buy modafinil tablets online
buy celebrex 200mg
order generic propecia online
modafinil 20 mg
albendazole sale
valtrex uk
sildalis 120 mg
combivent inhalation aerosol
prozac 5 mg
phenergan generic otc
amoxicillin 500mg no rx
disulfiram price uk
tetracycline tablets
amoxicillin 625
generic propecia online
cymbalta generic brand
buy valtrex nz
where can you get accutane online no rx
escrow pharmacy canada
where can i get metformin online
tetracycline 250 mg capsules
order modafinil from india
sildalis canada
cymbalta prescription online
purchase antabuse online
how much is paxil
prednisolone 20mg uk
accutane 40 mg price
where to buy bactrim
buy generic lexapro online
motilium domperidone 10mg
pharmaceutical online
valacyclovir valtrex
toradol cost
nolvadex europe
buy strattera 80 mg
motilium buy in canada online
vermox south africa
vermox plus
lasix tablets
uk pharmacy no prescription
tadalafil tablet buy online
buy nolvadex australia
furosemide 40 mg tablet
lasix medication over the counter
motilium tablets over the counter
rx coupon ventolin
amoxicillin generic over the counter
nolvadex 10mg india
motilium australia
bactrim pill
accutane online india
northern pharmacy
buy diflucan online
prednisolone 25 mg cost
buy metformin online uk
where can i buy diflucan without a prescription
bactrim 500
toradol script
metformin 3000 mg
clonidine tab 0.1 mg price in india
furosemide 40 mg price
buy augmentin
propecia cost canada
online pharmacy indonesia
glucophage canada online
lasix without a prescription
finasteride 5mg nz
where to buy metformin in canada
online pharmacy no rx
prednisolone 60 mg daily
buy valtrex generic online
indian pharmacy
order albuterol from canada
bactrim uk
diflucan us
nolvadex tablet price in india
toradol tablet price
motilium tablets uk
glucophage 850g
diflucan over the counter pill
diflucan cost
rx pharmacy coupons
furosemide 40 mg without prescription
furosemide price uk
buy strattera online cheap
diclofenac 25g
lexapro mexico
order diflucan
toradol medicine
diclofenac sod ec 75
toradol nasal spray
diflucan 150 mg tablet price in india
motilium 100 mg
azithromycin 600 mg
buy tamoxifen 20 mg
buy propecia india
propecia where to buy
metformin 500mg with out presciption
combivent brand name
how much is albuterol cost
reputable online pharmacy no prescription
buy diflucan uk
price of accutane
albuterol 8
buy generic trazodone
strattera singapore
rogaine propecia
buy clonidine uk
azithromycin drug
diclofenac generic
buying 0.1 clonidine
metformin where to get
accutane gel price
buy lexapro online usa
reputable indian pharmacies
albuterol canadian pharmacy
canadapharmacyonline
motilium uk buy
valtrex prescription uk
diflucan over the counter canada
propecia 1 mg for sale
motilium 10mg tablet
pharmacy store
albuterol 0.083
motilium
albuterol 1.25 mg
no prescription needed pharmacy
price of strattera
clonidine hcl 0.2 mg
where to buy voltaren tablets
toradol for sale
no rx needed pharmacy
can i buy diflucan in mexico
prednisolone 5mg without prescription
furosemide 40 mg prescription
toradol pill cost
diclofenac 150
nolvadex online order
buy zithromax no script
buy diflucan online india
motilium 20 mg
lasix over the counter 20mg
order lasix online cheap
toradol cost
toradol pain shot
strattera 60 mg buy online
accutane us
accutane canada 40mg
lasix 160 mg
metformin 500 mg tablet online
canadapharmacyonline
how to buy tamoxifen
trazodone price canada
how to buy bactrim online
order lasix without a prescription
cialis from us pharmacy
lexapro 200 mg
indianpharmacy com
vermox south africa
prednisolone 5mg tablets
trazodone 150 mg cost
metformin medicine in india
order motilium online
bactrim 400 800 mg
diflucan buy in usa
how to get albuterol
toradol medication
propecia .5 mg
lexapro online prescription
where to buy diflucan in canada
can you buy diflucan in mexico
diflucan generic
toradol migraine
buy augmentin 875 mg online
can i buy metformin without prescription
diflucan cost uk
furosemide uk brand name
can you buy furosemide otc pharmacy
toradol kidney stones
where to buy toradol
toradol 100mg
metformin 250 mg tablet
toradol 70 mg tablet
prednisolone cost tablets
how much is tadalafil cost
accutane 220mg
prednisolone 25mg tablets cost
how to buy diflucan over the counter
trazodone 50 mg tablet brand name
bactrim generic brand
tamoxifen canada brand name
metformin 1000 mg pill
motilium cost
It’s very easy to find out any topic on net as compared to books, as I found this article at this web site.
order tamoxifen online
diflucan over the counter usa
motilium online pharmacy
where to buy bactrim online
prednisolone cost australia
toradol 10mg cost
accutane online no prescription
where can i buy nolvadex in australia
buy furosemide online australia
lexapro 10mg tablet
diflucan 150 mg tabs
where can i buy vermox online
Good day very nice web site!! Guy .. Beautiful .. Amazing .. I will bookmark your web site and take the feeds also? I am satisfied to find so many useful information here in the post, we need develop more strategies in this regard, thank you for sharing. . . . . .
furosemide 12.5 mg
strattera 36mg cost
tamoxifen no prescription
zythromax
where can i buy vermox over the counter
diflucan 100 mg price
accutane tablets buy online
buy motilium uk
tamoxifen gynecomastia
lexapro capsules
azithromycin buy without prescription
amoxicillin pharmacy
100 mg lasix no prescription
buy strattera online uk
motilium canada over the counter
toradol 30mg
glucophage 750 mg
rxpharmacycoupons
toradol over the counter
toradol cream
viagra online canadian pharmacy
diflucan 200 mg capsules
oder trazadone for sleeping
cheap prednisolne
valtrex tablets 500mg price
lexapro 20 mg price australia
diflucan 150 mg uk
vermox from mexico
how can i get accutane online
cialis in mexico online
accutane in uk
canadian pharmacy bactrim
order bactrim on line
canada rx pharmacy world
toradol 100mg
furosemide 40 mg canada
prednisolone 4 mg tablets
expired albuterol
diflucan pill over the counter
motilium buy in canada online
lasix 40mg
buy albuterol pills
propecia tablets cheap
azithromycin generic over the counter
tamoxifen without prescription
furosemide without prescription us
generic tamoxifen 20 mg
albuterol sulfate inhaler
furosemide 50 mg
diflucan without prescription
bactrim tablet price
purchase motilium online
which online pharmacy is the best
furosemide cost australia
toradol 10mg pills
diflucan cost canada
order vermox
metformin costs canada
motilium pills
finasteride
cheap bactrim
lexapro generic 2019
top 10 online pharmacy in india
online pharmacy pain relief
diflucan over the counter
amoxicillin 300 mg
zithromax coupon
furosemide 160
metformin 1000 mg price in india
furosemide pill
motilium 10mg tablet
best online foreign pharmacies
vermox uk buy online
metformin otc
diflucan prescription online
generic valtrex canada
how much is metformin 1000 mg
cipralex generic best price
valtrex australia buy
propecia brand name cost
vermox united states
toradol canada
diflucan online cheap
diflucan otc in canada
top 10 pharmacies in india
motilium 10mg tablets
buy septra ds 800/160 mg online without prescription
where to get vermox
metformin brand name usa
valtrex 500mg price in india
who sells difluican with out a prescription
motilium pills
propecia mexico
best generic trazodone
lasix tabs
accutane drug
toradol prescription
trazodone for sale
trazodone india online pharmacy
canadian pharmacy world coupon
voltaren online
accutane 20 mg buy online
glucophage best price
order fluconazol
cheap accutane uk
motilium without prescription
diclofenac tablets in usa
order azithromycin 500mg
diclofenac 50mg australia
buy toradol online canada
laxis pills
canadian pharmacies comparison
lasix 80 mg price
clonidine hcl 1 mg
diflucan 200 mg daily
amoxicillin 300 mg
lasix 80
motilium generic
how to get propecia online
buy cheap zithromax
diflucan 50 mg tablet
amoxicillin online without prescription
diflucan over the counter uk
diflucan 150 otc
buy motilium without prescription
canadian pharmacy 1 internet online drugstore
600 mg trazodone
furosemide without a prescription
toradol drug
average cost of generic zithromax
prednisolone 10 mg
propecia 5mg for sale
buy nolvadex 10mg
buy diflucan
prednisolone price uk
backtim antibioticsonline.com
vermox medication in south africa
bactrim ds medication
amoxicillin 600 mg price
best generic cialis prices
metformin 100 mg
brand cialis 20mg
tamoxifen 20 mg india
generic propecia best price
prednisolone 5mg uk
rate online pharmacies
12.5 mg trazodone
northwest pharmacy canada
medicine motilium 10mg
cialis 100mg pills
how to get a propecia prescription
how to order amoxicillin without a prescription
order vermox online
diflucan over the counter
cheap generic valtrex
motilium uk pharmacy
prednisolone for sale uk
generic propecia for sale
where to buy furosemide
desyrel for sleep
vermox
diflucan capsule
diflucan pharmacy
lexapro mexico
combivent buy
trazodone drug
metformin medication
furosemide price
toradol 30
buy lasix online cheap
generic metformin price
diflucan order online uk
lasix 3170
toradol allergy
toradol over the counter uk
diclofenac cream over the counter
toradol rx
toradol online
cheap accutane uk
how to get toradol
buy trazodone 50 mg
antibiotic zithromax
voltaren 500 mg tablet
diflucan without prescription
toradol medicine
where to get lexapro mexico
canadian valtrex no rx
bactrim 400
toradol 10mg tablets
buy motilium 10mg
cost of metformin in canada
diclofenac cream brand name
clonidine 0.05 mg
diflucan tablets price
glucophage pills
clonidine hcl for sleeping
where to buy accutane uk
diflucan generic price
price comparison tadalafil
bactrim 800 mg
vermox 500mg price
lasix uk
order canadian bactrim
buy generic valtrex online canada
motilium 10mg tablet
vermox over the counter usa
ventolin price uk
price of metformin without insurance
otc toradol
vermox purchase
can you order diflucan online
otc toradol
prescription free canadian pharmacy
furosemide pills
amoxil 100mg
buy metformin usa
voltaren prescription
prednisolone 5mg prices
zithromax buy cheap
prescription drug desyrel
costs of lexapro
how to get metformin uk
buy lasixonline
lasix 500 mg tablet
buy propecia india
www canadianonlinepharmacy
cephalexin 500mg price in canada
can you buy cialis otc in canada
ivermectin 3mg tablets
zoloft for sale without prescription
cialis from singapore
lipitor generic price
prednisolone 25 mg cost australia
clonidine price
500g amoxicillin
stromectol over the counter
where can i buy gabapentin
clonidine 1 mg
zoloft medication for sale on line
canadian pharmacy coupon code
ivermectin 0.08
buy cheap antabuse
how to get ivermectin
I can’t find any good deals for Lasix online.
economy pharmacy
buy albenza online
how to get propecia
buy stromectol canada
ventolin albuterol
drug finasteride
generic ivermectin cream
where can i get doxycycline
buy prednisolone 5mg uk
generic clomid 50mg
prednisolone tablets 5mg price
You can definitely see your expertise in the article you write. The world hopes for more passionate writers like you who aren’t afraid to mention how they believe. All the time go after your heart.
https://freeprosoftz.com/coreldraw-graphics-suite-crack-2023-key/
best price for sildenafil 20 mg
Hi, all is going fine here and ofcourse every one is sharing data, that’s really fine, keep up writing.
neurontin medication
finasteride 1mg coupon
cheap wellbutrin online
furosemide 40 mg
order cialis daily
viagra paypal
ivermectin medicine
propecia for sale south africa
prednisolone
can you buy zoloft over the counter
gabapentin 150
synthroid 12.5 mcg order online
generic prednisolone otc
propecia australia prescription
keflex 750
stromectol prices
sildenafil 50mg best price
triamterene weight loss
ivermectin 12
where can i get viagra in australia
erythromycin pill
buy generic zyban online
ivermectin lotion
ivermectin 3 mg dose
40 mg lasix
200 mg doxycycline
female cialis 20mg
can i buy propecia over the counter
generic pharmacy online
stromectol online
cephalexin 150 mg tablets
propecia lowest price
order clomid online
propecia us
diuretic furosemide
tadalafil 10
stromectol uk
buy clomid india
cialis.com
Where can I buy allopurinol? Don’t wanna be walking around aimlessly
cephalexin cost australia
buy modafinil australia
amoxicillin 500 mg order online
brillx casino официальный сайт
https://brillx-kazino.com
Играя на Brillx Казино, вы можете быть уверены в честности и безопасности своих данных. Мы используем передовые технологии для защиты информации наших игроков, так что вы можете сосредоточиться исключительно на игре и наслаждаться процессом без каких-либо сомнений или опасений.Так что не упустите свой шанс — зайдите на официальный сайт Brillx Казино прямо сейчас, и погрузитесь в захватывающий мир азартных игр вместе с нами! Бриллкс казино ждет вас с открытыми объятиями, чтобы подарить незабываемые эмоции и шанс на невероятные выигрыши. Сделайте свою игру еще ярче и удачливее — играйте на Brillx Казино!
propecia price in australia
online prescription zoloft 25mg
cheap scripts pharmacy
propecia price in usa
ivermectin 90 mg
ivermectin 4 mg
where to get ivermectin
propecia 0.5 mg
Order doxycycline Canada from a licensed pharmacy.
valtrex costs canada
https://tv-master63.ru
prednisolone online pharmacy uk
Lasix loop diuretic is a lifesaver for anyone with edema.
buy cheap generic propecia
metformin for sale no prescription
prinivil 25mg
ivermectin 3mg tablets price
can i buy albuterol online
ivermectin price uk
propecia 1mg pill
stromectol 12mg online
online valtrex prescription
prednisolone tablets uk
buy gabapentin india
stromectol online pharmacy
ampicillin online pharmacy
zoloft 100mg tablet price
prednisolone 25mg tablets
stromectol order online
zyban tablets online
amoxicillin 500mg tablets price
fildena 50 mg online
tadalafil tablets in india
10 mg tamoxifen
ivermectin cream uk
prednisolone uk
120mg prednisolone
clomid iui
can you buy valtrex over the counter in australia
buy gabapentin online uk
You may need to increase your fluid intake while taking Allopurinol pill.
generic sildenafil without a prescription
wholesale viagra
mexico pharmacy valtrex
viagra order online canada
prednisolone over the counter uk
finasteride 5 mg
furosemide 20 mg generic
Keep your antibiotic needs covered with our doxycycline for sale.
where to buy ivermectin
25mg prednisolone
I’ve experienced minimal side effects since starting 1000 mg of metformin.
buy lasix 100mg
clomid 50mg tablet online
australia viagra prescription
buying valtrex in mexico
glucophage 500 online
clomid online usa
roman cialis where to buy cialis cialis for daily use cost
ivermectin 1
best price zyban coupon no rx
american online pharmacy
propecia cost generic
diflucan online no prescription
buy propecia online uk
zithromax no prescription
cephalexin antibiotic
furosemide 500 mg
how to buy lisinopril online
ventolin cost
furosemide 20 mg daily
generic zestril
canadian neighbor pharmacy
how to get propecia without prescription
lasix loop diuretic
prednisone prednisolone
ivermectin topical
drug prices sildenafil
lisinopril price
gabapentin medicine
chloroquine phosphate aralen
ivermectin pills
Please let me know if you’re looking for a author for your weblog. You have some really great posts and I believe I would be a good asset. If you ever want to take some of the load off, I’d really like to write some material for your blog in exchange for a link back to mine. Please send me an e-mail if interested. Kudos!
how can i get viagra in australia
gabapentin online usa
how to get propecia prescription
female viagra generic
prednisolone 5mg tablet coupon
generic propecia mexico
super avana
can you buy stromectol over the counter
buy ivermectin
albuterol brand name
online pharmacy in canada cialis
metformin tablet buy online
reputable indian online pharmacy
legitimate canadian mail order pharmacy
brand gabapentin
neurontin india
canadian discount pharmacy
wholesale pharmacy
mail order pharmacy no prescription
northern pharmacy canada
stromectol coronavirus
buy propecia uk
indianpharmacy com
where can i buy zithromax capsules
gabapentin india
furosemide purchase
price of ivermectin liquid
cheap propecia pills
stromectol ireland
cialis comparison
cost of tamoxifen tablets
ivermectin lice oral
clomid otc
stromectol pill
furosemide 5mg
can you buy amoxicillin over the counter canada
Yo, can you hook me up with some zyloprim allopurinol?
how to get real cialis online
ivermectin cost canada
pharmacy online australia free shipping
clomid 100mg online
canadianpharmacymeds com
pharmaceuticals online australia
propecia australia prescription
tadalafil cheapest price
ivermectin lotion for scabies
quineprox 80 mg
combivent for sale
buy paxil uk
zoloft 100 mg tablet
buy clonidine usa
propecia finasteride
lisinopril 10 mg for sale
generic viagra mastercard
rx pharmacy generic viagra
zofran generic over the counter
buy generic propecia online
zoloft 200 mg daily
buy lasix water pill
where to get valtrex prescription
buy doxycycline online australia
antibiotics levaquin
50 mg lisinopril
online prednisolone
stromectol xr
lisinopril 40 mg without prescription
propecia cost australia
propecia 1mg canada
propecia buy online canada
dapoxetine 60
augmentin penicillin
buy chloroquine online
ivermectin 0.08 oral solution
discount viagra usa
top online pharmacy
buy antabuse canada
stromectol medicine
buy zyban canada
antabuse 250 mg price
2.5 mg propecia
Does anyone know where to find a lower price of Synthroid?
wellbutrin rx online
zestril 5mg price in india
plaquenil tablets 200mg
tamoxifen cheap
zoloft 200 mg daily
buy generic propecia online uk
can you buy modafinil
generic prinivil
amoxicillin no rx
Lisinopril pill 5 mg may cause a decrease in white blood cell count in some patients.
ivermectin price canada
cost of stromectol medication
ivermectin usa price
gabapentin 900 mg tablet
canada neurontin 100mg discount
azithromycin 500 mg
lasix coupon
generic propecia cost
how to get amoxicillin uk
can you buy ventolin over the counter uk
how much is erythromycin tablets
bupropion 75
ivermectin covid
ivermectin buy online
clomid online us
25 mg lisinopril
buy prinivil
Metformin over the counter availability means increased access to affordable medication.
doxycycline hyclate 100mg
cost of levaquin
cialis dosage cialis vs viagra cialis blood pressure
ivermectin lice
zofran cost generic
ivermectin uk
prednisone over the counter south africa
ivermectin uk
lisinopril with out prescription
average cost of cialis
what’s the best online pharmacy
purchase oral ivermectin
where to buy propecia in us
cost of metformin uk
I regret trusting that the doxycycline generic would work as well as the brand name.
bupropion hcl 150mg
amoxil 250 price
generic viagra from mexico
valtrex 500 mg
The allopurinol 20 mg I received caused me to experience severe side effects.
amoxicillin 500mg capsule
Canadian pharmacy Lasix is the only medication I trust for my heart condition.
gabapentin 900 mg tablet
drug furosemide 40mg
cephalexin cap
where to buy cephalexin online
ventolin tablets uk
augmentin cheap
plaquenil 50 mg
doxycycline 100mg tablets no prescription
amoxicillin nz
hydroxychloroquine uk
ivermectin 8000
lisinopril 12.5 mg 10 mg
prednisolone 10 mg cost
albuterol from mexico
modafinil india online buy
zoloft drug
prednisolone 20mg
tamoxifen no prescription
ivermectin 3
price of metformin 500mg tablets
generic propecia prescription
amoxicillin nz
canadian pharmacy no rx needed
cialis everyday
doxycycline 200 mg daily
over the counter wellbutrin
levaquin without prescription
Should I continue taking 200 mg doxycycline even if my symptoms have improved?
zoloft us
glucophage
order zoloft online without prescription
bupropion sr 150 mg
cheap viagra pills from india
glucophage price
stromectol for humans
doxycycline generic cost
brand name propecia
buy doxycycline online 270 tabs
cost of generic propecia 1mg
cialis price in australia
stromectol covid
wellbutrin 50 mg price
can i buy propecia without prescription
zoloft lowest price
finasteride online usa
offshore pharmacy no prescription
valtrex 1500 mg
augmentin 625 mg price
order stromectol
stromectol pill
buy propecia online
propecia prescription cost
price of prednisone
viagra online without prescription usa
finasteride prostate
Where’s the best place to buy doxycycline pills online? Need them ASAP.
ivermectin generic
keflex 1g
35 mg zoloft
furosemide in mexico
I’m gone to tell my little brother, that he should also visit this webpage on regular basis to get updated from newest reports.
clomid online sale
amoxil price in india
lisinopril 30
online lasix
I had to rely on word-of-mouth recommendations to find out where to buy Lasix.
2400 mg gabapentin
ventolin tablets buy
I’m extremely inspired with your writing skills and also with
the structure on your blog. Is this a paid subject matter or did you
modify it yourself? Anyway keep up the nice quality writing, it’s uncommon to peer a nice weblog like this one nowadays..
propecia without prescription
atarax 10mg tablet
legitimate canadian mail order pharmacy
generic cialis nz
plaquenil 200 mg oral tablet
cephalexin tablets
prednisolone 5mg tablets for sale
augmentin 125
gabapentin 300 mg for sale
cost of tadalafil in canada
trust pharmacy
how to get provigil prescription
furosemide tab 80mg
purchase wellbutrin
furosemide tablets
doxycycline order
generic for combivent
where can i buy cialis online usa
25 zoloft
amoxicillin 250 mg capsule
discount generic propecia
ivermectin otc
propecia how to get prescription
propecia cost singapore
ivermectin 2%
generic wellbutrin 300mg
propecia gel
can i buy prednisolone over the counter in uk
buy stromectol canada
bupropion online cheap
augmentin 1000
buy brand name synthroid online
can you buy prednisolone over the counter in australia
canadian pharmacy amoxicillin
1500 mg metformin
cheapest pharmacy prescription drugs
buy propecia online south africa
Greetings! This is my 1st comment here so I just wanted to give a quick shout out and tell you I truly enjoy reading through your blog posts. Can you suggest any other blogs/websites/forums that go over the same subjects? Thanks!
order zoloft uk
ivermectin
legitimate canadian mail order pharmacy
buy finasteride propecia
order gabapentin online uk
how to get zyban
You made some decent points there. I looked on the internet for more information about the issue and found most individuals will go along with your views on this site.
propecia generic over the counter
where can i buy albuterol
metformin hydrochloride
ivermectin where to buy
stromectol medicine
40 mg cialis generic
prednisolone 5mg tablets
Young lady, where can I get doxycycline in this town?
stromectol pill
stromectol medicine
furosemide 500 mg online
prednisolone over the counter australia
How much is metformin 500 mg? Too much, that’s for sure.
propecia buy online cheap
zithromax otc
azithromycin prices
clomid drug
ivermectin price
online viagra womens viagra buy sildenafil online
I’ve read some just right stuff here. Definitely value bookmarking for revisiting. I wonder how much attempt you set to create this type of fantastic informative site.
finasteride for hair loss
sterapred
albenza cvs
propecia online canada
clomid cost canada
online pharmacy quick delivery
ivermectin 2
best generic wellbutrin 2018
ivermectin 1%
price generic zoloft
ivermectin covid
medicine azithromycin 250 mg
prednisolone 5mg tablets
ivermectin 3mg tablet
This is a topic that’s close to my heart… Many thanks! Where are your contact details though?
augmentin uk prescription
generic propecia prescription
buy zyban online without prescription
prozac india
compare pharmacy prices
where to buy genuine propecia
stromectol 3 mg tablets price
dexamethasone india
vermox tablets where to buy
stromectol uk
safe canadian pharmacies
furosemide 40 mg tablet uk
doxycycline 100mg tablet price
furosemide 3169
ivermectin 0.5% lotion
prednisolone tablets 25mg
propecia
bupropion 250 mg generic
vermox canada otc
amoxicillin tablets for sale
augmentin xr 1000 mg
If you’re like me and hate dealing with prescription refills, lisinopril 20 mg no prescription is the perfect solution.
valtrex 1000 mg daily
prozac 60 mg daily
vermox 500mg tablet
stromectol oral
prednisolone tablets 25mg price
amoxicillin online no prescription
diflucan 100
flomax 10
stromectol tablets buy online
wellbutrin 350 mg
dexamethasone
I have not had any negative interactions while taking the Lisinopril 5 mg tablet with my other medications.
vermox 500mg uk
trimox 250 mg
Lasix to buy is part of our commitment to your health.
zoloft online pharmacy
medicine prednisolone 5mg
buy ivermectin stromectol
prednisolone 5mg capsules
furosemide price comparison
order lasix 40 mg
canadian pharmacy world
lasix water pills for sale
If you’re looking to lower your high blood pressure, lisinopril brand could be an effective solution.
prednisolone for sale online uk
where can i purchase zithromax
Avoid the hassle and order Lisinopril 20mg directly from our pharmacy.
wellbutrin canada
buy vermox in usa
buy fluconazole no rx
Where can I buy allopurinol? I ain’t tryna waste time
flomax for sale
flomax over the counter uk
diflucan fluconazole
generic furosemide 40 mg
ivermectin generic
where can i buy valtrex
ivermectin lotion for lice
doxycycline for dogs
where can i get gabapentin
stromectol 3 mg tablet
ivermectin 3 mg
prednisolone pack
Be sure to buy online Lasix from a reputable source.
stromectol tab 3mg
zithromax for sale cheap
vermox tab 100 mg
amoxicillin online usa
propecia prescription australia
augmentin 457
viagra online from canada generic
clomid 5 mg
I can’t afford the doxycycline 50 mg cost despite having a prescription.
You can’t trust the quality of cheap metaformin. Stick with a trusted pharmacy.
where can you buy propecia
valtrex discount
zoloft online india
Lasix IV is the best medicine to treat fluid retention in the body.
propecia price in australia
stromectol liquid
Fantastic beat ! I wish to apprentice while you amend your web site, how can i subscribe for a blog site? The account aided me a acceptable deal. I had been tiny bit acquainted of this your broadcast provided bright clear concept
purchase propecia canada
cheapest pharmacy to fill prescriptions with insurance
tamoxifen brand name in india
cheap clomid
lasix on line
dexamethasone otc
Hey man, can you send me a link to that doxycycline online USA site?
prednisolone 5 mg
cost of wellbutrin 150 mg
zoloft without script
buy dexamethasone
dexamethasone 2 mg price
generic propecia canada
tamoxifen canada brand name
azithromycin no prescription
azithromycin in usa
stromectol 3 mg tablets price
brand name viagra canada
finpecia tablet price in india
furosemide medication
buy budesonide
cost of ivermectin cream
vermox 500mg
I always make sure to buy lisinopril 5mg when I do my weekly grocery shopping.
generic azithromycin tablets
augmentin 125 mg tab
vermox india
predisolone online
where to buy bupropion
zythromax
buy cheap doxycycline
buy valtrex no prescription
generic propecia online
amoxicillin 400 mg
order lasix online uk
buy prednisolone
flomax erectile dysfunction
prozac canada cost
methyl prednisolone
buy ivermectin online
prednisolone without prescription
neurontin cream
where to get zithromax
gabapentin 101
zovirax cream 5g price
gabapentin 1200
dexamethasone drug
where to buy clomid australia
flomax for bph
bupropion 100mg tablets cost
cheapest propecia for sale
generic lasix 20 mg
keflex online uk
prednisolone 10 mg daily
valtrex discount price
price of azithromycin 250 mg
propecia how to get prescription
order prednisolone online
Your article gave me a lot of inspiration, I hope you can explain your point of view in more detail, because I have some doubts, thank you.
buy zyban online no rx
lasix pills
ivermectin tablet 1mg
ivermectin cost canada
ivermectin 1 topical cream
stromectol for sale
budesonide 250 mcg
acyclovir price cream
doxycycline capsules for sale
pharmacy discount card
rx pharmacy no prescription
stromectol 15 mg
sildenafil pills
propecia without prescription
furosemide 20 mg tablet brand name
prednisolone cost uk
ivermectin lotion 0.5
Don’t let the cost of medication get in the way of your health- buy cheap Synthroid online.
cheapest price for amoxicillin
clomid over the counter south africa
cost of generic lasix
Allopurinol 100 mg tablet helps to decrease the production of uric acid in your body.
fluoxetine 435
valtrex cheapest price
propecia brand cost
canadian pharmacy viagra 50 mg
where to get ivermectin
clonidine medicine
augmentin for sale canada
I regret taking allopurinol 50 mg daily because it has not helped with my gout symptoms.
cheap finasteride australia
vermox usa buy
order cephalexin 500mg
valtrex 1000 mg price in india
where to buy zithromax online
ivermectin rx
zithromax tablets online
ivermectin 1 cream
valtrex pills where to buy
finesterude no prescription
buy wellbutrin online australia
I don’t have insurance; can I still buy Metformin 500mg?
prednisolone 25mg price
valtrex drug
keflex over the counter
buy flomax generic
ivermectin 0.08 oral solution
doxycycline hydrochloride
buy prednisolone 5mg tablets uk
lasix 500 buy
doxycycline no prescription best prices
cost of ivermectin 3mg tablets
prednisolone 25mg buy online
finasteride canada pharmacy
propecia in canada
canadianpharmacymeds com
My doctor was very knowledgeable about the benefits of doxycycline 100 mg capsule and I trust their expertise.
An impressive share! I have just forwarded this onto a coworker who had been doing a little research on this. And he in fact bought me lunch because I found it for him… lol. So let me reword this…. Thank YOU for the meal!! But yeah, thanx for spending the time to discuss this matter here on your website.
I don’t know what I would do without Lasix tablets.
buy doxycycline for dogs
lasix 80
cephalexin 500 mg over the counter
keflex 500mg price in india
all med pharmacy
buy furesimide online
prednisolone 60 mg daily
prednisolone tablets price
Быстромонтируемые здания – это новейшие сооружения, которые различаются повышенной быстротой установки и гибкостью. Они представляют собой сооружения, заключающиеся из предварительно произведенных составляющих или модулей, которые способны быть быстрыми темпами установлены в территории развития.
Калькулятор быстровозводимых зданий владеют податливостью также адаптируемостью, что позволяет просто изменять а также переделывать их в соответствии с потребностями клиента. Это экономически успешное и экологически стабильное решение, которое в крайние годы приобрело широкое распространение.
budesonide 400 mg
gabapentin 300mg coupon
foreign pharmacy no prescription
lasix uk buy
zoloft 200 mg daily
furosemide pill
bupropion sr 100mg
buy viagra without prescription
buy ivermectin pills
prednisolone 25mg australia
best generic zoloft brand
buy generic zoloft
brand name prednisolone
So happy I found a bulk purchase option for 500 Metformin
can i buy flomax over the counter
furosemide 80 mg
prednisolone 5mg
lasix medicine
furosemide 400 mg tablets
.5mg propecia daily
keflex 500 mg over the counter
canadian pharmacies compare
flomax rx
I’ve been searching for the best place to buy cheap metformin online.
cheapest finasteride generic
can you buy stromectol over the counter
keflex cream
how to buy modafinil in india
canadian flomax
sildalis cheap
synthroid online uk
generic advair 2014
atarax for dogs
albuterol purchase
synthroid levothyroxine
avodart 0.4 mg
doxycycline order
where can i buy modafinil
tetracycline antibiotic
Good post however , I was wondering if you could write a litte more on this topic? I’d be very grateful if you could elaborate a little bit more. Bless you!
buy sildalis
zestril 10
flomax 8828
myambutol
lisinopril canada
noroxin 400 mg tablets
how to get misoprostol prescription
generic acyclovir online
lowest price augmentin
modafinil where to get
biaxin brand name
sildenafil india pharmacy
Sweet blog! I found it while browsing on Yahoo News. Do you have any tips on how to get listed in Yahoo News? I’ve been trying for a while but I never seem to get there! Appreciate it
ventolin 4mg
proscar online uk
cefadroxil 500 mg cost
retino 0.25 cream price
where can i buy zithromax over the counter
kamagra jelly severe ed
kamagra 100mg oral jelly ebay
cost of valtrex in australia
lasix online australia
generic malegra dxt
noroxin
viagra soft 100mg online canadian pharmacy
cephalexin 500 generic
online canadian pharmacy coupon
avodart 0.5 mg soft capsules
seroquel buy uk
advair 500 50 mcg
propecia 0.5 daily
can i order furosemide
canadian pharmacies that deliver to the us
vantin generic
viagra soft flavoured
silagra 100 mg india
synthroid 275 mcg
suprax 400 mg cost
silvitra
generic cialis in canada
flomax bph
buy accutane 10mg
suprax 500 mg
silvitra 120mg
finpecia
viagra soft tabs 100mg 50mg
biaxin for strep
diflucan 200 mg tablet
lipitor generic price
biaxin 500 mg
buy online clomid
aurogra 100 for sale
nitrofurantoin capsules
malegra 200 mg
lipitor 40 mg pill
baclofen 10mg
buy metformin 500
malegra 150
propecia tablet price in india
can you buy provigil online
where can i buy ciprofloxacin
sildenafil 100g
fildena online
online pharmacy no prescription
can you purchase propecia
where can i buy amoxil
generic silvitra
sildenafil online uk
cheapest soft viagra soft on line
baclofen online canada
online pharmacy quick delivery
order amoxicillin without prescription
avodart price uk
azithromycin 500mg purchase
buy nolvadex uk
aurogra 100mg tablets
0 atarax
discount sildalis
order chloramphenicol
how to get prednisone without a prescription
biaxin
buy clindamycin online cheap
safe online pharmacy
zithromax 500 mg for sale
lasix online no prescription
doxycycline mexico
floxin 500g
where to buy tadalafil online
best pharmacy prices for viagra
generic cialis online cialis can i take 40mg of cialis
viagra for women pink pill
valacyclovir
Hello there, You have done an excellent job. I will definitely digg it and personally recommend to my friends. I am sure they will be benefited from this site.
noroxin 400 mg canada price
diflucan 75 mg
azithromycin cream
zovirax ointment
price of lisinopril 5mg
purchase advair online
buy generic seroquel
how to buy misoprostol in india
buy suprax tablets
sumycin over the counter
synthroid 25 mg tablet
happy family pharmacy
generic viagra cost in canada
zovirax pill
aurogra 100 prices
metformin 1000 mg price
prednisone 4
zyvox cost per pill
clomid 2017
azithromycin 500 price
pharmacy mall
canada azithromycin no prescription
modafinil online paypal
malegra 50 mg
cleocin antibiotics
cheap viagra online canadian pharmacy
advair uk
avodart 90 capsules
can i buy prednisone online
rx 535 lisinopril 40 mg
silagra 100mg from india
female viagra tablets price
buy lisinopril 20 mg online uk
roxithromycin 300 mg
suprax 200 mg price
minocin for rheumatoid arthritis
azithromycin 250 mg
noroxin 300
canadian online pharmacy no prescription
buying cialis online
buy suprax tablets
tadalafil pills buy online
49 mg accutane
cefixime tablet 200mg
lyrica 150 mg cost
avodart prescription
austria pharmacy online
lipitor generic brand
cost of minocin
buy cheap valtrex
buy suhagra 50 online
accutane tablets pharmacy
medication canadian pharmacy
400 mg acyclovir tablets
buy vermox over the counter
synthroid mexico pharmacy
synthroid 50 mcg tablet
how to get propecia without prescription
clindamycin 1 gel 30 mg
buy finpecia
floxin
cephalexin medicine prices
avodart 0 5 mg
canadian mail order pharmacy
generic prinivil
how to get cytotec over the counter
fildena 50 online
buy modafinil india
accutane 5mg
albuterol canadian pharmacy no prescription
modafinil medication
aurogra 100 for sale
albuterol prescription drug
suprax 400 mg gonorrhea
generic viagra soft tabs uk
finasteride 1mg cost
lasix canada no prescription
retin a 0.25 gel
cost of 300 mg omnicef
buy viagra pills online in india
pharmacy home delivery
furosemide 40 mg prescription
viagra
floxin 400 mg
noroxin tablets
buy malegra pills
biaxin 500 mg online
atarax 25mg tab
What a data of un-ambiguity and preserveness of precious experience concerning unexpected feelings.
valtrex for sale cheap
viagra soft 100mg online canadian pharmacy
female viagra sale in singapore
retino 0.25 cream
retino 0.25
cozaar canada
baclofen 2018
viagra soft tabs online
50mg prednisone tablets
silvitra 120 mg
tamoxifen arimidex
5mg prednisone
keflex 500mg medication
valtrex 500mg price in usa
can you buy baclofen over the counter us
sumycin over the counter
diflucan online canada
nolvadex 20 mg price in india
omnicef uti
purchase keflex online
buy generic viagra online cheap
acyclovir cream
zyvox cost in canada
finasteride 5 mg tablet
generic for ventolin
cozaar 100
valtrex tablet
minocycline 50 mg tablet price
reputable overseas online pharmacies
where can i purchase clomid over the counter
cost of minocin
best online foreign pharmacy
how to buy female viagra online
buy levothyroxine online
seroquel 10mg
sumycin 250 mg
minocycline 50 mg
cefadroxil 250 mg capsules
suprax tablet
Oh my goodness! Incredible article dude! Thanks, However I am going through difficulties with your RSS. I don’t know why I am unable to subscribe to it. Is there anyone else getting identical RSS problems? Anyone who knows the solution will you kindly respond? Thanx!!
baclofen over the counter
buy generic cialis online in usa
lisinopril 5mg tabs
vantin over the counter
buy modafinil 2019
generic propecia no prescription
azithromycin otc canada
aurogra tablets
synthroid average cost
generic for proscar
propecia rx
biaxin 250 mg
viagra 25 mg tablet price
amoxicillin over the counter in canada
provigil generic over the counter
canadian pharmacy cialis 40 mg
buy cheap propecia canada
Have you ever considered about including a little bit more than just your articles? I mean, what you say is fundamental and all. Nevertheless think about if you added some great graphics or video clips to give your posts more, “pop”! Your content is excellent but with images and clips, this site could certainly be one of the greatest in its niche. Terrific blog!
valtrex drugstore
valtrex 1000 mg price canada
finpecia tablet
deltasone otc
augmentin 825 mg
cozaar cost 100mg
can i buy azithromycin over the counter in us
seroquel
online pharmacy non prescription drugs
noroxin online
sildalis tablets
advair 2017 coupon
malegra dxt 130 mg
biaxin uti
drug cozaar
minocin 100mg mexico
generic for prinivil
tretinoin online without prescription
buy provigil
roxithromycin 150 mg cost
ceftin for sinus infection
buy malegra pills
finasteride cost
avodart 0.5 mg tab
I read this article fully concerning the comparison of latest and previous technologies, it’s awesome article.
myambutol generic
chloramphenicol tablets brand name in india
Every weekend i used to pay a quick visit this web site, as i wish
for enjoyment, for the reason that this this web
page conations genuinely fastidious funny stuff too.
austria pharmacy online
amoxicillin 650 mg
furosemide buy online
chloromycetin cream
valtrex brand
cefixime 400 mg
how much is the advair
lisinopril 10 mg order online
minocin costs canada
buy prednisone with paypal
generic azithromycin cost
aurogra
Hey there! This is my 1st comment here so I just wanted to give a quick shout out and tell you I genuinely enjoy reading through your blog posts. Can you suggest any other blogs/websites/forums that go over the same subjects? Thank you so much!
lisinopril 5 mg daily
how to get azithromycin over the counter
silvitra 120mg pills
lisinopril 5 mg pill
biaxin 500 mg coupon
viagra 50 mg price india
provigil 200 mg price
baclofen 20 mg
zyvox generic
biaxin tablets
how much is 100 mg viagra
suhagra for sale
buy baclofen in uk
Hi would you mind letting me know which webhost you’re working with? I’ve loaded your blog in 3 completely different web browsers and I must say this blog loads a lot quicker then most. Can you suggest a good web hosting provider at a reasonable price? Cheers, I appreciate it!
international online pharmacy
zanaflex migraine
buy stromectol uk
generic zofran online
buy paxil without prescription
buy tetracycline 500mg online
I’m really enjoying the design and layout of your site. It’s a very easy on the eyes which makes it much more enjoyable for me to come here and visit more often. Did you hire out a designer to create your theme? Outstanding work!
order accutane online uk
how to get accutane
paxil for panic attacks
furosemide 80 mg coupon
aurogra 100 for sale
rx wellbutrin
Unquestionably believe that which you stated. Your favorite justification appeared to be on the internet the simplest thing to be aware of. I say to you, I definitely get irked while people consider worries that they plainly do not know about. You managed to hit the nail upon the top as well as defined out the whole thing without having side effect , people can take a signal. Will likely be back to get more. Thanks
glucophage brand cost
how to buy cialis in india
prednisolone tablets 25mg
cost of prednisolone uk
effexor coupon
canada discount pharmacy
plaquenil 200mg tablets 100
erectafil 2.5
clonidine anxiety
tadacip 10 mg
budesonide brand name australia
metformin 1g
cipro south africa
price of deltasone
prednisone 473
ciprofloxacin generic
medicine citalopram 10mg
cheap tadalafil online
cheap viagra tablet
buy xenical 120mg online usa
cheap suhagra
toradol pain
cialis generic over the counter
canadian neighbor pharmacy
plaquenil purchase online
lasix no preiscription
buy prednisolone online
where to purchase accutane
can you buy plaquenil over the counter
zoloft price australia
buy online cialis 20mg
voltaren prescription canada
budesonide 3 mg cap
doxycycline cost
clonidine canada
sildenafil coupon 50 mg
cost of paxil
how to get prednisone without a prescription
valtrex brand
diflucan over the counter usa
cheap strattera online
aurogra 100 for sale
buy cheap generic propecia
buy tadacip 20mg
fluoxetine prescription cost uk
best no prescription pharmacy
Hey! This post could not be written any better!
Reading through this post reminds me of my old room mate!
He always kept chatting about this. I will forward this page to him.
Fairly certain he will have a good read. Thank you
for sharing!
buy clomid nz
synthroid average cost
doxycycline cheap uk
buy zanaflex
pharmacies in canada that ship to the us
trazodone 100 mg coupon
buy prozac no prescription
lasix online uk
azithromycin 500 without prescription
can you buy terramycin over the counter
buy prozac tablets
advair diskus price in india
fildena 100 mg online
trental pentoxifylline
cialis coupon 20mg
buy accutane online usa
flomax price in india
ventolin for sale canada
amoxicillin 500 capsule
cheap stromectol
tetracycline prescription cost
order lasix 40 mg
how much is valtrex cost
dexamethasone cost usa
erectafil 10 mg
furosemide 20 mg where to buy
how much is diflucan
buy hydroxychloroquine uk
strattera generic canada cost
diclofenac australia
generic antabuse online
tetracycline 500 mg tablet
advair brand name
generic for effexor xr
furosemide 20 mg tab cost
online pharmacy group
ventolin order
canadian pharmacy 1 internet online drugstore
of course like your web-site however you need to check the spelling on quite a few of your posts. Several of them are rife with spelling problems and I find it very bothersome to tell the truth then again I will certainly come back again.
desyrel brand name
No matter if some one searches for his necessary thing, thus he/she wants to be available that in detail, thus that thing is maintained over here.
advair cost in mexico
citalopram buy online
zanaflex 2 mg
legitimate online pharmacy
120 mg propranolol
dexamethasone 6 mg
zithromax z-pak
synthroid armour
cheap generic tadalafil uk
female viagra pills
tadalafil online united states
ciprofloxacin 250 mg tablet
motrin 6
antabuse tablets australia
medication ciprofloxacin 500mg
price of antabuse
cialis 50mg price in india
buy xenical online cheap canada
where can i buy kamagra oral jelly in london
best online pharmacy india
erythromycin cheap
trazodone 300 mg tablet
citalopram 2mg
where to get finasteride
trazodone brand name usa
prednisone 8 pills
zoloft 300 mg
prednisolone sodium
dexamethasone pharmacy
buy generic valtrex online cheap
I don’t know if it’s just me or if everyone else experiencing problems with your website. It seems like some of the text within your posts are running off the screen. Can someone else please comment and let me know if this is happening to them too? This could be a problem with my web browser because I’ve had this happen before. Thank you
synthroid online no prescription
tetracycline 324
mexico cipro
buy accutane 10 mg
1mg dexamethasone
capsule online pharmacy
how to get colchicine
motrin 800mg medicine
trazodone hcl 50mg
valtrex for sale canada
order accutane on line no prescription
provigil online prescription
valtrex 500 mg
order valtrex onlines
generic prozac cost
metformin medication
buy trental 400 mg online
buy amoxicillin mexico
order prednisolone
acticin over the counter
plaquenil 50 mg
accutane uk
buy tadacip 10
strattera generic best price pharmacy
tetracycline 250mg capsules online
suhagra tablet price india
Hi to all, as I am in fact keen of reading this webpage’s post to be updated regularly. It includes good information.
pharmacy coupons
all med pharmacy
propecia medicine
where to purchase elimite
pharmacy discount coupons
buy tetracycline
online doxycycline prescription
aurogra 100mg tablets
trazodone 150 mg pill
anafranil 10
16 mg dexamethasone
cheapest online pharmacy india
best price tadalafil online
dexamethasone brand name canada
buy suhagra with paypal
buy viagra tablet online india
dexamethasone 0.25 mg
tadacip 20mg tablet
elimite cost
Hi! I just would like to give you a huge thumbs up for the great info you’ve got here on this post. I will be coming back to your site for more soon.
prednisolone tablets
where to buy doxycycline over the counter
buy desyrel online
canadianpharmacyworld
generic acticin
ivermectin
tadacip 20 prescription
safe online pharmacies
buy cipro
viagra for sale in usa
erythromycin buy uk
azithromycin 250mg
colchicine prescription medicine
furosemide tablets 40 mg for sale
6mg tadalafil
kamagra online pharmacy india
buy kamagra jelly
diflucan cream price
zoloft
www pharmacyonline
ivermectin cream 1%
topical ivermectin cost
canadian pharmacy discount coupon
dexamethasone 2mg tablets price
tizanidine caps
wellbutrin 200
cost of bupropion
where can i get zoloft
ivermectin 250ml
generic colchicine canada
2 synthroid
trazodone capsules
average cost of metformin
online pharmacy dubai
probenecid colchicine tablets
My partner and I absolutely love your blog and find a lot of your post’s to be exactly I’m looking for. Do you offer guest writers to write content for yourself? I wouldn’t mind creating a post or elaborating on many of the subjects you write related to here. Again, awesome web log!
where can i buy erythromycin gel
dexamethasone 2 mg price
buy cipro online canada
baclofen 40 mg
erectafil 20 mg price
best generic prozac 2018
generic for celebrex
dexamethasone usa
stromectol cream
lasix cost
trazodone order
generic zithromax india
buy valtrex canada
how much is generic valtrex
amoxicillin india
clonidine for sleep
viagra australia over the counter
pharmacies in canada that ship to the us
purchase antabuse online
tizanidine without prescription
budesonide 250 mcg
metformin 100 mg price
buy orlistat online canada
online pharmacy uk prednisolone
cafergot online
buy propranolol 10 mg
tadalafil otc usa
flomax 0.4 mg price
flomax cost
inderal 10 medicine
accutane pills buy
baclofen 10mg tablets price
Hi there all, here every one is sharing such familiarity, so it’s pleasant to read this blog, and I used to go to see this weblog daily.
purchase cialis online cheap
doxycycline hyclate 100 mg cap
tadacip online india
lisinopril 5mg
zoloft tabs
onlinecanadianpharmacy 24
generic colchicine 0.6 mg
online propecia canada
dexamethasone 5
trental 400 tablet
diclofenac price in india
zyban tablet price in india
prednisolone 1 cost
trazodone 150 mg
prednisone prednisolone
trazodone 100 mg tablet
cafergot uk
cheap valtrex for sale
budesonide 32 mcg
tizanidine 6 mg coupon
diflucan 300 mg
colchicine 0.6 mg cost
effexor tablets
where to get azithromycin
celexa 20mg cost
azithromycin canada
accutane otc drug
online pharmacy australia viagra
zoloft for sale australia
stromectol generic
zestoretic coupon
albuterol for daily use
cheap tadacip
baclofen 10 mg
I rarely drop responses, however i did some searching and wound up here Model-Driven Engineering (MDE) in a nutshell
– Anton Antonov. And I actually do have 2 questions for you if it’s allright.
Could it be simply me or does it look as if like some of the responses
look like they are coming from brain dead visitors?
😛 And, if you are posting at other places, I’d like to keep up
with everything new you have to post. Could you make a list of the complete urls
of all your shared pages like your linkedin profile, Facebook page
or twitter feed?
my blog: 05 honda accord
stromectol medicine
buy antabuse without a prescription
paroxetine 7.5 mg
kamagra brand oral jelly
order antabuse
can i buy prednisone over the counter in usa
stromectol medication
lisinopril buy without prescription
stromectol order online
cheap viagra online united states
trazodone 40 mg
buy tadacip with paypal
american online pharmacy
erectafil 40
strattera 120 mg daily
genuine viagra australia
clonidine 0.1 mg oral tablets
antabuse tab price
strattera cap 18mg
cailis
where can i get wellbutrin
synthroid thyroid
trazodone price australia
buying celebrex in mexico
celebrex 20 mg
prednisone 50 mg price
inderal la generic
xenical cap 120mg
propranolol 40 mg brand name
buy azithromycin without prescription
baclofen 20 mg cost
toradol buy
buy antabuse online uk
canadian pharmacy antibiotics
cheap budesonide
stromectol prices
budesonide prices pharmacy
deltasone costs
can you buy elimite cream over the counter
canada pharmacy coupon
sumycin 250
dexamethasone 60 mg
where can i buy sildenafil tablets
antabuse price south africa
strattera over the counter
aurogra
lasix 12.5mg cost
buy viagra soft
cafergot online
erectafil 40 mg
zoloft generic
generic tadalafil tablets
zanaflex
best modafinil
tadacip 20 mg uk
tadacip india price
where to buy generic cialis online
offshore pharmacy no prescription
baclofen cream over the counter
prednisolone buy online
generic viagra sildenafil citrate
propecia tablets price in india
8662329020 zofran
orlistat 120 mg buy online uk
buy roaccutane
best place to purchase cialis
Wow, wonderful blog layout! How long have you been blogging for? you make blogging look easy. The overall look of your site is magnificent, let alone the content!
synthroid 150 mcg
prednisolone price uk
glucophage tablet 250 mg
azithromycin over the counter nz
canada pharmacy happy family store
effexor xr generic
canadian pharmacy online ship to usa
clomid prescription australia
buy suhagra with paypal
legitimate online pharmacy uk
diclofenac over the counter in europe
Spot on with this write-up, I seriously think this web site needs far more attention. I’ll probably be back again to read through more, thanks for the information!
budecort 100
colchicine buy online uk
amoxicillin 150 mg
buy propecia online 5mg
cost of baclofen
zoloft online europe
cheap generic cipro without prescription
canadian tadacip
buy cheap xenical
how much is zoloft
plaquenil online
diclofenac 150
how to buy clomid online uk
how to get sildenafil
tadalafil 5 mg tablet coupon
buy clomiphene citrate online uk
aurogra 100
erythromycin tablet 50 mg
dexamethasone buy uk
how much is viagra in usa
zofran mexico
modafinil 100mg cost
furosemide 60 mg
buy clonidine online no prescription
propranolol online pharmacy
cheap online pharmacy
generic prednisolone
100 mg prozac
kamagra online uk
super pharmacy
cafergot
ciprofloxacin 500 mg capsules
aurogra 100 for sale
canadian flomax
canadian pharmacy 24
flomax nasal spray
paroxetine 40 mg tablets
paxil 20mg
advair medicine
lasix canadian pharmacy
how much is valtrex cost
20mg cialis cost
how to get metformin online
fluoxetine hcl 20 mg
amoxicillin for sale no prescription
fildena 25 mg
240 mg celexa
medicine celebrex 200 mg
diflucan 750 mg
furosemide 100 mg tablets
synthroid 88 mcg tablet
effexor 100mg
buy 20 mg tadacip
Онлайн казино радует своих посетителей более чем двумя тысячами увлекательных игр от ведущих разработчиков.
2.5 mg cialis daily
desyrel drug
how to order cialis from india
order pharmacy online egypt
tizanidine 40 mg
cialis 800 mg
buy soft cialis
erectafil 5 mg
zoloft discount
hydroxychloroquine 50 mg
doxycycline prices
synthroid no prescription
canadian pharmacy online cialis
buy hydroxychloroquine online
cafergot tablets buy online
buy cheap xenical online
anafranil for ocd
online pharmacy in turkey
elimite
buy lioresal online
trazodone pill
reliable rx pharmacy
best accutane
100mg sildenafil online
It’s remarkable to go to see this web site and reading the views of all friends regarding this post, while I am also eager of getting experience.
medstore online pharmacy
advair without a prescription
400 mg sildenafil
synthroid 50 mg price
fildena 100 mg for sale
erythromycin price uk
cheap metformin
budesonide medicine
where can i buy accutane online
Its like you read my mind! You seem to know so much about this, like you wrote the book in it or something. I think that you could do with some pics to drive the message home a bit, but other than that, this is fantastic blog. An excellent read. I’ll definitely be back.
motrin online
antabuse buy canada
tetracycline to buy
can i buy terramycin over the counter
cost of prednisolone
buy generic valtrex online cheap
where to get accutane cheap
hydroxychloroquine buy uk
prednisone generic brand
flomax 0.8
canadian pharmacy ed medications
orlistat online purchase
aurogra tablets
canadian pharmacy uk delivery
buy prednisolone tablets
disulfiram 500 mg tablets online
valtrex order online
canadian pharmacies not requiring prescription
viagra from australia
Онлайн казино отличный способ провести время, главное помните, что это развлечение, а не способ заработка.
valtrex 100 mg
clonidine hcl .2mg
cheap valtrex for sale
where can i get amoxicillin over the counter
generic xenical
dexamethasone where to get
lasix drug brand name
tadalafil 20mg online
top mail order pharmacies
trental 400 mg price
cheap prednisolone uk
propranolol online australia
can i buy valtrex online
clonidine prescription
doxycycline 40 mg cost
clomid 100g
legitimate online pharmacy uk
zestoretic 20 25
online pharmacy no presc uk
kamagra 100mg india
zofran generic cost
prozac 10 mg price
buy zanaflex
buy doxycycline uk
canada cialis generic online
best rx pharmacy online
modafinil price in india
budesonide 9 mg tablets
cost of trazodone
cheap accutane online
fildena 100
order fluconazole 150 mg for men
tempmail.en free temporary emails Get a Free Temporary Email Address Instantly
paxil cost
austria pharmacy online
cheap plaquenil
how do i get cialis
average cost of orlistat
happy family store
valtrex purchase online
metformin tab cost in india
cheapest terramycin
pharmacy online 365
can you buy accutane in mexico
colchicine 0.6 mg coupon
valtex without a prescription
colchicine cheapest price
2870 valtrex
furosemide 40 for sale
erythromycin generic price
zanaflex 2mg capsules
orlistat 120 mg
paxil er
propecia canada pharmacy
buy erectafil 5
brand zoloft
best india pharmacy
pharmacy wholesalers canada
ivermectin for humans
buy prednisone 20mg without a prescription best price
colchicine 1.2 mg
zestoretic 20 12.5 mg
flomax over the counter
ivermectin price usa
В нашем онлайн казино вы найдете широкий спектр слотов и лайв игр, присоединяйтесь.
generic zithromax azithromycin
fluoxetine 20mg prices
prednisone brand name canada
finasteride 1mg cost
where to purchase erythromycin
can you order flomax online
advair 250 mg
generic synthroid cost
fildena 120mg
buy metformin online uk
stromectol 12mg online
can i buy cialis in canada over the counter
budesonide 9 mg price
inderal 10 tab
lasix 250 mg
voltaren gel price canada
zoloft pills online
zoloft otc
synthroid 75 pill
effexor 25 mg tablet
dexamethasone 60 mg
aurogra 100 for sale
safe canadian pharmacy
which pharmacy is cheaper
where can i get trazodone
accutane australia buy online
Thank you for some other informative web site. Where else may I am getting that kind of info written in such a perfect way? I have a venture that I am simply now operating on, and I have been at the glance out for such information.
cialis 60 mg canada
where to purchase diflucan
cost of generic strattera
order kamagra oral jelly
sildenafil 2 mg cost
buying strattera online without prescription
price of tetracycline tablets in india
valtrex pills price
ventolin pill
how to buy cialis without prescription
flomax price comparison
disulfiram price in india
generic diflucan otc
tetracycline medication
price of generic wellbutrin
doxycycline price 100mg
cipro 100 mg
clonidine anxiety
plaquenil 200 mg 60 tab
tadacip 20 canada
ciprofloxacin 500 mg prescription
pentoxifylline trental
prednisone 50 mg cost
orlistat 120 mg price uk
buy sumycin
buy flucanozole
lopressor generic cost
family care rx
prednisolone tablets over the counter
Casino bonusyFree Spiny dnesBonus bez vkladuBonus za registraciPeníze zdarmaBonusové kódyBonus k narodeninámRewards bonusy Je tu jistá podobnost oproti předchozí nabídce, ačkoli Zet Casino má přiznivější bonusové podmínky. Záleží ale i na tom, které casino u vás vede. Anebo na tom, jestli jste už jednu nabídku vyčerpali… Registrovat se totiž samozřejmě můžete do vícera online casin. Přejděte na nabídku Tipsport a vyberte si bonus pro vás. Kliknutím na něj se dostanete na webové stránky Tipsportu, kde dokončíte registraci a získáte bonus. V našich online casinech mohou hráči získat výhradně bonusy v CZK. Částku 7 € a více nabízí hned několik licencovaných provozovatelů. Více najdete v našem přehledu TOP casino bonusů.
https://bookmarksbay.com/story15258267/bingo-s-bonusem
Na webu naleznete také návody a recenze desítek nejoblíbenějších online výherních automatů. U každého automatu vám doporučíme casina, kde získáte nejen nejvyšší bonusy do hry, ale také možnost si danou hru zahrát zdarma, bez nutnosti vkladů do hry. Tuto možnost nabízí nejlepší online kasina v režimu hry pro zábavu, kde vám dají možnost hrát pouze o virtuální kredity. Máte rádi adrenalin a napětí během zábavy s online automaty? Chcete hrát bezpečně, zodpovědně a s co nejlepšími bonusy? Sledujte náš web CasinoAutomaty.cz. Nechcete zmeškat žádnou zajímavou akci? Stačí se zaregistrovat k odběru našeho Newsletteru a budete vždy v ten pravý čas ve hře. Famous Casino Games Real Money Withdraw Cz
buspar 15
prednisolone 25mg tablets cost
canadian pharmacy online cialis
azithromycin 4 tablets
buy citalopram 20mg online uk
hydrochlorothiazide price in india
buy albenza online
best online pharmacy
albuterol 900 mcg
robaxin 750 tablets
buy provigil online europe
retino 0.05
prednisolone 10mg in usa
motilium medicine
buy diflucan online canada
furosemide 500 mg online
citalopram hbr 10 mg for anxiety
toradol pill 10mg
citalopram
zanaflex generic price
dexona tablet price
average cost of ciprofloxacin
doxycycline 75 mg tablet
buy robaxin online without prescription
family rx pharmacy
motilium price south africa
buy vermox over the counter
buy tretinoin online australia
buy phenergan medicine
buy clomid online without prescription
prescription drug tizanidine
buy real valtrex online
tizanidine 4 mg coupon
doxycycline 100mg pills
price of levaquin
buy diflucan online without prescription
retino 05
where can i buy oral ivermectin
order acyclovir online uk
canadianpharmacyworld
how to get ventolin
best canadian pharmacy
levitra 20mg price in canada
metformin without a script
zestoretic 20 12.5 mg
pharmacy price 25 mg allopurinol
combivent from canada
happy family drugstore
phenergan online pharmacy
generic retin a from mexico
robaxin 500 mg generic
propranolol 20 mg coupon
generic tadalafil paypal
how much is dexamethasone 4 mg
cipro pharmacy
average cost of tamoxifen
phenergan cream 10g
modafinil for sale south africa
clonidine gel
clonidine 150 mg
advair generic usa
albuterol 90 mcg coupon
albendazole 400 mg price in india
maple leaf pharmacy in canada
albuterol in mexico
can you buy modafinil pills
acyclovir cream price
over the counter advair diskus
lisinopril 20 mg price in india
propecia buy
prednisone 20 mg tablet
order tizanidine online
49 mg accutane
prinzide zestoretic
buy viagra cialis
lyrica price canada
lasix brand name
can i buy doxycycline in india
your pharmacy online
cheap avodart
levaquin online
happy family store coupon code
synthroid 0.025
how to get provigil online
nolvadex online india
metformin tablets 500mg
buspar pill
advair 250 50 mcg
modafinil prescription uk
retino 0.05
1.25 albuterol
I’ll right away seize your rss as I can’t to find your e-mail
subscription hyperlink or newsletter service. Do you’ve any?
Kindly let me understand so that I could subscribe.
Thanks.
price for robaxin
buspar online pharmacy
levitra best price uk
buy tizanidine 4mg online
top 10 pharmacies in india
canadian pharmacy viagra
tretinoin 0.05 cost
robaxin 750 price
tretinoin cream online pharmacy mexico
happy family canadian pharmacy
how to get doxycycline 100mg
Bu siteler, kullanıcılara gerçek para veya sanal para ile slot makineleri oynama imkanı sunar.
buy baclofen online
dexamethasone 6 mg tablet
albuterol hfa inhaler
amoxicillin for sale in us
advair medicine
buy provigil
levitra uk pharmacy
modafinil nz
lyrica 75 mg generic
hydrochlorothiazide 30 mg daily
buy toradol online
order albuterol online no prescription
how to buy propecia
indocin 75 mg
buy metformin no prescription canadian pharmacy online
lasix 80
cipro 500mg prices
order paxil
avana 100 mg
zoloft cap
tamoxifen for sale
happy family canadian pharmaceuticals online
propranolol 80 mg
cost of provigil 2018
vermox south africa
doxycycline 100 mg tablet
azithromycin pills over the counter
baclofen 5 mg tablet price
albuterol 2mg
levaquin.com
buy modafinil canada pharmacy
synthroid price
cross border pharmacy canada
can you buy finasteride over the counter
propecia generic
generic lyrica 2019
azithromycin india
doxycycline 50 mg cost
buspar no prescription
modafinil 25mg
modafinil pills for sale
zestoretic 20 25 mg
hydrochlorothiazide 12.5
buy modafinil mexico
lyrica canada
generic super avana
avodart canada pharmacy
indocin cost
cipro rx
generic ventolin price
zoloft 100mg price in usa
where can i buy levitra online
tizanidine tab 2mg
buy accutane mastercard
how much is dexamethasone 4 mg
ivermectin online
Bankacılık işlemlerim için SMS onayı güvencenin anahtarıdır.
3 diflucan pills
indocin purchase
zoloft tablets canada
650 mg citalopram
buy lasix 100mg
furosemide 160
buy accutane 2017
where to get prednisolone
robaxin 500mg canada
online canadian pharmacy coupon
feldene generic
cost of doxycycline in canada
albuterol 108 mcg
effexor 37.5 mg
doxycycline pills over the counter
dexamethasone 200 mg
cipro rx
prescription drug tizanidine
baclofen brand
where can i buy diflucan over the counter
provigil price usa
medication cipro 500 mg
happy family store
generic allopurinol 300 mg
canadian pharmacy no prescription
no script pharmacy
effexor prescription cost
legitimate mexican pharmacy online
us pharmacy no prescription
doxycycline 40 mg generic
how much is advair diskus
zestoretic 10 12.5 mg
cipro in canada
Thanks for finally writing about > %blog_title% < Liked it!
provigil pills for sale
obagi tretinoin cream .05
tretinoin india pharmacy
baclofen over the counter
levitra 10
rate canadian pharmacies
buy ciprofloxacin online
robaxin 500 generic
cialis 50 mg online
vardenafil 10 mg tablet
nolvadex rx
baclofen generic price
buspar medicine generic
dexamethasone 0.25 mg tablet
zithromax 250 price
clomid without prescription
valtrex for sale cheap
how to get avodart
vermox online sale usa
where to buy modafinil uk
retino 0.025 gel
finpecia
phenergan online australia
feldene drug
accutane price in india
celexa 1101
doxycycline usa
levaquin without prescription
doxycycline 100mg india
can i buy cipro in mexico
accutane prescription online
ciprofloxacin 500mg price uk
tretinoin online india
combivent nebulizer
prednisolone 10 mg no prescription
azithromycin 750
accutane 30 mg coupon
cipro online no prescription in the usa
furosemide discount
ventolin brand name
cost of clomid
lasix online pharmacy
can you buy synthroid online
I’m not sure where you are getting your info, but good topic. I needs to spend some time learning more or understanding more. Thanks for magnificent information I was looking for this information for my mission.
can i buy allopurinol online
online pharmacy for sale
propecia singapore
buy nolvadex online uk
buy malegra
purchase amoxicillin
azithromycin 500mg canada
buy levitra no prescription
where can i get retin a
cialis 2mg
robaxin 850 mg
albendazole price in mexico
robaxin 500 mg price
albuterol generic
Istanbul’s Bosphorus tour is a visual feast, with enchanting sights at every turn.
happy family drug store
accutane price without insurance
albuterol for sale uk
where can i purchase clomid
lopressor 50 mg cost
acyclovir 5 cream price
dapoxetine for sale uk
cialis canada online pharmacy
drug paxil
malegra dxt
diflucan pills
9 metformin
online pharmacy uk prednisolone
flomax 23497
clonidine 2 mg
effexor 75 mg tablet
buy tamoxifen aus
robaxin 750mg
buy accutane without prescription
how much is paxil in canada
cialis generic price in us
baclofen 10mg pill
online shopping pharmacy india
lisinopril generic price comparison
cheapest dapoxetine online
tretinoin 0025
ventolin cost canada
paroxetine hcl 40 mg
lasix 40 mg tablet
doxycycline price south africa
robaxin price uk
buy lisinopril 20 mg
provigil pill
modafinil pills india
can you buy baclofen without a prescription
celexa 100mg
20 mg toradol
tizanidine online pharmacy
toradol tablets australia
propecia 0.5 mg
where can i buy albuterol over the counter
prednisolone buy
can i buy albuterol from canada
order doxycycline 100mg without prescription
buspar canada
vermox drug
cipro 250 mg
order levaquin online
dexona tablet price in india
robaxin 750 cost
medication cipro 500 mg
paroxetine pills 40 mg
buy modafinil canada
cost of levaquin
where can you buy albuterol
levitra tab 20mg
what’s the best online pharmacy
advair 500 50
mexican online mail order pharmacy
how to get valtrex online
albendazole over the counter australia
modafinil australia
zestoretic 20 12.5
allopurinol 1
lisinopril 5 mg tablet price
order flomax online
effexor 150 mg price
zithromax 250 tablet
how to buy modafinil in usa
retino 0.25 cream
where can you buy nolvadex
piroxicam over the counter
vermox buy online uk
effexor 187.5 mg
where to buy accutane online uk
diflucan brand name in india
no rx pharmacy
buy acyclovir online uk
ivermectin cost in usa
plaquenil headache
augmentin 875 125 mg tablet
dexamethasone tablets canada
order effexor
ivermectin oral solution
Begin on a wander during the USA zip codes starting here! Our website houses the most complete and up-to-date assemblage of postal codes an eye to all cities in the United States of America.
?? Far-flung Database:
Our statistics is meticulously curated and organized, enabling you to easily find the zip code you want without wasting a minute.
?? Quick Search:
Take advantage of our intuitive and lightning-fast search motor to with all speed come across the postal code you are interested in.
?? Enquire into the США:
Locate the uncharted as you pilgrimages via the U.S. map and delve into particular insights through zip rules information.
?? Burg Linkages:
Look over in the course related zip codes and survey neighboring areas to more advisedly understand the country’s geography.
?? Exchange for Business and Relocations:
The unmatched way on subject and dear acquisition! Blueprint your relocation, enterprise burgeoning, or marketing campaigns with zip codes at your fingertips!
?? With no At hand:
Access our website 24/7 from any thingamajig, whether it be a computer, phone, or tablet.
Link with the in all respects of ZIPscout and cover the США from strand to coast, exploring each peerless postal code. Your expedition of American cities and states starts with a cull click! ??
?? https://blockreader.online – begin your research right stylish!
Begin on a transition during the USA zip codes starting here! Our website houses the most complete and up-to-date collection of postal codes through despite all cities in the United States of America.
?? Far-flung Database:
Our information is meticulously curated and organized, enabling you to easily bring to light the zip maxims you want without wasting a minute.
?? Rapid Search:
Take advantage of our intuitive and lightning-fast search engine to instantly place the postal lex non scripta ‘common law you are interested in.
?? Explore the USA:
Ferret out the unknown as you travel via the U.S. map and delve into local insights through zip standards information.
?? Burg Linkages:
Skim through through associated zip codes and survey neighboring areas to better know the mother country’s geography.
?? Exchange for Business and Relocations:
The matchless tool for point and personal say! Blueprint your relocation, enterprise dilatation, or marketing campaigns with zip codes at your fingertips!
?? Indubitably Get-at-able:
Access our website 24/7 from any device, whether it be a computer, phone, or tablet.
Rivet with the world of ZIPscout and cover the USA from seaside to sea-coast, exploring each incomparable postal code. Your research of American cities and states starts with a single click! ??
?? https://blockreader.online – enter on your research moral now!
generic propecia from india
ciprofloxacin over the counter
malegra 25
zanaflex for sale
online pharmacy fungal nail
hydrochlorothiazide 50
propecia 0.5 mg
retino 0.05
can i buy accutane over the counter
phenergan tablets over the counter
robaxin drug
albuterol coupon
where can i buy clomid tablets in south africa
Board on a trip from stem to stern the США zip codes starting here! Our website houses the most complete and up-to-date assemblage of postal codes on account of all cities in the United States of America.
?? Large Database:
Our statistics is meticulously curated and organized, enabling you to easily reveal the zip cypher you difficulty without wasting a minute.
?? Rapid Search:
Work our intuitive and lightning-fast search apparatus to right away come across the postal protocol you are interested in.
?? Enquire into the США:
Locate the unexplored as you go at the end of one’s tether with the U.S. map and delve into local insights in the course zip code information.
?? Urban district Linkages:
Flip in the course interconnected zip codes and explore neighboring areas to haler recognize the wilderness’s geography.
?? For the sake Business and Relocations:
The matchless agency repayment for business and personal acquisition! Devise your relocation, subject dilatation, or marketing campaigns with zip codes at your fingertips!
?? Clearly Accessible:
Access our website 24/7 from any trick, whether it be a computer, phone, or tablet.
Tie in with the in all respects of ZIPscout and investigate the США from coast to seaboard, exploring each peerless postal code. Your expedition of American cities and states starts with a cull click! ??
?? https://blockreader.online – start out your survey bang on modern!
average cost of tamoxifen
doxycycline 200
no prescription ventolin hfa
buy albuterol
citalopram brand in india
Thanks designed for sharing such a nice idea, article is nice, thats why i have read it fully
generic levitra in us
cheap clomid pills
tizanidine 2mg medication
ventolin 4mg
metformin hcl 1000
Board on a journey through the США zip codes starting here! Our website houses the most complete and up-to-date assemblage of postal codes through despite all cities in the United States of America.
?? Far-flung Database:
Our information is meticulously curated and organized, enabling you to away reveal the zip encode you want without wasting a minute.
?? Alert Search:
Work our intuitive and lightning-fast search locomotive to instantly come across the postal protocol you are interested in.
?? Enquire into the США:
Ferret out the unexplored as you travel through the U.S. map and delve into particular insights through zip code information.
?? Conurbation Linkages:
Skim through in the course mutual zip codes and explore neighboring areas to haler know the mother country’s geography.
?? Exchange for Province and Relocations:
The unmatched way on point and dear use! Script your relocation, enterprise stretching, or marketing campaigns with zip codes at your fingertips!
?? Indubitably Accessible:
Access our website 24/7 from any trick, whether it be a computer, phone, or tablet.
Connect with the domain of ZIPscout and investigate the USA from seaside to coast, exploring each solitary postal code. Your research of American cities and states starts with a cull click! ??
?? https://blockreader.online – inaugurate your survey right instantly!
ciprofloxacin 500 tablet
buy effexor online canada
zanaflex
robaxin 500 mg tablet
vermox tablet price
canadian mail order pharmacy
buy albuterol canada
buy prednisolone 5mg
metformin 134
lisinopril 49 mg
retin a cream us
where can i buy amoxicillin 500mg capsules uk
prednisolone 3 mg
buy modafinil usa online
allopurinol 300mg tablets
how much is generic provigil
diflucan cream
Launch on a wander through the США zip codes starting here! Our website houses the most encompassing and up-to-date gathering of postal codes an eye to all cities in the Synergistic States of America.
?? Large Database:
Our data is meticulously curated and organized, enabling you to easily hit upon the zip encode you need without wasting a minute.
?? Quick Search:
Use our intuitive and lightning-fast search engine to right away locate the postal protocol you are interested in.
?? Explore the США:
Meet with the unknown as you travel via the U.S. map and delve into local insights through zip code information.
?? Conurbation Linkages:
Look over in the course mutual zip codes and survey neighboring areas to haler sympathize the provinces’s geography.
?? For the sake Trade and Relocations:
The unmatched contrivance on corporation and dear say! Devise your relocation, duty burgeoning, or marketing campaigns with zip codes at your fingertips!
?? With no Accessible:
Access our website 24/7 from any trick, whether it be a computer, phone, or tablet.
Link with the in all respects of ZIPscout and obstruct the США from seaside to seaboard, exploring each incomparable postal code. Your expedition of American cities and states starts with a single click! ??
?? https://blockreader.online – begin your research front modern!
azithromycin 900 mg
discount cialis 10mg
best price malegra fxt usa
zestoretic 20 25 mg
order propecia online uk
hydrochlorothiazide brand name in canada
celexa 20 mg order online without prescription
buy cialis canada canadian drugstore
modafinil how to get
where can i buy zovirax cream
zoloft 50 mg generic
lyrica mexico price
cheap modafinil tablets
tretinoin cream generic
the happy family store
effexor xr prices
doxycycline 20 mg capsules
levitra 5mg price
tizanidine pill price
piroxicam 0.5
purchase advair from canada
discount pharmacy mexico
doxycycline 100 mg
It’s really a cool and helpful piece of information. I’m satisfied that you simply shared this helpful info with us. Please stay us informed like this. Thank you for sharing.
doxycycline for sale
Very energetic blog, I enjoyed that a lot. Will there be a part 2?
albuterol mexico
modafinil online us
15 mg buspar
modafinil india prescription
avodart prescription cost
tretinoin otc
modafinil 200mg australia
buy synthroid 150 mcg online
how much is plaquenil
retino 0.025 cream
robaxin for sale
where can i buy zovirax online
advair price in canada
buy nolvadex online
how to buy tadalafil online
tizanidine 4 mg price
where can i get accutane in australia
furosemide 12.5 mg
cheap cialis pills
ciprofloxacin 1000 mg
allopurinol on line
trustworthy online pharmacy
buy dexamethasone uk
safe canadian pharmacy
best generic accutane
where to buy albendazole online
generic retin a mexico
retino 0.05 gel
Быстромонтажные здания: финансовая польза в каждой детали!
В современной сфере, где время имеет значение, скоростройки стали настоящим выходом для компаний. Эти новейшие строения объединяют в себе высокую надежность, финансовую экономию и быстрое строительство, что делает их лучшим выбором для разнообразных предпринимательских инициатив.
Быстровозводимые здания цена
1. Быстрое возведение: Время – это самый важный ресурс в предпринимательстве, и экспресс-сооружения позволяют существенно сократить сроки строительства. Это чрезвычайно полезно в ситуациях, когда требуется быстрый старт бизнеса и начать прибыльное ведение бизнеса.
2. Финансовая экономия: За счет улучшения производственных процедур элементов и сборки на объекте, цена скоростроительных зданий часто уменьшается, по отношению к традиционным строительным проектам. Это позволяет получить большую финансовую выгоду и получить лучшую инвестиционную отдачу.
Подробнее на http://www.scholding.ru
В заключение, моментальные сооружения – это отличное решение для предпринимательских задач. Они комбинируют в себе ускоренную установку, экономичность и надежность, что делает их превосходным выбором для предпринимателей, готовых начать прибыльное дело и получать прибыль. Не упустите возможность сократить затраты и время, наилучшие объекты быстрого возвода для ваших будущих инициатив!
ciprofloxacin uk
can you buy modafinil online
lisinopril 40 mg brand name
tizanidine 100 mg
modafinil 200mg buy
azithromycin order
canadian pharmacy diflucan
northwest pharmacy canada
clomid 50g
canadian pharmacies not requiring prescription
price of inderal 10mg
buy accutane no prescription
prednisolone pack
modafinil 200 mg india
order robaxin without prescription canada
augmentin 825
robaxin coupon
indocin over the counter
toradol script
buy advair diskus online
prednisolone 5mg prices
albenza online pharmacy
lisinopril 30 mg cost
online pharmacy 365
canadian pharmacy service
malegra 120mg
happy family store pharmacy cialis
flomax kidney stones
lyrica 150 mg price australia
robaxin 500 cost
metformin from mexico to us
provigil without prescription
valtrex best price
buy modafinil uk paypal
prednisone rx
where to buy prednisolone
modafinil online mexico
albendazole prescription
albendazole buy usa
albuterol cheapest price
phenergan canada
where can i get accutane in australia
503 tizanidine 4mg
where to buy albendazole uk
tretinoin prescription singapore
purchase albendazole online
Anaheim, a bustling borough nestled in the determination of Orange County, California, is not even-handed acclaimed in the service of its world-famous Disneyland Turn to, but also for its diversified communities and expansive urban landscape. This diversity and extent are mirrored in its postal modus operandi, with the city being segmented into multiple ZIP codes. Here’s a direct look into Anaheim’s ZIP codes:
Intention of Multiple ZIP Codes:
Adipose cities like Anaheim often deceive multiple ZIP codes to streamline the letters confinement process. Each ZIP encode corresponds to a restricted characteristic of area or neighborhood, ensuring that mail and packages are sorted and delivered efficiently.
ZIP Jus civile ‘civil law’ Number:
Anaheim boasts a distribute of ZIP codes, starting from the 90620s and successful up to the 92899. This wide array of ZIP codes reflects the diocese’s vast область and the heterogeneous communities it houses.
ZIP Code Maps:
Suitable those who are more visually apt, Anaheim ZIP code maps are available. These maps provide a unquestionable visual model of the see segmented close to its postal codes. It’s a usable machine payment businesses, real class professionals, and down repay residents looking to understand the bishopric’s layout in terms of postal regions.
Financial and Demographic Variations:
Different ZIP codes in Anaheim potency bear assorted monetary and demographic profiles. Representing exemplification, the ZIP lex non scripta ‘common law 92805 weight have a different demographic makeup compared to 92804. Businesses often use this statistics for targeted marketing and service delivery.
Utility Beyond Mail:
While the elemental goal of ZIP codes is post sorting and delivery, they also about b dally a pivotal part in urban planning, difficulty services, and civic administration. For event, junior high school districts and voting zones puissance be determined based on ZIP code boundaries.
In conclusion, Anaheim’s ZIP codes are more than hardly numerical labels since send delivery. They present oneself insights into the city’s shape, demographics, and growth patterns. Whether you’re a remaining, a work p, or a visitor, mind these ZIP codes can take care of a clearer exact replica of this vibrant Californian city.
More details: https://bitinsight.online
prednisolone tablets 25mg
clonidine online
dapoxetine pills online
ventolin 100mcg online
metformin 250
Your style is very unique compared to other people I have read stuff from. Many thanks for posting when you have the opportunity, Guess I will just bookmark this site.
propecia order online
synthroid 120 mcg
albuterol australia
where can i get ciprofloxacin
buy zoloft online
buy modafinil uk india
hydrochlorothiazide otc
modafinil for sale online
azithromycin online pharmacy canada
can you buy azithromycin over the counter in canada
buy robaxin australia
doxycycline 50 medicine
foreign pharmacy no prescription
clonidine capsule
generic avodart canada
3 mg prednisolone pill
dexamethasone price
buy zestoretic
can i buy azithromycin online usa
flomax generic
albuterol over the counter usa
canadian pharmaceuticals online for ed
buying ventolin online
order levitra online usa
lisinopril 20 pills
retin a without a script
how to get modafinil in australia
best celexa generic
tizanidine average cost
effexor 37.5 mg
clonidine patch for hot flashes
retino 0.025 gel
buy modafinil 200
baclofen prescription cost
where to buy robaxin 750 in canada
canadian pharmacy 24 com
where to buy stromectol
how to buy nolvadex online
zoloft prescription cost
Flört, iki insan arasındaki özel bir bağın başlangıcıdır. Heyecan verici bir duygusal serüvene davetiye çıkarır.
robaxin 10
retin a online no prescription
plaquenil cost canada
Your style is very unique in comparison to other folks I have
read stuff from. Thanks for posting when you have the opportunity,
Guess I’ll just bookmark this site.
azithromycin 500 mg over the counter
vardenafil over the counter
buy accutane 5mg
where to buy feldene
albenza cost generic
buy cheap accutane
prednisolone tablets for sale uk
zithromax 600
vermox 500mg tablet price
diflucan discount coupon
retino 0.025 cream
prednisone 10mg tabs
lopressor 0.5
robaxin
levaquin 750 mg
buy provigil rx
toradol 30
buy generic levaquin
where can i get accutane cheap
diflucan mexico
propranolol inderal
how much is valtrex
doxycycline 100mg tablets cost
provigil tablet
retin a gel generic
feldene gel buy online
buy lasix
tamoxifen for sale online
dexamethasone 2 tablet
allopurinol 100mg tablets
effexor 300 mg
diflucan online usa
acyclovir no prescription
feldene capsule
canada to usa ventolin
albuterol prescription cost
online pharmacy without prescription
azithromycin 500 mg daily
clonidine hcl 0.2 mg
phenergan rx
how to get modafinil online
best price doxycycline uk
accutane prescription cost
tizanidine 4
diflucan 150mg tab
can you buy modafinil over the counter uk
capsule online pharmacy
furosemide 25 mg
buy inderal 40 mg
zoloft online order
furosemide purchase
buy clomid pills online
buy fourosimide on line
effexor medicine
cost of synthroid brand name
furosemide online
furosemide 500mg
prednisolone sodium
100mg celexa
tizanidine 4mg tab cost
Hi there, I found your web site via Google whilst searching for a similar topic, your web site got here up, it looks good. I have bookmarked it in my google bookmarks.
where can i buy diflucan 1
toradol pills
online effexor prescription
modafinil online pharmacy canada
cialis generic levitra viagra
modafinil in south africa
ciprofloxacin 750 mg price
ventolin online pharmacy
modafinil for sale
albuterol pills buy online
citalopram 20mg for sale uk
buy zoloft australia
ciprofloxacin 250mg price
online pharmacy delivery
vardenafil generic us
best pharmacy prices for cymbalta
phenergan 6.25
propecia pills price
resochina
chloroquin 155
Highly energetic article, I enjoyed that a lot. Will there be a part 2?
prednisone brand name cost
clonidine cost pharmacy
prednisone 10 mg purchase
buy tadacip online india
dipyridamole eye drops
furosemide 40 mg over the counter
chloroquine otc usa
acyclovir generic drug
trental 400 order online india
amoxicillin 875 costs
nolvadex 10mg
azithromycin tablets price in india
how to order amoxicillin online
zoloft generic tablet
amoxil pharmacy
prednisone 50 mg prices
prazosin tablet
kamagra oral jelly sale
mail pharmacy
50 mg phenergan
atenolol brand
retin a 05 cream from mexico
synthroid 200 mcg coupon
accutane online prescription cost
avodart 0.5 mg tab
where to buy clonidine
deltasone 20 mg tablet
provigil purchase
prednisolone uk buy
medicine lyrica 75 mg
tadacip 5mg price
silagra 100 price in india
buy erythromycin cream
buy dipyridamole
9 mcg mL approximately 8 hours after accidental ingestion purchase cialis
cafergot 1 100 mg
avodart 1mg
where can i purchase zithromax online
buy azithromycin online cheap
generic brand of avodart
The Lord of the Rings: The Fellowship of the Ring – The first installment in an epic fantasy trilogy that brings J.R.R. Tolkien’s Middle-earth to life in spectacular fashion.
diflucan medication
flomax online canada
metformin 500 mg er
zithromax 1000 mg pills
motilium canada
over the counter baclofen
buy erythromycin 500mg
buy ciprofloxacin online cheap without a prescription
propranolol for sale
diflucan
trental medication cost
buy suhagra 50 mg
acyclovir 800 mg coupon
buy vermox in usa
how much does permethrin cost
clonidine for dogs
vibramycin
buy vardenafil
diflucan oral
diflucan pill
amoxicillin 5 00mg
antabuse without a prescription
can you buy cialis in canada
paroxetine 20mg
silagra 50 mg india
prednisolone
doxycycline cheap uk
suhagra tablet online
augmentin canada pharmacy
buy diflucan cheap
buy modafinil online cheap
cymbalta prescription
buy colchicine online
doxycycline 500 mg capsules
motilium price canada
atenolol 50 mg cost
elimite buy online
diflucan online prescription
azithromycin 500 mg tablets cost
cymbalta 50 mg cost
erythromycin 1952
buy levitra pills online
diflucan generic brand
120 mg accutane daily
acyclovir 200 mg tablets
online pharmacy denmark
colchicine drug
retin a australia buy online
buy erythromycin cream
paxil ocd
colchicine 0.6 mg tablet coupon
prazosin cost uk
how to get cipro prescription
cost of phenergan tablets
generic retin a gel
lopressor 25 mg generic
azithromycin pills
lioresal cost
ciprofloxacin pharmacy
silagra 50 mg
buy prazosin 1mg
онлайн казино brillx сайт
brillx официальный сайт
Играя на Brillx Казино, вы можете быть уверены в честности и безопасности своих данных. Мы используем передовые технологии для защиты информации наших игроков, так что вы можете сосредоточиться исключительно на игре и наслаждаться процессом без каких-либо сомнений или опасений.Так что не упустите свой шанс — зайдите на официальный сайт Brillx Казино прямо сейчас, и погрузитесь в захватывающий мир азартных игр вместе с нами! Бриллкс казино ждет вас с открытыми объятиями, чтобы подарить незабываемые эмоции и шанс на невероятные выигрыши. Сделайте свою игру еще ярче и удачливее — играйте на Brillx Казино!
clopidogrel price comparison
lasix india
buy tetracycline tablets
motilium tablets
amoxil 250mg
azithromycin 250
cipro drug
medrol tablets uk
buy clomid from canada
zovirax 4.5 g
buy modafinil in us
accutane generic canada
levitra tablet price
suhagra 100mg online
cheap scripts pharmacy
anafranil generic cost
amoxicillin uk pharmacy
buy amoxil
diflucan 200 mg
order hydrochlorothiazide
azithromycin 500g
cost of dipyridamole
retin a cream from mexico
generic augmentin prices
Хотите получить идеально ровный пол без лишних затрат? Обратитесь к профессионалам на сайте styazhka-pola24.ru! Мы предоставляем услуги по стяжке пола м2 по доступной стоимости, а также устройству стяжки пола под ключ в Москве и области.
hydrochlorothiazide 50
order acyclovir cream
accutane canadian pharmacy
medication lyrica 50 mg
silagra 50 mg online
modafinil brand name
buy clomid over the counter
aralen hcl
buy laxis with mastercard
buy doxycycline from canada
clomid capsules
modafinil where to buy usa
hydrochlorothiazide without prescription
buy prednisone online india
lyrica medication generic
lyrica price
furosemide cost us
augmentin india
dipyridamole buy
best online no prescription antabuse
dipyridamole buy
valtrex for sale canada
buy diclofenac 75
valtrex 2 g
cheap ampicillin
medicine baclofen 10 mg
how to get baclofen in australia
dipyridamole 100mg tablets
doxycycline 100mg coupon
can you buy lisinopril over the counter
25mg prednisolone
order prednisone from canada
propecia cost comparison uk
kamagra 100mg oral jelly india
buy tadacip online
clomid generic
best price for lisinopril
chloroquine phosphate 500 mg 7 tablets
buy suhagra 50 mg online india
silagra 100mg
prazosin rx coupon
buy tetracycline tablets
buy valtrex usa
erythromycin buy online
acyclovir generic cream
diflucan over counter
motilium australia
plavix generic drugs
tamoxifen online pharmacy
pharmacy discount card
sale clomid
finasteride online 1mg
silagra tablet
suhagra online purchase
I recommend this forum to everyone as a source of knowledge. It’s free and very useful!
flomax prescription
buy suhagra 100mg
cialis purchase online
reliable rx pharmacy
can i buy metformin over the counter in uk
hydrochlorothiazide online pharmacy
generic-levitra
lopressor brand
order tadacip 20 mg
metformin online india
acyclovir 800 mg daily
buy discount cialis online
buy generic valtrex on line
can you buy azithromycin otc
10mg levitra
lyrica 25 mg capsule
colchicine without prescription
polish pharmacy online uk
clonidine buy uk
where to buy clomid without prescription
propecia 5mg sale
clomid 50mg online
buy vermox over the counter
lioresal 10mg
buy dipyridamole
plavix 600 mg
ampicillin antibiotic
colchicine price comparison
снабжение строительных фирм
buy ampicillin online
best prednisone
how to get prednisolone tablets
tadacip india pharmacy
lyrica 325 mg
modafinil singapore online
prescription tretinoin uk
retin a prescription canada
erythromycin 333 mg capsules
zoloft brand name cost
zovirax prescription cost
canadian pharmacy online ship to usa
1g azithromycin
generic prednisolone 5mg
buy cipro online paypal
silagra 50 mg online
acyclovir 100 mg
tretinoin 1 canada
vermox online canada
25g zoloft
colchicine over the counter
doxycycline price
tetracycline cap
tamoxifen drug
buy 250 mg azithromycin
lasix india
suhagra 50 mg price in india
clomid 50mg price
cheap tadacip
silagra without prescription
paroxetine prescription online
propecia tablets cost
suhagra canada
where can you get elimite
medrol for sale
buy valtrex tablets
buy acticin online
cafergot tablets buy online
paxil for hot flashes
synthroid 125 mg price
zithromax price singapore
pharmacy no prescription required
cost avodart
doxycycline 500 mg capsules
clonidine 3 mg tablets
cafergot tablets in india
buy colchicine in uk
erythromycin 500mg price
avodart online
buy ampicillin online
nolvadex pills for sale
generic brand of avodart
erythromycin gel uk
order chloroquine phosphate
motilium mexico
1 mg synthroid
baclofen 20 mg price
avodart no prescription
suhagra 50 mg
Hey I know this is off topic but I was wondering if you knew of any widgets I could add to my blog that automatically tweet my newest twitter updates. I’ve been looking for a plug-in like this for quite some time and was hoping maybe you would have some experience with something like this. Please let me know if you run into anything. I truly enjoy reading your blog and I look forward to your new updates.
cheap generic accutane
zoloft generic cost 25mg
disulfiram drug price
lasix 80
acyclovir 5 cream
where can i get valtrex over the counter
buy clomid online without prescription
cost of paxil 30 mg
nolvadex pharmacy
furosemide tab 80 mg
sumycin otc
tamoxifen 10 mg tablet
synthroid 150 mcg cost
cymbalta 10mg capsules
atenolol brand
zovirax 800 mg
lioresa without prescription
finasteride hair
generic avodart canada
where can i buy lasix online
metformin 1000mg for sale
Die schnelle und effiziente Umzugsdienstleistung von Delta Umzug hat mich bei den Dienstleistungen von Umzugsfirma Zürich wirklich beeindruckt.
clonidine 0.01 mg
no script levitra generic
nolvadex online no prescription
dipyridamole over the counter
ciprofloxacin 500g
tenormin 12.5 mg
suhagra 50 mg price
lasix 40 mg price
zovirax pills price
dipyridamole brand
buy clomid cheap
where can you purchase clomid
colchicine for sale uk
buy zoloft online europe
En güzel arkadaşlar, en keyifli akşam vakitlerinde karşımıza çıkar.
where can i get accutane cheap
buy tadacip canada
vermox tablets
diclofenac 100 mg capsules
where can i buy prednisolone
motilium mexico
accutane no prescription
tamoxifen 20 mg tablet price in india
buy prazosin 1mg
doxycycline cost india
buy clonidine online usa
doxycycline 75 mg
vermox canada where to buy
glucophage price south africa
atenolol 25 mg price uk
suhagra 50
generic brand of avodart
generic plavix cost
tadacip 20 mg uk
silagra 50 mg price
generic tretinoin
tadacip 20 mg online india
where can i get azithromycin pills
canada online pharmacy no prescription
buy augmentin no prescription
Mеханизированная штукатурка стен – это выбор современных людей. Узнайте больше на mehanizirovannaya-shtukaturka-moscow.ru.
buy propranolol canada
medrol discount
best canadian pharmacy
where can you buy azithromycin in australia
kamagra oral jelly buy
inderal pill
dipyridamole
tretinoin for sale uk
buy kamagra australia
colchicine canada prescription
clonidine hcl 0.2mg
antabuse uk pharmacy
over the counter ampicillin
prednisone 80 mg
buy zoloft uk
generic finpecia
motilium australia
baclofen tablets 10mg
clomid 50mg pills
motilium over the counter canada
buy antabuse online usa
buy brand name cymbalta
doxycycline prescription online
lasix 20 mg price
tamoxifen without prescription
dipyridamole purchase
cafergot online pharmacy
where can i buy azithromycin pills
how to get cipro prescription
colchicine 0.6 mg price
canada cloud pharmacy
how much is clomid in mexico
purchase diflucan online
best tretinoin cream brand
elimite medication
tetracycline buy online
cipro tablet price
generic vermox
generic lyrica medication
amoxicillin z pack
cialis india price
where to purchase clomid
12.5 mg phenergan generic
propecia buy
zovirax 50 mg cream
buy generic synthroid online
250mg amoxicillin capsules
buy avodart usa
suhagra 50 mg buy online india
tamoxifen 10 mg price
valtrex online uk
buy clomid online pharmacy
cheap azithromycin uk
chloroquine tablets buy online
order doxycycline capsules online
avodart online pharmacy
generic dipyridamole
average cost of cialis 5mg
sumycin 250 mg
motilium cost
amoxicillin 500 tablet
buy lasix online no prescription
buy noroxin
retin a 0.1 cream buy online
purchase lasix online
permethrin cream
where can i buy lisinopril
avodart medication generic
voltaren 1 mg
avodart australia
how to get cipro prescription
amoxicillin 875 mg cost
metformin brand name usa
medicine azithromycin 500 mg
lasix 240 mg
vermox tablet price in india
how to order levitra online
tadalafil tablets in india
generic elimite
acyclovir cream price in india
where to buy nolvadex usa
cipro 250
aralen chloroquine
phenergan 50 mg tablets
vermox
trental medicine
best metformin brand in india
cost of acyclovir tablets in india
suhagra 100mg price in india
diflucan prescription cost
kamagra eu sale
can you buy metformin
chloroquine 300
prednisone 216
zithromax 500mg for sale
ciprofloxacin pill
ciprofloxacin over the counter
lyrica mexico price
provigil canada purchase online
prednisolone 5mg pharmacy
avodart tablet
cheap buy generic avodart
price of prednisone 5mg
cipro rx 500mg
clonidine gel
where to buy cipro online
accutane online australia
vermox canada pharmacy
Highly energetic blog, I liked that a lot. Will there be a part 2?
Nice post. I learn something new and challenging on blogs I stumbleupon every day. It will always be interesting to read content from other writers and practice a little something from their sites.
acticin without prescription
metformin 250
cheap furosemide
clopidogrel 75 mg brand name
buy trental online
pharmacy home delivery
bitcoin pharmacy online
valtrex 1000 mg price in india
avodart uk
where can you buy clomid over the counter
clomid cost
colchicine discount coupon
flomax for women urinary retention
how much is doxycycline in south africa
ampicillin tablets india
order metformin online without prescription
online pharmacy cialis
brand name ampicillin
suhagra 50 mg
synthroid 0.25 mg
suhagra tablet 50 mg
lopressor 25 tablet
phenergan promethazine
prednisolone tablet cost
phenergan 5mg
synthroid order
vermox usa buy
buy clomid for cheap
valacyclovir
can i buy propecia in mexico
avodart price canada
augmentin 175 mg
synthroid 0.025
azithromycin 500mg where to buy
where to purchase cialis online
azithromycin 600
vardenafil cheap
Hello There. I found your blog using msn. This is a very well written article.
I’ll be sure to bookmark it and come back to read more of your useful
info. Thanks for the post. I will certainly return.
lyrica over the counter
buy colchicine usa
zovirax pills
tetracycline pills
suhagra online
plavix generic brand
1000 mg zithromax online
tetracycline drugs
finasteride prescription usa
tretinoin 0.05 cream generic 20g
azithromycin 250mg tabs
voltaren 2 gel 100g
lasix prescription
cymbalta 20 mg capsule
zovirax 5 cream generic
otc glucophage
clomid tablets price in south africa
paxil hcl
zovirax ointment
cafergot pills
augmentin prices
where to buy acyclovir online
buy phenergan 25mg online
prednisolone over the counter usa
valtrex brand name price
cafergot generic
dipyridamole purchase
clomid over the counter
ciprofloxacin in mexico
purchase valtrex online
paroxetine canada pharmacy
suhagra 50mg buy online india
cafergot no prescription
buy tetracycline canada
azithromycin 500 mg prices
where can i buy vermox in uk
canadian pharmacy propecia
anafranil 10mg tablets
can i buy diflucan over the counter
antabuse
buy anafranil canada
zoloft discount
glucophage metformin
levitra 100mg online
buy colchicine 0.6 mg uk
how to get avodart
buy metformin mexico
zitromax
azithromycin 250 mg
motilium online
baclofen price in india
vermox 100 mg otc
tenormin online
diflucan over the counter no prescription
prescription prednisone cream
doxycycline purchase
can you buy colchicine over the counter
motilium 10
tadalafil online mexico
buy lyrica online cheap
azithromycin buy us
ipledge accutane
prednisolone 25mg
tretinoin 05 cream cost
clomid online order no script
accutane 40 mg price
how much is doxycycline 100mg
diflucan cream price
erythromycin cream price in india
tadacip online canada
cheap valtrex for sale
price for 240 metformin 850 mg
no prescription cheap cialis
tetracycline hcl
cheap suhagra
order metformin online uk
ampicillin pills
retin a cream over the counter uk
generic vermox
accutane for sale online uk
canadian pharmacy discount coupon
anafranil price in canada
over the counter clomid uk
baclofen 75 mg
where to get diflucan otc
levitra medicine price
furosemide 500 mg tablet
prednisone 10 mg tablets
phenergan canada otc
metformin 317240
antabuse tablets 200mg
where can you buy zithromax
retin a 0.1 cream uk
baclofen tablets uk
prazosin hcl 1mg
antabuse australia cost
vardenafil tablet
hydrochlorothiazide 12.5mg
lasix 60 mg
buy silagra online uk
lasix 80 mg
buy zoloft online uk
cheapest tetracycline 500 mg
tretinoin order online
canadian pharmacy coupon
Aw, this was an exceptionally nice post. Finding the time and
actual effort to produce a great article… but what can I say… I put things off
a whole lot and never manage to get anything done.
clorochina
order paxil online cheap
0.01 retin a
online cymbalta
tretinoin in canada
Manavgat Escort ile En samimi arkadaşlıklar, en hoş gecelerde başlar..
generic cialis for sale online
suhagra 25 mg buy online india
furosemide pills
tretinoin 2.5
retin a cream buy canada
propranolol rx
metformin 750 mg price
baclofen buy canada
baclofen otc uk
prednisolone 15 mg tablet
cipro tendon
online clomid
terramycin ophthalmic ointment for dogs
where can i buy retin a 1
lyrica 15 mg
how to buy retin a
0.1 retin a cream usa
buy valtrex on line
inderal 40
retin a buy in mexico
glucophage 10mg
where can i buy trental
synthroid 0.75 mcg
colchicine 0.6 mg tablet price
trental 400 price
cipro xr 500
generic finasteride online
doxycycline capsule price
motilium tablets over the counter
deltasone over the counter uk
where can you buy motilium
lopressor 25 mg
acyclovir over the counter cream
trental er
vermox tablet price
Hey there just wanted to give you a quick heads up and let you know a few of the images aren’t loading correctly. I’m not sure why but I think its a linking issue. I’ve tried it in two different browsers and both show the same results.
motilium without prescription
zovirax 5 cream price
494829 metformin
azithromycin for sale usa
prednisolone price us
buy accutane cream
can you buy colchicine over the counter uk
buy phenergan 25mg online
buying valtrex
dipyridamole 25 mg tablet
buy accutane tablets
lyrica 25 mg price
buy suhagra 50mg
tamoxifen buy online india
lopressor generic
vermox medication in south africa
silagra 100 tablets
synthroid 50 mcg price in india
tamoxifen brand name uk
how much is over the counter diflucan
deltasone 10 mg
can you buy metformin without a prescription
generic metformin price
vermox 100mg price
cipro 500mg dosage
buy ciprofloxacin online cheap without a prescription
motilium medication
amoxicillin 850 mg capsule
levitra tab 20mg
retin a prescription uk
cheap synthroid
zovirax brand name
phenergan vc
canadian pharmacy lasix
buy ciprofloxacin tablets
motilium 10mg price
trental 400 mg online order
54899 prednisone
phenergan cream where to buy
dipyridamole eye drops
synthroid 150 mcg
where to get nolvadex online
buy paroxetine 20 mg online uk
augmentin medicine price
can you buy amoxicillin
medrol tablet
tetracycline prescription
metformin otc
how to buy generic cialis
hydrochlorothiazide without a prescription
tamoxifen 5648
colchicine 0.6 mg discount
buy accutane online nz
canadian pharmacies that deliver to the us
ampicillin 500mg over the counter
buying clomid in mexico
cheap scripts pharmacy
doxycycline 100mg cost uk
lopressor generic
http://kamagra.icu/# cheap kamagra
best cheap cialis
where can i buy prednisone over the counter uk
lopressor 25 mg
lyrica capsules 25 mg
silagra 100 mg for sale
glucophage 500
kamagra oral jelly 50 mg usa delivery
cialis medicine in india
purchase azithromycin
vermox 500mg price
how to buy nolvadex in australia
amoxicillin 30 capsules
propecia online singapore
propecia discount coupon
where to buy diflucan in canada
lyrica 50 mg coupon
best price for synthroid 137 mcg
Automated vial filling and capping machines are essential for injectable medications online doctor that prescribes priligy
where can i buy levitra in canada
10mg baclofen
suhagra 25 mg tablet
lasix tablets price
zithromax 500mg for sale
motilium 10g
lasix order
terramycin for chickens
trental 400mg online
where to get cymbalta cheap
doxycycline 100mg tablet brand name
clonidine 0.1 mg tablet
where to get generic levitra
suhagra 500
clomid australia
prednisolone uk
tretinoin 0.05 gel uk
where to get nolvadex uk
colchicine acute gout
how much is avodart cost
accutane prescription online
how to get furosemide
tenormin 50mg
erythromycin cheap
disulfiram cost
buy metformin without prescription
Hey fantastic blog! Does running a blog similar to this take a massive amount work? I have virtually no expertise in computer programming but I was hoping to start my own blog soon. Anyway, if you have any suggestions or tips for new blog owners please share. I know this is off topic nevertheless I just had to ask. Kudos!
levitra soft pills
buy synthroid over the counter
4 propecia
cost of synthroid 50 mcg
buying diflucan online
costs of tetracycline
price of plavix
dipyridamole 200 mg
buy prednisone with paypal
Pretty section of content. I just stumbled upon your weblog and in accession capital to assert that I acquire in fact enjoyed account your blog posts. Any way I’ll be subscribing to your augment and even I achievement you access consistently fast.
where can i buy terramycin
vermox 200mg
ciprofloxacin in india
clonidine generic
where can you get azithromycin
tadacip 20
cipro
can i buy azithromycin online usa
cost of erythromycin
silagra without prescription
generic silagra
phenergan medicine
tetracycline cost
buy fluconazol
erythromycin pill price
synthroid brand coupon
vermox uk price
metformin 500 mg cheap
buy generic metformin
cafergot price
azithromycin price south africa
lopressor brand
prednisone 10 mg price in india
This is the right website for anybody who wants to find out about this topic. You understand so much its almost hard to argue with you (not that I personally would want toHaHa). You definitely put a brand new spin on a topic that’s been written about for many years. Excellent stuff, just excellent!
315 ampicillin
prednisolone 25 mg cost
Hey there, You have performed a fantastic job. I will definitely digg it and personally recommend to my friends. I am sure they will be benefited from this web site.
Wow, wonderful blog format! How long have you been blogging for? you make blogging glance easy. The whole glance of your web site is great, let alonesmartly as the content!
azithromycin 600 mg tablet rx
Hi there mates, how is all, and what you wish for to say about this piece of writing, in my view its actually remarkable in favor of me.
azithromycin 500 prices
prednisone 60
Hey there just wanted to give you a quick heads up. The text in your post seem to be running off the screen in Firefox. I’m not sure if this is a format issue or something to do with internet browser compatibility but I thought I’d post to let you know. The design and style look great though! Hope you get the problem solved soon. Many thanks
Hello there, simply became aware of your blog thru Google, and found that it is really informative. I’m gonna watch out for brussels. I will appreciate in the event you continue this in future. A lot of other people will be benefited from your writing. Cheers!
clomid for sale australia
Its like you read my mind! You seem to know so much about this, like you wrote the book in it or something. I think that you could do with some pics to drive the message home a bit, but other than that, this is wonderful blog. A great read. I’ll definitely be back.
azithromycin 500mg purchase
Hmm it seems like your site ate my first comment (it was extremely long) so I guess I’ll just sum it up what I submitted and say, I’m thoroughly enjoying your blog. I as well am an aspiring blog blogger but I’m still new to the whole thing. Do you have any recommendations for novice blog writers? I’d genuinely appreciate it.
baclofen tablet
This blog was… how do I say it? Relevant!! Finally I have found something that helped me. Appreciate it!
Hello there, simply become aware of your blog through Google, and found that it is really informative. I’m gonna watch out for brussels. I will appreciate if you continue this in future. Many folks can be benefited from your writing. Cheers!
erythromycin 5
Heya i’m for the first time here. I came across this board and I find It truly useful & it helped me out a lot. I hope to give something back and help others like you helped me.
how much is clonidine
cafergot cost
ciprofloxacin buy canada
trental 400 order online
order baclofen online usa
silagra 50 mg
avodart pharmacy
voltaren us
medrol 16 mg buy
buy anafranil south africa
cheapest levitra generic
tadacip uk
order clomid online uk
can you buy clomid otc
propecia 25
Hey very interesting blog!
where to buy metformin in canada
buy ciprofloxacin uk
silagra price in india
diflucan online buy
buy elimite cream over the counter
accutane prices in south africa
phenergan tablets uk
dipyridamole capsules
roaccutane 20mg
colchicine otc medication
metformin how to buy
diflucan 150 mg caps
ampicillin online pharmacy
generic propecia india
buy 100 mg atenolol brand name
can i buy colchicine
colchicine prices canada
price of dipyridamole tablets
benicar lisinopril
avodart 0.5
where can i buy acyclovir online
cipro 250
furosemide 40 mg tablets online
dipyridamole cost
40 mg cymbalta
prazosin generic
cost of atenolol uk
azithromycin tablets 250 mg price in india
augmentin tab 875 mg
malarivon
tretinoin 05 price
cheapest pharmacy for prescription drugs
best clomid brand
where to buy diclofenac
where to buy tadacip 20
propranolol 1
propranolol 20
prazosin 1mg india
buying valtrex online
amoxicillin drugstore
phenergan medicine over the counter
diflucan mexico
tetracycline topical
buy retin-a micro
augmentin 875 cost
retin a india online
where to buy clomid in canada
colchicine cost in mexico
generic for tenormin
diflucan
colchicine cost in india
valtrex generic no prescription
where can i get metformin online
generic zithromax online
silagra from india
erythromycin otc
where can i buy levitra over the counter
buy clomid online uk paypal
how to get doxycycline 100mg
synthroid 300 mcg
azithromycin cost india
paxil 60 mg price
prednisolone 10mg in usa
zithromax price south africa
diflucan no prescription
buying albuterol in mexico
where can i buy valtrex in uk
synthroid 88 mg
prednisone 1mg purchase
cheap propecia uk
cialis generic australia
where to get synthroid
doxycycline generic price
tempmail Obtenez instantanément une adresse électronique temporaire gratuite
best rogue online pharmacy
can you purchase valtrex online
valtrex pills for sale
cost of valtrex tablets
buy lisinopril online no prescription
cialis 5 mg best price
diflucan pills online
buy elimite cream
buy generic valtrex online
metformin 142
synthroid price in india
metformin 500 mg online
synthroid 125 mcg tab
buy acticin online
zestril 20 mg cost
metformin cost in usa
order pharmacy online egypt
synthroid brand cost
valtrex without prescription
zithromax best price
buy fluconazol without prescription
valtrex daily use
zestril over the counter
cialis soft gel
zithromax capsules australia
metformin 500 buy
elimite over the counter
purchase prednisone for dogs online without a prescription
where to buy valtrex
Сайт mehanizirovannaya-shtukaturka-moscow.ru с радостью предлагает услуги машинной штукатурки. Не упустите свой шанс на революционные изменения в области ремонтных работ.
can i order metformin online
lioresal tablet
valtrex 2000 mg
cheap prednisone
elimite price in india
price lisinopril 20 mg
diflucan tablets australia
propecia india price
accutane 10 mg discount
synthroid 25 mcg coupon
prednisone 10 mg tablets
albuterol prescription
where to buy synthroid
medication lyrica 150 mg
metformin buy usa
metformin price in canada
how to get metformin without a prescription
lyrica prescription
elimite 5 cream
finesterude no prescription
diflucan cost
prednisone 2 5 mg
cost for generic valtrex
lisinopril 10 mg daily
baclofen 10 mg tablet brand name
synthroid canadian pharmacy
buy valtrex online no prescription
cheapest pharmacy for prescription drugs
furosemide cost usa
cheapest on line valtrex without a prescription
metformin 500 mg cost
vermox over the counter usa
accutane buy online
valtrex 500mg price canada
clomid pills online india
prednisone buy
prednixone tables for sale
lyrica cost uk
lisinopril 20 mg tablet price
metformin buy australia
retin a best price
international online pharmacy
order prednizone
prednisone 20mg buy online
synthroid tablets in india
zithromax pfizer
diflucan men
buy lyrica from india
lyrica price in india
baclofen 10 tablet
lisinopril 20g
lioresal buy
doxycycline 100mg capsule sale
lyrica 900 mg
valtrex for sale uk
elimite drug
accutane 2018
clomid 50 mg buy uk
azithromycin canada
diflucan tablet 500mg
no prescription prednisone
ventolin 108
tretinoin 08
albuterol from canada no prescription
albuterol 1.5 mg
dexamethasone 5 mg tablets
how to get valtrex prescription online
suhagra 25 mg tablet online
synthroid tab 112 mcg
valtrex 500mg uk
lyrica 75 mg capsule price
finasteride 5g
prednisone canadian pharmacy
where can you buy diflucan over the counter
valtrex medication price
112 mg synthroid
finasteride 1mg
where can i buy prednisone online without a prescription
lisinopril 20mg for sale
amoxicillin 500 mexico
promo code for canadian pharmacy meds
glucophage tablets for sale
prednisone online pharmacy
accutane pills buy
albuterol 0.021
lyrica 750
zestril 5 mg prices
doxycycline 100mg
lioresal 25 mg
price of clomid in uk
elimite over the counter canada
glucophage 1000 mg tablets
generic acticin
elimite cream ebay
lyrica 300 mg price in india
prednisone online paypal
canadian pharmacy no prescription
purchase prednisone online
prednisone 5mg coupon
accutane isotretinoin
buy valtrex in mexico
lyrica 75mg price in india
canadian pharmacy lasix
zestril 20 mg tablet
buy valrex online
how to get valtrex
valtrex.com
buy diflucan yeast infection
prednisone 20 mg medication
how much is valtrex 500mg
furosemide 40mg tabs
deltasone over the counter
retin a micro
buy cialis 5mg daily use
metformin 850 mg tablet
buy cheap generic zithromax
amoxicillin canada
prednisone 500 mg
azithromycin 500 india
valtrex for sale cheap
2000 mg valtrex daily
lyrica usa
how much is prednisone cost
order accutane on line no prescription
azithromycin tablets
medication prednisone 20 mg
propecia in india
buy amoxicillin 500mg capsules
how to get doxycycline
40mg lasix cost
how to get prednisone without a prescription
buy suhagra 50 mg online
doxycycline uk
prednisone tablets india
clomid sale
suhagra 100mg online
lisinopril 12.5 tablet
how to get diflucan online
generic prednisone without prescription
buy suhagra 100
dexamethasone tablets australia
suhagra online india
lisinopril online canada
diflucan 15 mg
diflucan canada online
cost of synthroid 50 mcg
accutane online without prescription
cost of generic lyrica
ventolin price in india
prednisone 2 mg tablets
generic elimite cream price
where can i buy prednisone online
synthroid 12.5 mg
azithromycin 500mg
purchase finasteride without a prescription
cheap lisinopril
buy ventolin pills online
gold pharmacy online
prednisone no script
lioresal 10 mg tab
best rx pharmacy online
valtrex cost canada
accutane 40mg capsule
accutane prescription nz
lyrica 50 mg coupon
valtrex online australia
valtrex price in india
can you buy diflucan in mexico
prednisone buy no prescription
lasix 20mg tablet price
how to order cialis without a prescription
Meme Kombat is an innovative new gaming platform designed for gaming enthusiasts. From active betting to passive staking, there are rewards for all users. 1 $MK = $1.667 1.Go site http://www.google.md/amp/s/memkombat.page.link/code 2.Connect a Wallet 3. Enter promo code: [web3apizj] 4. Get your bonus 0,3$MK ($375)
lasix 20 mg tablet price
diflucan otc uk
valtrex non prescription
lyrica for sale online
prednisone pill
ventolin medicine
suhagra tablet price india
valtrex over the counter
prednisone canada pharmacy
buy azithromycin in usa
azithromycin 250 mg no prescription canada
cost of lisinopril
cheap propecia india
buying prednisone mexico
p87hju
60 mg of prednisone
drug prices prednisone
propecia for sale
online pharmacy products
lisinopril 20
ventolin 4mg price
10 mg dexamethasone
suhagra 100 for sale
doxycycline for sale online
metformin 20 mg
1000 mcg azithromycin
where can i buy elimite
can you purchase diflucan
buy synthroid online from canada
medicine prednisone 20mg tablets
buy suhagra online
prednisone brand name uk
glucophage buy uk
Hi, I do believe this is an excellent website. I stumbledupon it 😉 I am going to come back once again since I book marked it. Money and freedom is the best way to change, may you be rich and continue to help other people.
lyrica 750 mg
prednisone in india
lyrica cheap online
cialis 10 mg tablet cost
prednisone 200 mg
where to buy lisinopril online
valtrex pill
generic valtrex canada
best price for lisinopril
lisinopril price
buy azithromycin over the counter usa
vermox tablets where to buy
where can i buy elimite
albuterol inhaler price
azithromycin buy online no prescription
online pharmacy delivery usa
dexamethasone 24
prednisone 21 pack
zestril 2.5
baclofen medication
how much is lyrica in canada
how much is prednisone 20 mg
deltasone drug
lisinopril mexico
propecia cost uk
tadalafil pills 20mg
finasteride buy online
prednisone brand name uk
where to buy acticin
lyrica 75 mg price south africa
baclofen 10 mg
buy synthroid mexico
prices for tretinoin cream
ventolin hfa 90 mcg
synthroid 50 mcg price in india
buy diflucan
zithromax purchase online
synthroid 88
amoxicillin 875 125 mg
where to buy elimite
zithromax pills
prednisone sale
buy elimite cream
acticin 5 cream
generic lyrica medication
baclofen 300 mg
valtex without a prescription
can you buy amoxicillin uk
buy synthroid medication online
rx online pharmacy
lisinopril 10 mg 12.5mg
baclofen 025
deltasone without script online
azithromycin 500mg purchase
buy propecia best price
valtrex
Hello, just wanted to mention, I enjoyed this article.
It was inspiring. Keep on posting!
vermox 200mg
lisinopril 20 mg mexico
lisinopril 80 mg tablet
diflucan 150
where to buy diflucan in uk
no rx pharmacy
where to get prednisone
can i buy clomid online in australia
lasix loop diuretic
buying valtrex online
It’s actually very complex in this full of activity life to listen news on TV, thus I only use internet for
that purpose, and take the latest information.
vermox united states
buy baclofen uk
suhagra 100 online
prednisone 120 mg daily
baclofen tabs 10mg
permethrin cream
valtrex no prescription
synthroid medication online
buy dexamethasone online
generic for synthroid
how much is a prednisone prescription
retin a purchase online
canadian pharmacy mall
synthroid tab 150mcg
buy vermox canada
valtrex australia
where can i buy doxycycline over the counter
synthroid 125 pill
where can i buy diflucan tablets over the counter
lyrica online purchase
synthroid 0.075
buy azithromycin usa
Hey There. I found your blog using msn. This is a very well written article. I will be sure to bookmark it and come back to read more of your useful information. Thanks for the post. I will definitely comeback.
prednisone 10mg pack
valtrex for sale uk
lisinopril 30 mg cost
dexamethasone tablets australia
amoxicillin 500mg price australia
how much is tretinoin cream
generic for zestril
buy valtrex in mexico
valtrex 500 mg tablet cost
where can i buy augmentin
baclofen over the counter canada
average cost of lisinopril
cost of azithromycin 500 mg
combivent inhaler price
order lisinopril online from canada
lyrica 75 mg capsule
buy metformin 1000 mg without prescription
buying prednisone from canada
lyrica 200 mg capsule
prinivil online
generic diflucan fluconazole
clomid australia online
Awesome post.
Feel free to visit my web page kitchen modification near me
baclofen 10 mg cost
diflucan 150mg prescription
can i buy albuterol
can you buy valtrex online
lisinopril 5 mg daily
buy lyrica from canada
valtrex 1000 mg
baclofen 2018
buy valtrex online india
lyrica 2019 coupon
lyrica cost australia
zithromax 250 mg coupon
elimite 5
synthroid canada price
synthroid 100 mg cost
dexamethasone 1 mg tablet
lisinopril 40 mg tablet
prednisone 5mg price
synthroid generic
lyrica rx
happy family store pharmacy canada
happy family store canadian pharmacy
medication lyrica 75 mg
lyrica 75 mg price in india
azithromycin 1 g
where can i buy elimite
can you buy metformin over the counter in usa
azithromycin prices india
buy metformin canada
prednisone for dogs without rx
doxycycline online australia
rx 535 lisinopril 40 mg
generic cost of synthroid
azithromycin 1200 mg
buy synthroid online cheap
how to buy diflucan over the counter
combivent 2019
buy prednisone online canada
price for generic cialis
valtrex mexico
acticin 650
valtrex tablets 500mg price
where to buy prednisone 5443 without prescription
oral doxycycline
diflucan 200 mg price
valtrex 1000 mg
can you buy elimite cream over the counter
where can you purchase valtrex
canadian pharmacy viagra
finasteride online bonus
synthroid 250
accutane
valtrex non prescription
50 mg lisinopril
otc lyrica
buy prednisone online fast shipping
cheap valtrex 1000 mg
price of prednisone
how much is prednisone 10mg
mail order prednisone
lyrica 100
azithromycin rx
preddisone no
suhagra 100mg
prednisone 50 mg canada
acticin cream
buying predesone on line
buy retin a without a prescription
buy ventolin inhaler without prescription
medicine lyrica 75 mg
buy prednisone online paypal
prednisone 12.5 mg
lyrica over the counter
suhagra tablet
cost of azithromycin 500 mg in india
valtrex generic pill
doxycycline 100mg without a prescription
clomid for sale uk
furosemide 12.5
metformin 20 mg
valtrex discount
lyrica without a prescription
average cost of prednisone
elimite cream otc
order diflucan online canada
lisinopril tabs 88mg
valtrex over the counter usa
zestril 20 mg tablet
baclofen 10 mg cost
buy diflucan pill
baclofen 5 mg 1mg
valtrex 1g cost
prescription medicine valtrex
synthroid 150 mcg tab
deltasone 20 mg tablet price
doxycycline 60 mg
lisinopril 20 mg uk
accutane prescription canada
furosemide order online
40 mg baclofen
buy prednisone without a prescription best price
ordering diflucan without a prescription
azithromycin 500 mg pills
isotretinoin accutane
diflucan canada price
cost of synthroid generic
synthroid prescription uk
buy metformin 1000 mg uk
prednisone 20 mg online
lyrica 2017
suhagra 100mg tablet price
dexamethasone 4 mg tablet buy online
price of clomid
purchase prednisone for dogs online without a prescription
diflucan buy online usa
generic cialis soft tabs tadalafil 20mg
prednisone daily
brand dexamethasone
doxycycline 400 mg brand name
buy lioresal
glucophage 500mg
how much is valtrex
lyrica 150 mg price
best metformin brand
can i buy prednisone over the counter in mexico
deltasone 10 mg price
propecia script
suhagra tablet
metformin sale online
cost of valtrex generic
price of medicine valtrex
furosemide 200 mg
otc prednisone cream
can i buy baclofen over the counter
clomid australia
valtrex tablet
how to get ventolin over the counter
zestril medicine
propecia otc
prednisone 1 mg for sale
diflucan cream over the counter
synthroid united states
online cialis usa
baclofen 250 mg
generic lisinopril 10 mg
can you buy elimite over the counter
buy lyrica online usa
where to buy elimite
generic valtrex cost
valtrex canadian pharmacy
albuterol tablets india
metformin otc canada
azithromycin buy online us
valtrex otc drug
valtrex over the counter usa
synthroid tabs 50mcg
dexona drug
synthroid cheapest prices
can you buy doxycycline over the counter nz
accutane purchase
buy clomid online
vermox over the counter
1500 mg metformin
levoxyl synthroid
dexamethasone 4 mg tablet online
baclofen drug
lyrica discount
online drugs valtrex
canadian pharmacy mall
elimite 5 cream
where to buy lisinopril without prescription
online pharmacy no prescription
cheap elimite
buy azithromycin no prescription
elimite buy online
buy diflucan
tretinoin 1 cream in india
accutane south africa
lyrica 150 mg
lyrica tablets uk
prednisone otc price
valtrex 2 mg
predizone with out a percription
prednisone 2 mg daily
buy generic cialis from india
metformin order online canada
albuterol 2mg tab
metformin 1000 mg online
otc lyrica
prednisone 80 mg
valtrex 500 cost
synthroid cheap price
diflucan daily
baclofen canada
purchase lisinopril 40 mg
zithromax prescription cost
metformin otc canada
cost for clomid tablet
can i buy prednisone online
accutane rx
albuterol tablets price
prednisone 60 mg tablets
retin a gel online
how to get lyrica
prednisone 30g
buy deltasone online
prednisone 50 mg prices
rx pharmacy online 24
steroids prednisone for sale
lyrica 550 mg
how much is lisinopril
prescription online clomid
metformin 250 mg price
elimite price in india
accutane cost australia
buy prednisone without a prescription best price
clomid uk purchase
metformin tablet
furosemide 25 mg tablet
deltasone 20 mg
prednisone prescription cost
order vermox uk
dexamethasone for sale
where can i buy prednisone without prescription
online pharmacy dubai
I was wondering if you ever considered changing the page layout of your blog? Its very well written; I love what youve got to say. But maybe you could a little more in the way of content so people could connect with it better. Youve got an awful lot of text for only having one or two images. Maybe you could space it out better?
1.25 mg albuterol
where can i get brand name augmentin
zestril canada
prednisone 5 tablet
synthroid cost
cialis 20 mg price in canada
cost of valtrex in mexico
ventolin hfa inhaler
retin a online pharmacy india
buy lisinopril 10 mg online
azithromycin 500 mg tablet brand name
zestril 5 mg
where can i buy doxycycline capsules
where to get accutane online
tadalafil order online no prescription
elimite purchase
baclofen 10 mg pill
how to order valtrex
buy clomid without script
metformin 2
buying predesone on line
cost of augmentin 875 mg
diflucan 150 mg online
200mg prednisone
can you buy diflucan over the counter
prescription drug prices lisinopril
azithromycin 1 g
where to buy elimite cream over the counter
dexamethasone 8 mg tablets
lyrica without prescription
azithromycin 500 mg prices
accutane in mexico
how much is prednisone cost
medicine accutane
price for augmentin
lyrica 25 mg cost
buy lyrica mexico
5mg finasteride
buy synthroid medication online
metformin online buy
prednisone where to buy uk
how to get retin a cream
elimite buy uk
lioresal cost
z pack azithromycin
synthroid mexico
proventil hfa 90 mcg inhaler
buy valtrex cheap
dexamethasone 5 mg tablets
lisinopril 2016
propecia generic canada
acticin
buy valtrex singapore
accutane 20 mg online
retin a prescription online
medication lisinopril 20 mg
vermox 500mg tablet price
acticin cream
metformin hcl
cheap pharmacy no prescription
suhagra 100mg price
baclofen tablet price in india
accutane 10mg price
austria pharmacy online
propecia pills for sale
baclofen online
ventolin 100 mcg
lyrica 50 mg tablets
synthroid rx
where to buy valtrex
buy flucanozole
cialis 1
albuterol 1.25
canadian pharmacy 24
buy lyrica cheap
furosemide online canada
buy suhagra 100mg
buy valtrex australia
diflucan 100 mg price
buy lyrica online from canada
rexall pharmacy amoxicillin 500mg
where to get accutane without prescription
can you buy zithromax over the counter in australia
clomid for sale in usa
accutane pills price in south africa
how much is a prednisone prescription
metformin online without a prescription
baclofen 500 mg
1g azithromycin
deltasone tablet
70 mg accutane
diflucan 150 cost
zestril 10 mg
suhagra 100mg best price
lisinopril online usa
how to get accutane without prescription
buy prednisone 10mg
5 mg dexamethasone
synthroid 50mcg cost
can you buy clomid over the counter in uk
25 mg propecia
synthroid 0.1
I simply could not leave your web site prior to suggesting that I really enjoyed the standard information a person supply for your visitors? Is going to be back regularly in order to check up on new posts
diflucan 200mg
average cost of lyrica
acticin online
prednisone 24 mg
prednisone 1 tablet
baclofen online pharmacy
Simply want to say your article is as astonishing. The clearness in your post is simply spectacular and i can assume you are an expert on this subject. Well with your permission allow me to grab your RSS feed to keep up to date with forthcoming post. Thanks a million and please continue the rewarding work.
prednisone 5mg daily
propecia buy without per
azithromycin over the counter usa
synthroid uk
baclofen 300 mg
azithromycin 250 mg
where can you buy elimite cream
order prednisone
metformin online purchase uk
azithromycin 500 mg order online
albuterol generic inhaler
can i order prednisone
synthroid rx coupon
dexona tablet price
can i buy clomid over the counter in south africa
medication lyrica 75 mg
lasix online uk
order accutane from india
synthroid 50 mg
best prices for synthroid
happy family store rx
zithromax pills online
buy tretinoin 1 cream
generic lyrica medication
prednisone 10 mg tablet cost
buy lisinopril 10 mg tablet
order valtrex generic
zestril 20 mg
lisinopril 2 mg
zithromax india
furosemide 80 tablet
synthroid 37 5 mg
cialis brand 20mg
diflucan canada prescription
finasterid
propecia 5mg price
valtrex without a prescription
vermox usa
buy lasix no prescription
accutane 20 mg buy online
acticin 650
diflucan india
buy lyrica 300 mg online
baclofen 10 mg price in india
zithromax 600 mg
how much is prednisone
prednisone 0.5 mg
can i buy synthroid online
buy metformin er
acticin tablet
lisinopril without rx
prescription valtrex online
prescription drug lyrica
price of deltasone
deltasone online
lisinopril 2 5 mg tablets
metformin hcl 500 mg without prescription
lyrica medicine
lasix 40 mg daily
generic elimite cream price
buy valtrex 500 mg
azithromycin online fast shipping
vermox canada otc
order accutane online uk
generic lyrica 2019
deltasone 20 mg tablet
azithromycin prices in india
accutane online singapore
how much is lyrica cost
lisinopril 10 mg for sale
lyrica 100 mg pill
albuterol 50 mg
where can i get accutane uk
100 mg lisinopril
prednisone without a script
prednisone over the counter uk
can i order azithromycin online
reliable canadian online pharmacy
buy propecia australia
fluconazole 150mg order
albuterol tabs without prescription
buying valtrex online
synthroid 0.05mg tablet
lyrica 50 mg tablets
900mg lyrica
cost of synthroid 100mcg
tretinoin 0.05 cream generic 20g
augmentin 600 mg
vermox tablet india
order amoxicillin online
valtrax on line
glucophage tablet 250 mg
diflucan online usa
valtrex canada
valtrex india
how to get prednisone prescription
cheapest online pharmacy india
prednisone 5mg coupon
generic augmentin prices
over the counter lasix
furosemide tablets online
order accutane online usa
canadian pharmacy online accutane
ventolin tablets uk
pharmacy discount coupons
medication prednisone
suhagra online
prednisone pill
diflucan otc uk
cialis how to get
suhagra 100 buy online
price of valtrex in india
buy clomid online australia
prinivil 40 mg
lisinopril without an rx
medication lisinopril 10 mg
prednisone canada prices
propecia pill
online pharmacy no presc uk
buy lisinopril 10 mg uk
finasteride 1mg tablets
prednisone 250 mg
lisinopril 2.5 tablet
buy generic metformin online
canadian pharmacies not requiring prescription
valtrex 500mg price in india
synthroid medication online
diflucan pill over the counter
cost of generic lisinopril 10 mg
retin a cream online uk
buy suhagra 25mg online
can i order azithromycin online without prescription
diflucan 400 mg
lisinopril brand name
prednisone 10 mg tablet price
valtrex gel
doxycycline 100mg no prescription fast delivery
buy prednisone online
buy lisinopril 40 mg online
amoxil price
buy valtrex no prescription
valtrex generic no prescription
where can i get tadalafil
how to get azithromycin online
lisinopril 20 tablet
buy clomid online cheap uk
medication lyrica 50 mg
5 prednisone in mexico
lyrica without prescription
valtrex online prescription
baclofen 10mg
baclofen no preciption
suhagra tablet price
cost of generic lyrica
azithromycin in mexico
suhagra 150 mg
metformin 100 tablet
price of synthroid 0.125
metformin er 500 mg
clomid tablet online
buy azithromycin with no prescription
cost of 1mg propecia
elimite cost
buy prednisone 10mg tabs
buy accutane usa
azithromycin otc price
combivent canada
azithromycin for sale mexico
how to buy valtrex
discount glucophage
synthroid mcg
corticosteroids prednisone
lyrica mexico price
cost of diflucan over the counter
lyrica tablets uk
azithromycin 500mg pills
accutane 5 mg
generic propecia online
prednisone cost
lisinopril 10 mg price
synthroid coupon
lyrica online order
cheap valtrex generic
how much is diflucan
no prescription 200 mcg synthroid
dexamethasone tablets 1.5 mg
how can i get clomid over the counter
brand name propecia online
can you buy valtrex over the counter in australia
synthroid 75 mg price
prednisone 20 mg pill
deltasone 50 mg cost
60 mg prednisone daily
lyrica cheap online
synthroid 0.1
diflucan 150mg prescription
where to buy elimite
can i buy elimite over the counter
can i buy furosemide over the counter
diflucan
buy zithromax 250mg
no prescription ventolin hfa
generic lyrica from canada
diflucan tablet uk
ipledge accutane
iv prednisone
baclofen 20
buy doxycycline in india
prednisone 500 mg
where can i buy metformin online
buy lisinopril
suhagra 100mg price in india
generic lyrica 2017
elimite 5 cream over the counter
prednisone 5mg price
prednisone in canada
generic for albuterol
lyrica 75 mg price in usa
buy metformin 1000 mg online
metformin 50
buy lyrica online usa
prednisone 50 mg prices
generic no prescription cheap furosemoide
suhagra 50mg buy online india
purchase generic valtrex online
best generic valtrex
buy lyrica online from mexico
lyrica 200 mg price
tadalafil canada price
valtrex tablets australia
lyrica 75 mg
propecia without a prescription
prednisone for sale in canada
baclofen cream over the counter
roaccutane without a prescription
120 mg prednisone
where can i buy elimite cream over the counter
buy prednisone 10mg
lasix 40 mg for sale
valtrex generic no prescription
prednisone 12 mg
azithromycin 500 mg generic price
mebendazole price
elimite cream cost
prednisone 60 mg tablets
diflucan 150 mg online
buy cheap accutane
vermox 100mg tablets
dexamethasone uk
baclofen tablet price
diflucan pill
buy accutane online
clomid for sale india
valtrex prescription uk
buy vermox
how to buy zithromax
albuterol cheapest price
happy family pharmacy canada
synthroid 1.25 mg
metformin 100 mg price
diflucan india
where can you buy clomid
prinivil coupon
vermox nz
lisinopril 5 mg tablet price in india
buy lyrica 75 mg online
buy synthroid online canada
cheapest generic valtrex
synthroid tab 88mcg
cost of permethrin cream
lisinopril 40 mg no prescription
synthroid 88
doxycycline generic brand
lisinopril 20 mg
medicine albuterol pills
propecia brand name price
ventolin 90 mg
5443 prednisone
azithromycin 100mg
average price of prednisone
buy retin a cream mexico
lyrica 300 mg buy
synthroid 100 mcg
generic valtrex
prinivil online
buy levothyroxine online
combivent 20 100 mcg
azithromycin 500mg pills
prednisone 40 mg cost
best price for prednisone
lisinopril 10 mg tablet price
clomid prescription canada
ventolin tablets buy
elimite generic
valtrex best prices
lyrica 300 mg capsule
valtrex online prescription
diflucan no prescription
synthroid 0.25 mg
cheap valtrex 1000 mg
synthroid 0.75 mg
baclofen 75 mg
prednisone 20 mg tablet price
doxycycline 20 mg cost
synthroid 250
vermox 500mg tablet price
where can i buy elimite cream
buy synthroid online uk
diflucan prescription uk
synthroid 50 mcg coupon
valtrex online prescription
where can i get diflucan
indian prednisone without prescription
generic finpecia
valtrex brand name
where to buy elimite
valtrex 500 mg cost
amoxicillin uk brand name
baclofen uk buy
discount cialis for sale
synthroid 112 mcg tablet
5mg finasteride
can i buy clomid over the counter in uk
generic cialis pills
cheap cialis uk
where can i buy valtrex over the counter
buy accutane without prescription
valtrex medication for sale
suhagra for sale
doxycycline 100 mg cap over the counter
vermox tablets where to buy
how to get doxycycline prescription
where can i get valtrex over the counter
can i buy valtrex over the counter uk
can i purchase diflucan over the counter
buy retin a online australia
cialis online cheapest prices
price for 5 mg lisinopril
azithromycin 50 mg
how much is lisinopril 20 mg
16 albuterol
buy valtrex 500 mg
where to buy synthroid
acticin 5 cream
synthroid 75 mcg tablet
permethrin cream for sale
augmentin 125 mg
synthroid buy online uk
buy lyrica
suhagra buy online
buy lyrica 150mg
prednisone capsules
buy prednisone mexico
lyrica no prescription
can i buy prednisone over the counter in usa
prednisone 473
prednisone 500 mg tablet
valtrex generic cost
buy valtrex no prescription
baclofen 25 mg price
elimite cream over the counter
synthroid online no prescription
elimite cream generic
where can you buy accutane
diflucan 400mg
how much is valtrex without prescription
where can i get azithromycin pills
lyrica medication generic
synthroid price comparison
synthroid 200 mcg
how much is lyrica
valtrex cream coupon
generic albuterol cost
propecia 5mg sale
generic brand glucophage
propecia online for sale
furosemide on line
prednisone pill
zithromax online usa
metformin discount
lioresal otc
elimite price
can you buy prednisone over the counter
synthroid tablets 75 mcg
zithromax 250 g
prednisone 50 mg for sale
prednisone tablets 5mg price
augmentin amoxicillin
furosemide price uk
medicine tadalafil tablets
steroids prednisone for sale
Hey There. I found your blog using msn. This is a really well written article.
I’ll make sure to bookmark it and return to read more of your
useful information. Thanks for the post. I will definitely comeback.
synthroid 0.75 mcg
where to buy acticin
buy accutane australia
buy lisinopril without prescription
prednisone 20 mg tablets
valtrex pills
buy synthroid uk
prednisone 40 mg daily
accutane price in canada
accutane gel
online pharmacy discount code 2018
buy lyrica from canada
lyrica 330 mg
buy lisinopril canada
buying doxycycline online in usa
baclofen 20 mg price in india
best canadian pharmacy no prescription
prednisone pack
lioresal
finasteride 5 mg
lisinopril 20 mg tablets
order cialis pills
prinivil 5 mg tablets
diflucan singapore pharmacy
metformin without a script
azithromycin prescription cost
baclofen online uk
diflucan otc australia
where to buy clomid in canada
prednisone in mexico
how to get prednisone online
120 prednisone
prednisone cream otc
synthroid 125 mg coupon
canada rx pharmacy
accutane 5 mg
can you buy valtrex online
valtrex generic pill
synthroid 0.05 mg tablets
amoxicillin 875 mg tablet
suhagra 50mg tablet online
elimite price in india
elimite cost
best european online pharmacy
lyrica 5
lyrica 325 mg
buy ventolin online cheap
metformin 40 mg
baclofen australia
prednisone by mail
online pharmacy without prescription
lyrica over the counter drug
The Brand New Technology For Those Who Want To Be Incredibly Rich https://guruprofitbot.pages.dev
can you buy zithromax in canada
buy lisinopril online no prescription
prescription drug lyrica
where can i buy valtrex
retin a 0.1 cream canada
baclofen 15
lisinopril cost
cost of baclofen uk
20 mg lisinopril tablets
albuterol 100 mcg
lyrica 50 mg cost
augmentin 250mg
where can i get azithromycin pills
buy generic valtrex online
metformin 178
suhagra price
valtrex otc
cheap accutane singapore
suhagra 50 online purchase in india
combivent inhaler instructions
20 mg prednisone daily
where can i buy azithromycin
over the counter tadalafil usa
lyrica tablets uk
prednisone 10 mg tablets
prednisone brand name cost
diflucan price canada
azithromycin 500mg online
cost of prednisone
generic prednisone pills
synthroid prescription uk
albuterol nebulizer
valtrex for sale uk
prinivil medication
lyrica uk
valtrex buy
amoxicillin online without prescription
buy propecia online cheap
albuterol 0.8 mg
baclofen lioresal
finasteride prices
diflucan discount
bitcoin pharmacy online
clomid 50mg price
synthroid cost canada
synthroid 200 mcg tablet
lyrica 10 mg
how to get valtrex
lasix 100mg
diflucan 500
buy cheap lasix
price of diflucan
clomid pills buy
doxycycline 100mg india
cheap lyrica
lyrica usa
how to get accutane prescription online
generic elimite
Hi there, its nice piece of writing about media print, we all know media is a enormous source of data.
generic lyrica cost
lisinopril 15 mg
lyrica 150 mg cost
synthroid pills from canada
canadian pharmacy world coupon
diflucan generic brand
propecia tablets uk
accutane online no prescription
buy suhagra 100mg online
cost of lisinopril in canada
order lyrica online
how to buy valtrex
40 mg baclofen
amoxil without a prescription
suhagra 100 online in india
where can i buy lyrica
10 mg prednisone tablets
best online pet pharmacy
lyrica 5
mail order pharmacy
furosemide 50 mg daily
dexamethasone brand name australia
valtrex 500 mg cost
no prescription proventil inhaler
lisinopril 30
diflucan 1
lasix medication generic
prednisone 5mg coupon
paypal buy valtrex online canada
accutane pills price
dexona tablet price in india
buy tretinoin cream nz
lasixonline
prednisone 20mg capsule
lisinopril 420 1g
lipinpril
Do you mind if I quote a couple of your posts as long as I provide credit and sources back to your weblog? My blog site is in the very same area of interest as yours and my visitors would truly benefit from a lot of the information you present here. Please let me know if this alright with you. Regards!
buy lyrica cheap
buy synthyroid online
glucophage 142
suhagra 100mg tablet price in india
canadian prescription pharmacy
how much is propecia in singapore
tadalafil 10mg buy
synthroid 25 mcg daily
lyrica pill
baclofen 75 mg
how can i order prednisone
order baclofen
buy accutane in india
dexamethasone 3 mg
prednisone over the counter cost
acticin
how to get propecia pill
prednisone price in india
prednisone over the counter
propecia 5mg canada
order elimite online
purchase prednisone
lasix 80 mg tablet
20 mg of prednisone
buy prednisone without prescription paypal
diflucan uk online
Thank you for some other informative web site. Where else may just I am getting that kind of info written in such a perfect way? I have a venture that I am simply now running on, and I have been at the glance out for such information.
paypal buy valtrex online canada
buy metformin 500 mg
valtrex 100 mg
prescription albuterol online
buy propecia without a prescription
azithromycin over the counter mexico
elimite online
azithromycin 39 tablets
valtrex for sale cheap
order accutane online canada
lyrica 2019 coupon
buy clomid online from canada
order baclofen online
buy propecia 1mg online
valtrex without prescription com
diflucan 150 mg tablet price
ventolin hfa 90 mcg
valtrex 500 mg daily
lisinopril 49 mg
best generic synthroid
Thank you for sharing these valuable information with us, I wish you plenty of hits.
cheap generic accutane
where to get accutane online
lyrica 75 mg tablet price in india
lyrica discount
synthroid 50 mg cost
where can i buy elimite cream
buy vermox cheap
how much is lyrica prescription
where can i order ventolin in canada without a prescription
90 vermox
buy diflucan otc
compare propecia prices
buy generic valtrex without prescription
augmentin 1 mg tab
elimite cream directions
valtrex cheapest price
order elimite online
suhagra 100 buy online
valtrex medicine
lyrica 30 mg
valtrex uk
where to buy diflucan pills
lyrica 450 mg
vermox tablet
buy prednisone online without prescription
buy clomid online uk
elimite purchase
dexamethasone online pharmacy
canadian pharmacy happy family store
albuterol 8
how to get diflucan
valtrex 1000 mg tablet
Hey are using WordPress for your blog platform? I’m new to the blog world but I’m trying to get started and create my own. Do you need any coding knowledge to make your own blog? Any help would be greatly appreciated!
propecia 5mg for sale
diflucan capsule
cheap elimite
prednisone cost canada
baclofen 10 mg tablets
clomid online pharmacy
herpes medication valtrex
where can i buy accutane online
valtrex medicine
generic pharmacy online
propecia online pharmacy
buy valtrex tablets
baclofen 20 mg price
best price for lisinopril 20 mg
canada pharmacy clomid
candida diflucan
how much is azithromycin 250 mg
zithromax tablets price
synthroid united states
ventolin 2.5 mg
diflucan over the counter singapore
elimite cream price in india
happy family drug store
canadian pharmacy india
buy lyrica cheap
baclofen 420 mg
lyrica generic usa
buy lasix online with mastercard
diflucan medication
lisinopril 12.5 mg
suhagra 50 tablet price
escrow pharmacy online
buy generic baclofen
Thank you very much for sharing, I learned a lot from your article. Very cool. Thanks. nimabi
can you buy valtrex over the counter in uk
vermox medication
by prednisone w not prescription
cost of generic azithromycin
lyrica 75 mg price in india
buy accutane online no prescription
baclofen tablet price
prednisone 25
buy valtrex online no prescription
diflucan 250 mg
azithromycin 500mg purchase
cost of permethrin cream
elimite drug
retin a uk
synthroid 0.75 mcg
prinivil lisinopril
cost of diflucan
doxycycline 60 mg
buy lyrica online india
medicine augmentin 375
albuterol price in uk
accutane price south africa
buy suhagra 50 online
zestril 5mg price in india
dexamethasone 6 tablet
best price for synthroid 50 mcg
valtrex 400 mg
albuterol price in mexico
prednisone 4
generic for lasix
lisinopril 20 mg india
lyrica mexico
generic for combivent
worldwide pharmacy online
lisinopril prescription
diflucan tablet australia
where can i buy elimite
propecia singapore online
accutane medication price
clomid over the counter nz
buying accutane online
how to buy zithromax online
propecia discount online
canadian pharmacy ltd
buy valtrex online without prescription
medicine baclofen 10 mg
retin a cream generic
valtrex for sale canada
225 mg lyrica
cheap metformin uk
order azithromycin online
prednisone 20mg by mail without prescription
can i buy ventolin over the counter uk
can i buy diflucan over the counter uk
buy suhagra online
buy lisinopril canada
propecia 84 tablets
acticin without prescription
where can i purchase elimite
lyrica 200 mg price
cialis 6
buy prednisone online no script
clomid tablet online india
combivent respimat
baclofen 40 mg
can you buy accutane online
zestoretic 25
buy suhagra 50mg
buy propecia 1mg online uk
lyrica discount
baclofen 100mg
can you buy metformin over the counter in usa
lyrica 225 mg
dexamethasone 0.75
augmentin 175 mg
buy zithromax 250mg
lisinopril 2.5 mg coupon
can you buy metformin without prescription
synthroid cost canada
prednisone 200 mg tablets
doxycycline canada pharmacy
where to buy elimite cream over the counter
prednisone otc canada
thx for man bro strictly happmoon in moscow. Thanks All brother.
dexamethasone coupon
cost of synthroid 50 mcg
acticin 650
metformin canada pharmacy
albuterol 0.08
valtrex without prescription us
vermox mexico
suhagra 50mg tablet online
azithromycin in singapore
accutane india buy
can you buy furosemide over the counter
dexamethasone discount
buy valtrex online cheap
legit online pharmacy
lisinopril 5 mg price
buy acticin
amoxil 250 mg capsule
average cost of synthroid
dexamethasone 6 mg tablet
price of valtrex with insurance
brand name azithromycin
azithromycin 50 mg
doxycycline prescription discount
lyrica tablet cost
buy valtrex pills online
can you buy cialis without a prescription
legitimate canadian mail order pharmacy
zithromax 1000 mg for sale
valtrex drugstore
thx for man bro strictly happmoon in moscow. Thanks All brother.
metformin 750 mg tablets
propecia tablet in india
baclofen purchase
diflucan capsule 150mg
diflucan.com
prednisone rx coupon
order diflucan online cheap
prednisone 60 mg price
diflucan cost
happy family pharmacy india
online pharmacy pain relief
prednisone purchase canada
generic for synthroid
thx for man bro strictly happmoon in moscow. Thanks All brother.
zithromax cost canada
online propecia uk
prinivil lisinopril
furosemide india
prednisone 50 mg for sale
metformin cost canada
I am regular reader, how are you everybody? This post posted at this web site is truly good.
buy generic valtrex without prescription
synthroid generic canada
lisinopril 19 mg
diflucan 150 cost
best online pharmacy for viagra
buy generic lyrica online
diflucan rx
buy prednisone without rx
prednisone 20mg cost
order prednisone online
accutane discount
prednisone pills
order prednisone online no prescription
prednisone 40 mg
valtrex online uk
lyrica 200 mg
lyrica 300
combivent cost
synthroid 137 mg
elimite price
dexamethasone 4 mg tablet
albuterol generic otc
buy lisinopril 40 mg online
generic diflucan 150 mg
doxycycline 300 mg tablet
online drugs valtrex
can you buy valtrex over the counter in mexico
where to get accutane prescription
prednisone australia
best retin a cream prescription
clomid uk purchase
where can you get azithromycin over the counter
azithromycin 750 mg
how to get accutane without prescription
where can i buy prednisone online uk
synthroid with no prescription
amoxicillin 675 mg
order glucophage
lyrica 75 mg price in canada
buy diflucan uk
suhagra 100mg tablet price
cheap generic valtrex online
combivent order
valtrex 500mg price
baclofen 10 mg cost
happy family rx
lyrica 300
prednisone 13 mg
generic for azithromycin
accutane tablets
prednisone tablets 5mg price
diflucan cap 150 mg
discount valtrex online
cheap prednisone
order azithromycin 500mg
tretinoin 0.5 cream
doxycycline 200mg
buy metformin 1000 mg
medicine albuterol pills
elimite drug
azithromycin 250 mg over the counter
where to buy propecia in canada
finasteride
thx for man bro strictly happmoon in moscow. Thanks All brother.
valtrex price australia
valtrex 500 mg for sale
buy lasix online usa
tretinoin cost uk
lyrica online uk
retin a 5 cream
vermox canada
70 mg accutane
tadalafil tablets cost in india
dexamethasone cream over the counter
lyrica medication
albuterol 5 mg
buy elimite uk
azithromycin medicine over the counter
how much is elimite cream
how to order valtrex
diflucan 250 mg
prednisone 32mg
deltasone drug
tretinoin cream online pharmacy mexico
buy accutane from india
buy zithromax online cheap
prednisone 20mg by mail without prescription
lyrica 75 mg capsule
synthroid 175 mcg
generic accutane
accutane coupon
discount propecia coupon
metformin tablet cost
30 mg tadalafil
accutane tablets buy online
order elimite online
diflucan tablets australia
lyrica 150
vermox tablets where to buy
albuterol 90 mcg prescription
prednisone 4mg
diflucan 1140
valtrex uk price
how much is a prednisone prescription
ventolin inhaler for sale
zithromax 100 mg
azithromycin cap 500 mg
cheap accutane
accutane prescription nz
where can i buy metformin without a prescription
canada pharmacy 24h
average cost of lasix
synthroid 100 mcg daily
baclofen price south africa
zestoretic tabs
lyrica without rx
how much is a valtrex prescription
azithromycin 2g
lyrica pills 50 mg
buy elimite cream over the counter
suhagra price
cheap diflucan
lisinopril 2019
prednisone pill prices
dexamethasone 20 mg
where to buy tretinoin cream otc
valtrex 500 mg for sale
buy generic prednisone online
suhagra pills
prednisone without prescription medication
augmentin 875 mg 125 mg tablet price
lyrica 100 mg coupon
finpecia tablet
Thank you very much for sharing, I learned a lot from your article. Very cool. Thanks. nimabi
cheapest lyrica online
albuterol online canada
dexamethasone 4 tablet
generic azithromycin over the counter
lioresal tablet
lisinopril cost canada
order azithromycin 500mg online
albuterol 0.063
where to buy azithromycin over the counter
buy doxycycline online without prescription
prednisone cost
where to buy metformin tablets
no prescription cialis canada
valtrex generic purchase
dexamethasone price in usa
augmentin tablets 625mg
valtrex prescription online
prednisone brand name australia
buy accutane 10mg
430 mg baclofen
clomid prescription canada
synthroid 1.25 mcg
where to get propecia prescription
elimite medication
dexamethasone 0.5 tablet
online pharmacy reddit
valtrex pharmacy
order valtrex online canada
lisinopril 3760
azithromycin 250 mg price in india
prednisone 10 tablet
pharmacies in canada that ship to the us
valtrex uk over the counter
valtrex 1000 mg for sale
propecia cream
suhagra 100 buy online
lisinopril 20mg 25mg
5mg cialis
zithromax without prescription
lisinopril 20 mg tablet price
lyrica prescription cost
cost fildena 50mg https://community.alteryx.com/t5/user/viewprofilepage/user-id/524453/ stromectol 3mg information
where to buy generic propecia
prednisone 2.5 mg daily
lyrica for sale
how to order retin a from mexico
lyrica tablets for sale
buy synthroid online without prescription
synthroid online without prescription
furosemide online canada
where to buy elimite cream
brand name prednisone
buy fluconazol without prescription
acticin online
valtrex brand cost
dexona price
Howdy just wanted to give you a quick heads up. The text in your post seem to be running off the screen in Chrome. I’m not sure if this is a format issue or something to do with internet browser compatibility but I thought I’d post to let you know. The style and design look great though! Hope you get the problem resolved soon. Cheers
Hi, i think that i saw you visited my weblog so i got here to go back the choose?.I am trying to in finding things to improve my site!I assume its good enough to use some of your concepts!!
Min man har testat och det var en hit kan jag säga 🙂 Det blev ett par orgasmer var och vi var båda helt slut efteråt. Blev väl dryga 2 timmar för oss innan vi slocknade 😉 Akta dig för kycklingäggsproblemet. När fester är glada, men be först om bevis, kontrollera om du har möjlighet att tillhandahålla den bevisbördan. Och projekt som syftar till förebyggande åtgärder är alltid svåra, Hammarby Boxning Power Hours är enligt mig det bästa lusthöjande medlet för män 2021. Du tar en tablett, och redan efter 1-2 timmar kommer du se effekt – då är det bara att tuta och köra. Men smakar det så kostar det – priset per tablett är ganska högt. Om din bärbara spelare låter lite slapp kan du ge den extra potens med Insignias lilla bärbara förstärkare.
https://ree-m.co.kr/bbs/board.php?bo_table=free&wr_id=197902
viagra cosa serve viagra consegna in 24 ore pagamento alla consegna esiste il viagra generico in farmacia sildenafil viagra 100mg generic viagra romanviagra viagra from canada pfizer viagra 100mg price cheap viagra online sildenafil viagra 100mg generic viagra romanviagra viagra cosa serve viagra consegna in 24 ore pagamento alla consegna esiste il viagra generico in farmacia viagra cosa serve viagra consegna in 24 ore pagamento alla consegna esiste il viagra generico in farmacia average cost viagra viagra for sale online canada viagra pills 100 mg average cost viagra viagra for sale online canada viagra pills 100 mg comprar viagra en espaГ±a amazon: viagra online cerca de bilbao – comprar viagra en espaГ±a amazon comprar viagra en espaГ±a envio urgente: viagra online rГЎpida – viagra online cerca de zaragoza
I am truly thankful to the owner of this web site who has shared this fantastic piece of writing at at this place.
thx for man bro strictly happmoon in moscow. Thanks All brother.
Hey! Someone in my Myspace group shared this site with us so I came to give it a look.
I’m definitely enjoying the information. I’m bookmarking and
will be tweeting this to my followers! Excellent blog and wonderful style
and design.
thx for man bro strictly happmoon in moscow. Thanks All brother.
Hi there, yes this article is truly pleasant and I have learned lot of things from it concerning blogging. thanks.
thx for man bro strictly happmoon in moscow. Thanks All brother.
I blog quite often and I really appreciate your content. This great article has really peaked my interest. I am going to book mark your website and keep checking for new information about once a week. I subscribed to your RSS feed as well.
Porn videos
thx for man bro strictly happmoon in moscow. Thanks All brother.
thx for man bro strictly happmoon in moscow. Thanks All brother.
It is not my first time to pay a visit this website, i am visiting this web site dailly and get nice information from here daily.
I’m now not positive where you are getting your info, however good topic. I needs to spend a while studying more or understanding more. Thank you for great information I used to be in search of this information for my mission.
Your means of explaining the whole thing in this
post is truly fastidious, all can easily know it, Thanks a lot.
thx for man bro strictly happmoon in moscow. Thanks All brother.
thx for man bro strictly happmoon in moscow. Thanks All brother.
I am extremely impressed with your writing skills and also with the layout on your blog. Is this a paid theme or did you customize it yourself? Either way keep up the nice quality writing, it’s rare to see a nice blog like this one these days.
What can I use if I dont have my inhaler satinex substitute albuterol inhaler
thx for man bro strictly happmoon in moscow. Thanks All brother.
We receive updated cryptocurrency prices directly from many exchanges based on their pairs. We then convert the number to USD. A full explanation can be found here. Cryptocurrency prices could fall further in 2022. They leaped to a record high of almost $69,000 in November, but they are now below $50,000, down nearly 30 percent from its high. Carol Alexander, a Sussex University professor of finance, expects Bitcoin to plummet to a low of $10,000 in 2022, which would erase most of its gains in the past year and a half. Generally, top cryptocurrencies are ranked by market cap. This page can show you the top 10 cryptocurrencies by market cap, and you can sort the list in ascending or descending order. Despite their original promise, cryptocurrencies haven’t acted as hedges against inflation. Instead, they’ve trended with the broader indexes. Read The Big Picture and Market Pulse to track daily market trends.
https://andersondffd992649.blogsmine.com/23733961/manual-article-review-is-required-for-this-article
Buy cryptocurrencies like Trader Joe quickly and securely on MEXC. You can purchase cryptocurrencies using methods such as credit card or other payment methods. You can also trade among various cryptocurrencies across markets, including spot trading and derivatives like perpetual futures. The total supply of JOE (JOE) is 500 million. The token was launched without a pre-sale, private sale, or pre-listing allocations. The distribution of JOE is as follows: Wall Street Journal To make this possible, of course, the platform needs liquidity. This means that the tokens need to be provided by the people and available for use. And to do that, the platform allows all visitors to become liquidity providers by letting them buy a certain share of these tokens and then permitting Trader Joe to exchange them.
What should you not say to your partner viagra 50 mg tablet online purchase
Doktorum Ol Randevu Sitesi’nde uzman doktorlarla tanışın. Sağlığınıza hemen değer katın.
Если мужчина не любит, как он себя ведет: 10 признаков Я манипулирую тобой: Методы противодействия скрытому воздействию https://batmanapollo.ru/ Плохо ли, когда тобой пользуются? Это значит, что ты не бесполезен? Кто такой манипулятор?
http://amoxil.icu/# amoxicillin 500 mg tablets
amoxicillin pills 500 mg: can i purchase amoxicillin online – amoxicillin online without prescription
I simply could not go away your web site prior to suggesting that I really enjoyed the standard info a person supply on your guests Is going to be back incessantly to investigate crosscheck new posts
Thank you for the auspicious writeup It in fact was a amusement account it Look advanced to far added agreeable from you However how can we communicate
get generic clomid can you buy clomid prices – order generic clomid without rx
Beyin ve sinir cerrahisi konusunda uzman bir doktor bulmak, hayat kurtarıcı olabilir. Doktor Sitesi, bu konuda bana harika bir rehberlik sağladı. Teşekkürler!
https://amoxil.icu/# amoxicillin medicine
http://ciprofloxacin.life/# ciprofloxacin over the counter
cost of generic clomid without insurance: can i get clomid without prescription – where can i buy cheap clomid without insurance
Simply want to say your piece is as astonishing. The clearness in your post is just great and i could assume you are an expert on this topic Fine with your permission let me grasp your subscription to be up to date with imminent post Thanks a million and please keep up the rewarding job.
arimidex for sale no prescription
I think all the thoughts you’ve given for your post are convincing and will function, but the posts are rather short for beginners. Could you prolong them a bit from next time? Thanks for the post.
I liked it as much as you did. Even though the picture and writing are good, you’re looking forward to what comes next. If you defend this walk, it will be pretty much the same every time.
Alanya’nın sıcakkanlı insanlarıyla tanışmak, gerçek bir sevgi ve dostluk deneyimi sunuyor.
Comment reconnaitre un homme qui n’a jamais fait l’amour acheter viagra pharmacie
Встречайте Лаки Джет краш – игру, которая заставит ваше сердце биться чаще! Сделайте ставку на сайте 1win и следите за полетом Джо.
En iyi hosting firmaları arasında yer alan sunucucozumleri.com, benim için vazgeçilmez oldu!
I’m gone to tell my little brother, that he should also visit this blog on regular basis to get updated from most up-to-date information.
thx for man bro strictly happmoon in moscow. Thanks All brother.
thx for man bro strictly happmoon in moscow. Thanks All brother.
I am not sure where you’re getting your info, but good topic. I needs to spend some time learning much more or understanding more. Thanks for magnificent info I was looking for this information for my mission.
Sweet blog! I found it while browsing on Yahoo News. Do you have any tips on how to get listed in Yahoo News? I’ve been trying for a while but I never seem to get there! Cheers
Cenforce us Can I buy over-the-counter cough syrups without a prescription?
Nice blog here Also your site loads up very fast What host are you using Can I get your affiliate link to your host I wish my site loaded up as quickly as yours lol
Hi there to all, it’s in fact a good for me to visit this web site, it contains important Information.
I’m really enjoying the design and layout of your site. It’s a very easy on the eyes which makes it much more enjoyable for me to come here and visit more often. Did you hire out a designer to create your theme? Great work!
Protez saçın bakımı çok kolay! Sadece düzenli temizlik ve bakım ile uzun ömürlü kullanım sağlıyor.
A fascinating discussion is worth comment. I believe that you should write more on this topic, it might not be a taboo subject but generally people do not discuss such subjects. To the next! Kind regards!!
I’m gone to inform my little brother, that he should also go to see this weblog on regular basis to take updated from newest gossip.
I’m really enjoying the design and layout of your blog. It’s a very easy on the eyes which makes it much more enjoyable for me to come here and visit more often. Did you hire out a designer to create your theme? Great work!
Oh my goodness! Awesome article dude! Thanks, However I am encountering difficulties with your RSS. I don’t know why I can’t subscribe to it. Is there anybody else getting the same RSS problems? Anyone who knows the solution will you kindly respond? Thanx!!
Nice post. I was checking continuously this blog and I am impressed! Very useful information specially the last part 🙂 I care for such info a lot. I was seeking this particular info for a long time. Thank you and good luck.
Onwin Bonus Kampanyaları: Onwin, kullanıcılarına çeşitli bonus ve promosyonlarla avantajlı bir oyun deneyimi yaşatmayı hedefliyor.
Heya are using WordPress for your blog platform? I’m new to the blog world but I’m trying to get started and create my own. Do you need any coding knowledge to make your own blog? Any help would be greatly appreciated!
Çevrimiçi flört dünyasına dalma zamanı geldi. Umarım burada güzel bir bağlantı kurarım!
thx for man bro strictly happmoon in moscow. Thanks All brother.
Your writing is an odyssey of ideas, with each post serving as a waypoint on the intellectual journey. The narrative unfolds like a cartographer’s map, guiding readers through uncharted territories of profound understanding.
Dinamobet’in bonusları cidden çekici! İlk üyelik bonusunu kaçırmayın. Bonus DinamobetBonus
Hi to all, how is all, I think every one is getting more from this web site, and your views are good designed for new viewers.
Whoa, that blog style is awesome. For what duration have you been blogging? You made it look so easy. Overall, your website looks great, and the content is much better.
Way cool! Some extremely valid points! I appreciate you penning this write-up and
also the rest of the website is also very good.
For those who appreciate the finer things in cannabis life, CallMeTHCa.com is your ticket to the top-tier of Hemp THCa delights. Elevate and celebrate!
https://indianpharmacy.shop/# indianpharmacy com
online pharmacy india
Kişisel bakım rutinime eklediğim roll-on deodorant, tazelenmiş hissetmemi sağlıyor.
Hello there! I could have sworn I’ve been to this blog before but after browsing through some of the posts I realized it’s new to me. Anyways, I’m definitely pleased I found it and I’ll be bookmarking it and checking back regularly!
I truly appreciate your technique of writing a blog. I added it to my bookmark site list and will
Clearwater revels in elevated highs with CallMeTHCa.com. Unleash THC excellence on the Clearwater beaches.
medyum mahirzade ile tanışmanın vakti geldi.
欢迎来到我们的加密货币博客,这里是探索数字货币世界的绝佳平台。我们致力于提供最新的加密货币新闻、深入的市场分析、投资策略和技术解读。无论您是加密货币的初学者还是经验丰富的投资者,我们的博客都能为您提供有价值的见解。加入我们,一起探索比特币、以太坊、莱特币等多种加密货币的激动人心的旅程,并深入了解区块链技术如何改变世界。
https://auto-noginsk.ru
ZoogVPN, favori içeriklere hızlı ve güvenli erişim sağlıyor. Her an her yerde keyifli anlar! GüvenliErişim
크립토 코리아: 인사이트와 트렌드”는 한국에서 가장 신뢰받는 암호화폐 블로그 중 하나입니다. 최신 암호화폐 뉴스, 시장 분석, 트레이딩 전략을 제공하며, 블록체인 기술과 관련된 혁신적인 아이디어를 탐구합니다. 초보자부터 전문가까지 모든 수준의 투자자와 열정적인 크립토 커뮤니티가 찾는 곳입니다. 이 블로그는 한국의 크립토 트렌드를 이해하는 데 필수적인 자원이며, 암호화폐의 복잡한 세계를 이해하기 위한 명확하고 실용적인 가이드를 제공합니다. 여기서는 최신 ICO 분석, 암호화폐 거래소 리뷰, 블록체인 스타트업의 인터뷰 및 분석 기사를 찾을 수 있습니다.
https://copyrait.ru/
「クリプトジャパン」へようこそ。このブログは、仮想通貨の複雑な世界を解き明かすための信頼できるガイドです。初心者から上級者まで、最新の市場動向、投資戦略、技術分析、そして仮想通貨に関する法律や税制についてわかりやすく解説します。日本国内外の仮想通貨市場のニュースをいち早くお届けし、あなたの仮想通貨投資を成功へと導くための情報源となることを目指しています。
galaxyflowers.ru
Welcome to CryptoSutra, the premier destination for Indians to unravel the dynamic world of cryptocurrency. This blog serves as a beacon for beginners and seasoned investors alike, navigating the often complex waters of digital currencies. Our mission is to demystify the world of Bitcoin, Ethereum, and a myriad of altcoins, making them accessible to the Indian investor.
At CryptoSutra, we understand the unique position of India in the global crypto landscape. We offer tailored content that respects the nuances of Indian regulations, economic trends, and market sentiments. From breaking down RBI’s latest guidelines to exploring investment strategies suited for the Indian market, our focus is to empower you with knowledge.
Our blog features:
Educational Guides: Step-by-step tutorials, glossaries, and infographics that simplify blockchain technology and cryptocurrency trading principles.
Market Analysis: Timely insights and analyses of global market trends, with a special focus on how they impact the Indian economy.
Investment Strategies: Practical advice on portfolio management, risk assessment, and leveraging crypto assets in the Indian context.
gaffarov.ru
Greeting to CryptoSphere, your maximum goal for the sake of all things cryptocurrency. Whether you’re a seasoned investor or a curious learner, our blog offers a wealth of data to aid you nautical con the complex and ever-evolving sphere of digital currencies. From in-depth analyses of the latest sell trends to empirical guides on blockchain technology and investment strategies, CryptoSphere is your honourable authority looking for timely, with an eye to, and insightful content. Solder together our community to remain to the fore in the eager and overpowering cosmos of cryptocurrency.
aple-system.ru
Offer hospitality to to CryptoSphere, your basic stopping-place in spite of all things cryptocurrency. Whether you’re a acclimatized investor or a unconventional beginner, our blog offers a fullness of information to keep from you pilot the complex and ever-evolving sphere of digital currencies. From in-depth analyses of the latest market-place trends to empirical guides on blockchain technology and investment strategies, CryptoSphere is your reliable authority for auspicious, accurate, and insightful content. Verge on our community to remain to the fore in the active and overpowering coterie of cryptocurrency.
aple-system.ru
Casino https://vulkan.electronauto.ru
Willkommen bei ‘KryptoKompass’, Ihrem ultimativen Leitfaden in der dynamischen und faszinierenden Weal der Kryptowahrungen. Unser Blog bietet Ihnen aktuelle Nachrichten, tiefgehende Analysen und wertvolle Einblicke in bite the dust Contusion von Bitcoin, Ethereum, Cat’s-paw und vielen anderen digitalen Wahrungen. Egal, ob Sie ein Anfanger oder ein erfahrener Investor sind, wir liefern Ihnen die Informationen, degenerate Sie brauchen, um fundierte Entscheidungen zu treffen. Tauchen Sie ein in unsere Expertenartikel, Tutorials und Marktprognosen, um Ihr Krypto-Wissen zu erweitern. Mit ‘KryptoKompass’ bleiben Sie immer auf dem neuesten Stand der Entwicklungen im Kryptoraum
carsused.ru
Willkommen bei ‘KryptoKompass’, Ihrem ultimativen Leitfaden in der dynamischen und faszinierenden Bruise der Kryptowahrungen. Unser Blog bietet Ihnen aktuelle Nachrichten, tiefgehende Analysen und wertvolle Einblicke in die Welt von Bitcoin, Ethereum, Ripple und vielen anderen digitalen Wahrungen. Egal, ob Sie ein Anfanger oder ein erfahrener Investor sind, wir liefern Ihnen euphemistic depart Informationen, die Sie brauchen, um fundierte Entscheidungen zu treffen. Tauchen Sie ein in unsere Expertenartikel, Tutorials und Marktprognosen, um Ihr Krypto-Wissen zu erweitern. Mit ‘KryptoKompass’ bleiben Sie immer auf dem neuesten Stand behind der Entwicklungen im Kryptoraum
carsused.ru
I was recommended this website by my cousin I am not sure whether this post is written by him as nobody else know such detailed about my difficulty You are wonderful Thanks
O mundo das criptomoedas tem atraido cada vez mais atencao nos ultimos anos, mas para realmente compreender o potencial desses ativos digitais, e essencial entender a tecnologia que esta por tras deles: o blockchain.
O blockchain e uma tecnologia de registro distribuido que garante a seguranca e a transparencia das transacoes. Em essencia, e um livro-razao digital, onde as transacoes sao gravadas em ‘blocos’ e cada bloco esta conectado ao anterior, formando uma ‘cadeia’. Esta estrutura unica garante que uma vez que uma transacao e adicionada ao blockchain, ela nao pode ser alterada ou apagada, oferecendo um nivel de seguranca sem precedentes.
Alem de ser a espinha dorsal das criptomoedas, como o Bitcoin e o Ethereum, o blockchain tem potencial para revolucionar diversos outros setores, como o financeiro, o juridico e ate mesmo o governo, oferecendo maneiras mais eficientes e seguras de realizar e registrar transacoes.
No entanto, apesar de suas muitas vantagens, o blockchain ainda enfrenta desafios, incluindo questoes de escalabilidade e a necessidade de maior regulamentacao para prevenir usos ilicitos. Mas, a medida que a tecnologia continua a evoluir, ela oferece a promessa de um futuro mais transparente, seguro e eficiente.
Para os entusiastas de criptomoedas, entender o blockchain nao e apenas uma questao de curiosidade, mas uma necessidade para navegar com seguranca e confianca neste novo e emocionante mundo digital.
https://korablik-zabeg.ru
Bienvenue sur “L’Essor de la Cryptomonnaie”, votre source incontournable d’informations, de guides et d’analyses approfondies sur le monde fascinant des cryptomonnaies. Que vous soyez un investisseur aguerri ou un debutant curieux, notre blog offre une plateforme d’apprentissage et de discussion sur les dernieres tendances, les technologies blockchain, et les meilleures strategies d’investissement dans le domaine des monnaies numeriques. Rejoignez notre communaute pour demeurer a la pointe de l’innovation financiere et technologique.
https://ptcinnovationforum.ru
Hi i think that i saw you visited my web site thus i came to Return the favore Im attempting to find things to enhance my siteI suppose its ok to use a few of your ideas
Bienvenidos a ‘CriptoAlcance’, su portal de confianza para sumergirse en el vibrante mundo de las criptomonedas. Aqui encontraras analisis detallados, noticias actualizadas, guias para principiantes y discusiones en profundidad sobre las tendencias mas recientes en Bitcoin, Ethereum, y otras monedas digitales. Nuestro equipo de expertos te brindara consejos practicos, estrategias de inversion y te mantendra al tanto de los cambios regulatorios y tecnologicos que afectan el mercado. Unete a nuestra comunidad y empieza tu viaje en el fascinante universo de las criptomonedas con ‘CriptoAlcance’.
https://allwow.ru
Benar, Pragmatic88 merupakan agen resmi Pragmatic Play di Indonesia. Bersama dengan Pragmatic123, PragmaticID, dan Pragmatic88 merupakan bagian dari Pragmatic Group Indonesia. Hal ini membuat Anda bisa memainkan seluruh permainan slot online yang dibuat oleh Pragmatic Play, termasuk game terbaru yang akan selalu diperbarui. Pragmatic play adalah sebuah provider game slot online yang memberikan akun demo slot yang bisa dimainkan secara gratis dan tentunya anti rungkad. Permainan demo slot gratis saat ini sangatlah gencar di cari oleh para pemain slot online karena game ini dapat dimainkan tanpa mengeluarkan uang. Selain itu dengan bermain akun demo slot pragmatic anda bisa melihat serta menganalisa berbagai pola slot gacor untuk diterapkan pada akun pragmatic play uang asli.
https://www.hotel-bookmarkings.win/best-online-casino-for-blackjack-1
All the Slots Action, None of the Risk: You can enjoy free slot play without risking a dime. Try real slots with play credits awarded by the casino before you start playing for real money. 888 NJ online casino welcomes all legal age players in the Garden State to register and play online casino games. Sign up at 888 Casino, play your $20 free bonus – no deposit needed, and enjoy all your favorite online casino games. To begin your free Vegas slots adventure, navigate to our expansive collection slots. Simply scroll upwards to access our wide range of games. If you’re unsure about which free slot game to choose, make use of our convenient filtering system. You have the option to sort through our free slots hub alphabetically, from new to old, or by popularity. This allows you to find the perfect game that suits your preferences and gaming style. Enjoy exploring our diverse selection and get ready for an exciting gaming experience.
Welcome to CryptoSphere, your go-to destination for all things cryptocurrency and blockchain. Our blog is dedicated to providing insightful, up-to-date information and analysis on the dynamic world of digital currencies. Whether you’re a seasoned investor or just starting out, you’ll find valuable content here, including in-depth guides on cryptocurrency trading, reviews of blockchain technologies, and the latest news in the crypto space.
At CryptoSphere, we believe in the transformative power of cryptocurrencies and blockchain technology. Our mission is to demystify this complex world and make it accessible to everyone. We offer a range of articles, from beginner-friendly explanations of basic concepts to advanced analysis of market trends.
Join us as we explore the evolving landscape of digital finance, highlight innovative projects, and offer expert opinions on where the market is headed. With CryptoSphere, stay informed, make smarter investment decisions, and be part of the financial revolution. Let’s dive into the world of cryptocurrencies together!
https://cryptoblog.pro/en/
Onwin, kapılarını açtı! Giriş yapın ve kazanmaya başlayın. Heyecan dolu anları kaçırmayın! #OnwinGiriş
Dubbed the Silicon Valley of India, software engineers in Bangalore typically make about $28,000 – $100,000, with these figures running much higher for more specialized software development fields. Most major tech companies in the world, including FAANG and Microsoft, have their offices in Bangalore. Additionally, Bangalore hosts a thriving startup ecosystem with several companies working in advanced technologies. It costs about $400+ rent per month for a single person to live in Bangalore. Tricentis was founded in 2007 by Wolfgang Platz and Franz Fuchsberger. The company provides software testing automation and software quality assurance products for enterprise software. With a totally automated approach, Tricentis offers a fully codeless and AI-driven platform that enables enterprises to accelerate their digital transformation by dramatically increasing software release speed, reducing costs, and improving software quality. Global brands like McKesson, Accenture, Nationwide Insurance, Allianz, Telstra, Dolby, and Vodafone are among the more than 2,100 customers who rely on Tricentis every day.
https://annaikravets1.onlc.eu/
The emergence of a software development team formation is based on a wide area of elements. These add the kind and problems of the software development team structure and outcome, the amount of time an individual has to put forward the outcome, and the assigned cost. Finally, the developed software is ready to be used by real users. It’s crucial to have a team of software engineers who can respond to service tickets, suggestions, and technical questions promptly. This will ensure the users’ loyalty. The maintenance stage deals with fixing problems that weren’t noticed before and adapting the software to changes by upgrading it regularly. Team members involved: How you structure your team will depend on certain factors. When it comes to the “generalist versus specialist” approach, there is no one solution for all software development teams. At the end of the day, all projects are different and require a unique approach.
What’s up to all, it’s truly a pleasant for me to visit this website, it contains precious Information.
I do trust all the ideas you’ve presented in your post. They are really convincing and will definitely work. Nonetheless, the posts are too short for newbies. May just you please lengthen them a bit from next time? Thank you for the post.
Hi my family member I want to say that this post is awesome nice written and come with approximately all significant infos I would like to peer extra posts like this
I have read some excellent stuff here Definitely value bookmarking for revisiting I wonder how much effort you put to make the sort of excellent informative website
Although I believe every thought you have for your post is excellent and will undoubtedly be successful, the postings are too brief for new readers. Maybe you could extend them a little bit the next time? I’m grateful for the post.
Whoa! This blog looks exactly like my old one! It’s on a entirely different topic but it has pretty much the same layout and design. Great choice of colors!
Pastilla Cialis Precio
(Moderator)
Cialis 5 mg prezzo cialis prezzo cialis 5 mg prezzo
Para Que Sirve Cialis 20 Mg Precio
(Admin)
Cialis 5 mg prezzo prezzo cialis 5 mg originale in farmacia tadalafil 5 mg prezzo
I happily found this incredible website a few days ago with wonderful content for readers. The site owner has a knack for engaging fans. I’m thrilled and hope they persist in creating excellent content.
Куда Продать Varavon Выкуп
There are some good values on the board with the Angels (+3000) and Diamondbacks (+2500), both of whom are in contention to win their divisions outright. Few MLB fans would be disappointed to see likely AL MVP Shohei Ohtani in the World Series. The Astros quickly moved from +850 to +700 to win the World Series, and they should be even better positioned now that Verlander is in the fold. The Braves are currently listed at +300 to win the World Series, and these odds should stay relatively stable until the playoffs. If you like the Braves, we recommend waiting until the postseason to bet on them because that’s the best chance of longer odds. The Houston Astros won the World Series in 2022, knocking off the National League champion Philadelphia Phillies in six games to win the Fall Classic. The championship was the Astros’ second World Series win, following their victory in 2017.
https://andrenljh976663.csublogs.com/25954773/biggest-sports-betting-sites
Actionbet is too young to make a final opinion about its services and overall performance. It inspires trust as a fully licensed bookmaker and casino, but the absence of international payment options, a small range of bonuses, and a limited selection of Actionbet betting markets does not imply their ambitions of going worldwide. We have not found any evidence of fraudulent actions from their side, so we suppose it might be a good choice for a local gambling platform within Africa. ✅ Most betting markets for AFL, NRL & NBA Official Website ActionBets has no special application. Just visit actionbets from the mobile browser. You can easily log in, using your username and password. Mobile version offers sports betting and racebook. After selecting proper category, you can choose bet type or track. Mobile betting process is similar to the one on the official site. Mobile version offers viewing line and placing bets, while depositing and withdrawing is not available.
You’ve made some good points there. I looked on the internet to learn more about the issue and found most individuals will go along with your views on this website.
mexico pharmacies prescription drugs mexican pharmaceuticals online mexican border pharmacies shipping to usa
Good day! I know this is kind of off topic but I was wondering which blog platform are you using for this website?
I’m getting fed up of WordPress because I’ve had problems with
hackers and I’m looking at alternatives for another platform.
I would be great if you could point me in the direction of a good platform.
my web blog; poles made
Hi there! This post couldn’t be written any better! Going through this post reminds me of my previous roommate! He constantly kept talking about this. I will forward this information to him. Pretty sure he will have a good read. Thank you for sharing!
Heya! I’m at work browsing your blog from my new iphone 3gs! Just wanted to say I love reading your blog and look forward to all your posts! Keep up the fantastic work!
Hello, just wanted to mention, I enjoyed this article. It was inspiring. Keep on posting!
Woah! I’m really loving the template/theme of this site. It’s simple, yet effective. A lot of times it’s very hard to get that “perfect balance” between superb usability and visual appeal. I must say you have done a excellent job with this. In addition, the blog loads very fast for me on Internet explorer. Superb Blog!
I’m impressed, I must say. Rarely do I encounter a blog that’s both educative and engaging, and let me tell you, you have hit the nail on the head. The issue is something which not enough folks are speaking intelligently about. I am very happy that I stumbled across this in my search for something concerning this.
Keep on working, great job!
We stumbled over here coming from a different website and thought I may as well check things out. I like what I see so now i am following you. Look forward to looking at your web page for a second time.
I am regular reader, how are you everybody? This piece of writing posted at this web site is actually good.
You made some decent points there. I looked on the web to learn more about the issue and found most individuals will go along with your views on this site.
You really make it seem so easy with your presentation however I find this topic to be really something which I feel I would never understand. It sort of feels too complicated and very vast for me. I am looking forward in your next publish, I will try to get the hold of it!
My brother suggested I might like this blog. He was totally right. This publish actually made my day. You cann’t believe just how so much time I had spent for this information! Thank you!
I like the valuable information you supply for your articles. I will bookmark your weblog and check again here frequently. I am somewhat certain I will be informed many new stuff right here! Good luck for the following!
Im not that much of a online reader to be honest but your blogs really nice, keep it up! I’ll go ahead and bookmark your site to come back later. All the best
you are in reality a just right webmaster. The web site loading velocity is incredible. It sort of feels that you are doing any unique trick. In addition, The contents are masterpiece. you have performed a wonderful process in this matter!
Hi to all, the contents present at this site are in fact awesome for people experience, well, keep up the nice work fellows.
Hello there! Do you use Twitter? I’d like to follow you if that would be ok. I’m definitely enjoying your blog and look forward to new updates.
Greetings! I know this is kinda off topic but I was wondering which blog platform are you using for this site? I’m getting fed up of WordPress because I’ve had issues with hackers and I’m looking at options for another platform. I would be awesome if you could point me in the direction of a good platform.
I don’t even know how I ended up here, but I thought this post was good. I don’t know who you are but definitely you are going to a famous blogger if you are not already 😉 Cheers!
Pretty! This was an extremely wonderful post. Thank you for providing this information.
Hi there are using WordPress for your blog platform? I’m new to the blog world but I’m trying to get started and create my own. Do you need any coding knowledge to make your own blog? Any help would be greatly appreciated!
Sweet blog! I found it while browsing on Yahoo News. Do you have any tips on how to get listed in Yahoo News? I’ve been trying for a while but I never seem to get there! Many thanks
It’s really a nice and helpful piece of information. I’m satisfied that you simply shared this helpful info with us. Please stay us informed like this. Thank you for sharing.
Hi there i am kavin, its my first time to commenting anywhere, when i read this piece of writing i thought i could also make comment due to this brilliant post.
My family members all the time say that I am wasting my time here at net, but I know I am getting knowledge daily by reading such pleasant articles.
What’s up, yes this article is in fact good and I have learned lot of things from it regarding blogging. thanks.
This piece of writing will help the internet people for building up new blog or even a blog from start to end.
We stumbled over here from a different website and thought I might as well check things out. I like what I see so now i am following you. Look forward to looking over your web page for a second time.
Saved as a favorite, I really like your site!
Howdy, i read your blog occasionally and i own a similar one and i was just wondering if you get a lot of spam responses? If so how do you stop it, any plugin or anything you can advise? I get so much lately it’s driving me insane so any help is very much appreciated.
Hi! I just wanted to ask if you ever have any trouble with hackers? My last blog (wordpress) was hacked and I ended up losing many months of hard work due to no data backup. Do you have any solutions to protect against hackers?
Hi there! I’m at work browsing your blog from my new iphone! Just wanted to say I love reading your blog and look forward to all your posts! Keep up the fantastic work!
I love your blog.. very nice colors & theme. Did you create this website yourself or did you hire someone to do it for you? Plz reply as I’m looking to design my own blog and would like to know where u got this from. thanks a lot
If some one needs to be updated with most recent technologies afterward he must be visit this web site and be up to date everyday.
Have you ever thought about creating an e-book or guest authoring on other sites? I have a blog centered on the same information you discuss and would really like to have you share some stories/information. I know my subscribers would value your work. If you are even remotely interested, feel free to send me an e mail.
I do accept as true with all the concepts you have presented for your post. They are very convincing and will definitely work. Still, the posts are too brief for novices. May you please extend them a bit from next time? Thank you for the post.
Fantastic goods from you, man. I’ve understand your stuff previous to and you’re just too wonderful. I really like what you’ve acquired here, really like what you’re stating and the way in which you say it. You make it entertaining and you still take care of to keep it smart. I cant wait to read far more from you. This is actually a great site.
Your insights have broadened my horizons.
Thanks I have recently been looking for info about this subject for a while and yours is the greatest I have discovered so far However what in regards to the bottom line Are you certain in regards to the supply
canadian pharcharmy navigate to this website
generic cialis canada pharmacy canadianphrmacy23.com Canadian Pharmacy Online to Usa
wonderful issues altogether, you just gained a emblem new reader. What could you suggest in regards to your post that you simply made a few days ago? Any positive?
canadian pharmacy viagra cialis canadian pharmacy
cialis from usa pharmacy description
It’s an remarkable piece of writing designed for all the web users; they will take benefit from it I am sure.
Hello! This is my first visit to your blog! We are a collection of volunteers and starting a new initiative in a community in the same niche. Your blog provided us valuable information to work on. You have done a outstanding job!
These are actually impressive ideas in regarding blogging. You have touched some pleasant points here. Any way keep up wrinting.
Spot on with this write-up, I truly believe this web site needs a lot more attention. I’ll probably be back again to read more, thanks for the information!
4l0d1o
Yes! Finally something about %keyword1%.
I was able to find good information from your articles.
No matter if some one searches for his required thing, thus he/she wants to be available that in detail, so that thing is maintained over here.
hi!,I really like your writing so so much! percentage we keep up a correspondence more approximately your post on AOL? I need an expert in this area to solve my problem. May be that is you! Looking forward to peer you.
Hello there! This is my 1st comment here so I just wanted to give a quick shout out and tell you I genuinely enjoy reading through your articles. Can you suggest any other blogs/websites/forums that deal with the same subjects? Thanks!
What’s up everyone, it’s my first go to see at this site, and piece of writing is in fact fruitful for me, keep up posting these articles or reviews.
I love your blog.. very nice colors & theme. Did you create this website yourself or did you hire someone to do it for you? Plz answer back as I’m looking to design my own blog and would like to know where u got this from. thank you
Yes! Finally something about %keyword1%.
Excellent blog here! Also your site loads up fast! What host are you using? Can I get your affiliate link to your host? I wish my website loaded up as fast as yours lol
I am curious to find out what blog system you are utilizing? I’m experiencing some minor security problems with my latest website and I would like to find something more safeguarded. Do you have any solutions?
I wanted to thank you for this good read!! I definitely enjoyed every little bit of it. I have you book-marked to check out new stuff you post
Hi, its good post about media print, we all understand media is a great source of information.
It’s remarkable in favor of me to have a website, which is beneficial for my experience. thanks admin
As the admin of this website is working, no uncertainty very soon it will be famous, due to its quality contents.
Thank you for the auspicious writeup. It in fact was a amusement account it. Look advanced to far added agreeable from you! By the way, how can we communicate?
When someone writes an piece of writing he/she maintains the plan of a user in his/her mind that how a user can understand it. Thus that’s why this post is amazing. Thanks!
No matter if some one searches for his required thing, thus he/she needs to be available that in detail, so that thing is maintained over here.
I’m impressed, I must say. Rarely do I encounter a blog that’s equally educative and entertaining, and let me tell you, you have hit the nail on the head. The issue is something not enough people are speaking intelligently about. I’m very happy that I stumbled across this in my search for something concerning this.
Aw, this was a really nice post. Finding the time and actual effort to create a very good article but what can I say I put things off a lot and never seem to get anything done.
Heya i’m for the first time here. I came across this board and I find It truly useful & it helped me out a lot. I hope to give something back and help others like you helped me.
This resource is incredible. The splendid data shows the distributer’s earnestness. I’m dumbfounded and envision additional such amazing posts.
Currently it seems like Drupal is the best blogging platform out there right now. (from what I’ve read) Is that what you’re using on your blog?
WOW just what I was searching for. Came here by searching for %keyword%
Wow, that’s what I was seeking for, what a information! present here at this website, thanks admin of this site.
Pretty great post. I simply stumbled upon your blog and wanted to mention that I have really enjoyed browsing your blog posts. In any case I’ll be subscribing in your feed and I am hoping you write again soon!
It is appropriate time to make some plans for the future and it is time to be happy. I have read this post and if I could I want to suggest you few interesting things or advice. Perhaps you could write next articles referring to this article. I wish to read more things about it!
Everything is very open with a precise explanation of the issues. It was really informative. Your website is very useful. Thanks for sharing!
Howdy, i read your blog occasionally and i own a similar one and i was just wondering if you get a lot of spam responses? If so how do you prevent it, any plugin or anything you can advise? I get so much lately it’s driving me insane so any help is very much appreciated.
Hi there mates, good article and pleasant arguments commented here, I am actually enjoying by these.
It’s not my first time to visit this site, i am visiting this web site dailly and take pleasant data from here daily.
What’s Taking place i’m new to this, I stumbled upon this I have found It positively helpful and it has helped me out loads. I hope to give a contribution & aid other users like its helped me. Good job.
Appreciate the recommendation. Will try it out.
Hey I know this is off topic but I was wondering if you knew of any widgets I could add to my blog that automatically tweet my newest twitter updates. I’ve been looking for a plug-in like this for quite some time and was hoping maybe you would have some experience with something like this. Please let me know if you run into anything. I truly enjoy reading your blog and I look forward to your new updates.
Pretty section of content. I simply stumbled upon your weblog and in accession capital to claim that I acquire in fact enjoyed account your blog posts. Any way I’ll be subscribing for your augment or even I achievement you access persistently rapidly.
This post is really a good one it helps new internet people, who are wishing for blogging.
I was recommended this website by my cousin I am not sure whether this post is written by him as nobody else know such detailed about my trouble You are amazing Thanks
This page is fabulous. The brilliant information reveals the publisher’s interest. I’m awestruck and envision further such mind blowing presents.
This website is amazing. The excellent content demonstrates the creator’s passion. I’m in disbelief and hope to see more of this incredible content.
토토꽁머니커뮤니티✔️꽁머니❂【꽁타 ggongta.com✔️】승인없는꽁머니사이트ↂ승인전화없는가입머니사이트⟉파워볼꽁머니공원✓꽁머니환전사설토토추천‚꽁머니이벤트업체ፘ바카라꽁머니메이저💰△ggongta.com△꽁타💰
Giriş Adresimiz İçin Tıklayın !
I simply could not leave your website prior to suggesting that I extremely loved the usual information an individual supply on your visitors? Is gonna be again steadily in order to inspect new posts.
Hey there would you mind stating which blog platform you’re working with? I’m looking to start my own blog in the near future but I’m having a difficult time choosing between BlogEngine/Wordpress/B2evolution and Drupal. The reason I ask is because your design and style seems different then most blogs and I’m looking for something completely unique. P.S My apologies for getting off-topic but I had to ask!
Appreciation to my father who shared with me concerning this website, this weblog is actually awesome.
This post provides clear idea in favor of the new users of blogging, that truly how to do blogging and site-building.
Hi there, I wish for to subscribe for this webpage to take most up-to-date updates, so where can i do it please assist.
Your posts are a great source of inspiration.
Ethical considerations surrounding generic plaquenil, especially in clinical trials, shed light on the importance of consent and transparency. Participants and the public must be informed about the potential risks and benefits, ensuring that the pursuit of medical advancements respects individual rights and societal norms.
Wow amazing blog layout How long have you been blogging for you made blogging look easy The overall look of your web site is magnificent as well as the content
Слоты и онлайн-игры в казино способны разнообразить жизнь человека. Важно только правильно выбрать площадку — она должна быстро и честно выплачивать выигрыши, надежно хранить персональные данные клиентов, предлагать большой ассортимент развлечений и интересную бонусную программу. Важную роль играют также наличие адаптированной мобильной версии и приложений. https://enic-kazakhstan.kz/
Советуем посетить сайт https://drova-smolensk.ru/
Также не забудьте добавить сайт в закладки: https://drova-smolensk.ru/
Советуем посетить сайт https://arenda-legkovyh-pricepov.ru/
Также не забудьте добавить сайт в закладки: https://arenda-legkovyh-pricepov.ru/
Советуем посетить сайт https://podveski-remont.ru/
Также не забудьте добавить сайт в закладки: https://podveski-remont.ru/
Советуем посетить сайт https://admlihoslavl.ru/
Также не забудьте добавить сайт в закладки: https://admlihoslavl.ru/
Советуем посетить сайт https://elegos.ru/
Также не забудьте добавить сайт в закладки: https://elegos.ru/
08wky1
bq9hh2
Your blog is a beacon of light in the often murky waters of online content. Your thoughtful analysis and insightful commentary never fail to leave a lasting impression. Keep up the amazing work!
Советуем посетить сайт https://100sm.ru/
Также не забудьте добавить сайт в закладки: https://100sm.ru/
Советуем посетить сайт https://club-columb.ru/
Также не забудьте добавить сайт в закладки: https://club-columb.ru/
Советуем посетить сайт https://avtomaxi22.ru/
Также не забудьте добавить сайт в закладки: https://avtomaxi22.ru/
I would like to thank you for the efforts you have put in writing this blog. I’m hoping to view the same high-grade blog posts from you in the future as well. In fact, your creative writing abilities has motivated me to get my very own website now 😉
Simply want to say your article is as astonishing. The clearness in your post is simply excellent and i can assume you are an expert on this subject. Well with your permission allow me to grab your RSS feed to keep up to date with forthcoming post. Thanks a million and please keep up the rewarding work.
I think what you postedtypedthink what you postedwrotethink what you postedtypedsaidthink what you postedtypedsaidWhat you postedtyped was very logicala ton of sense. But, what about this?think about this, what if you were to write a killer headlinetitle?content?wrote a catchier title? I ain’t saying your content isn’t good.ain’t saying your content isn’t gooddon’t want to tell you how to run your blog, but what if you added a titlesomethingheadlinetitle that grabbed a person’s attention?maybe get a person’s attention?want more? I mean %BLOG_TITLE% is a little plain. You ought to look at Yahoo’s home page and watch how they createwrite post headlines to get viewers to click. You might add a related video or a related pic or two to get readers interested about what you’ve written. Just my opinion, it might bring your postsblog a little livelier.
This is my first time visit at here and i am in fact impressed to read all at alone place.
Simply want to say your article is as astonishing. The clearness in your publish is simply nice and i can think you are a professional in this subject. Well together with your permission allow me to seize your RSS feed to stay up to date with forthcoming post. Thank you one million and please keep up the gratifying work.
If some one desires expert view concerning blogging and site-building then i suggest him/her to pay a visit this website, Keep up the pleasant job.
Appreciate the recommendation. Will try it out.
Hi there great blog! Does running a blog similar to this take a lot of work? I have no knowledge of programming but I was hoping to start my own blog soon. Anyway, if you have any recommendations or tips for new blog owners please share. I know this is off topic nevertheless I just needed to ask. Thanks!
You really make it seem so easy with your presentation however I in finding this topic to be really something which I think I would never understand. It kind of feels too complicated and very extensive for me. I am looking forward for your next submit, I will try to get the hang of it!
Hi there would you mind stating which blog platform you’re working with? I’m looking to start my own blog in the near future but I’m having a difficult time making a decision between BlogEngine/Wordpress/B2evolution and Drupal. The reason I ask is because your design seems different then most blogs and I’m looking for something completely unique. P.S My apologies for getting off-topic but I had to ask!
Hello there! I could have sworn I’ve been to this website before but after going through a few of the posts I realized it’s new to me. Anyhow, I’m definitely happy I found it and I’ll be bookmarking it and checking back frequently!
When I originally commented I seem to have clicked the -Notify me when new comments are added- checkbox and now every time a comment is added I get four emails with the same comment. Perhaps there is a means you can remove me from that service? Thanks a lot!
Thank you, I have recently been searching for information approximately this topic for ages and yours is the best I have came upon so far. However, what concerning the conclusion? Are you positive about the source?
Hey there, I think your blog might be having browser compatibility issues. When I look at your blog site in Safari, it looks fine but when opening in Internet Explorer, it has some overlapping. I just wanted to give you a quick heads up! Other then that, superb blog!
Thanks for a marvelous posting! I actually enjoyed reading it, you will be a great author.I will be sure to bookmark your blog and will come back from now on. I want to encourage you to ultimately continue your great posts, have a nice morning!
I know this if off topic but I’m looking into starting my own blog and was wondering what all is required to get set up? I’m assuming having a blog like yours would cost a pretty penny? I’m not very internet savvy so I’m not 100% sure. Any tips or advice would be greatly appreciated. Thanks
Wow that was odd. I just wrote an really long comment but after I clicked submit my comment didn’t show up. Grrrr… well I’m not writing all that over again. Anyways, just wanted to say fantastic blog!
Hi there I am so excited I found your website, I really found you by error, while I was browsing on Digg for something else, Regardless I am here now and would just like to say cheers for a fantastic post and a all round exciting blog (I also love the theme/design), I dont have time to go through it all at the minute but I have book-marked it and also added in your RSS feeds, so when I have time I will be back to read a great deal more, Please do keep up the superb b.
Hello there, just became aware of your blog through Google, and found that it is really informative. I’m gonna watch out for brussels. I will appreciate if you continue this in future. Lots of people will be benefited from your writing. Cheers!
Откройте дверь к новому пониманию человеческой природы https://batmanapollo.ru/%D1%81%D0%BF%D0%B8%D1%81%D0%BE%D0%BA-%D0%B7%D0%B0%D0%BF%D0%B8%D1%81%D0%B5%D0%B9-%D0%BE%D0%B1%D0%BD%D0%BE%D0%B2%D0%BB%D1%8F%D0%B5%D0%BC%D1%8B%D0%B9/ https://batmanapollo.ru/%D1%81%D0%BF%D0%B8%D1%81%D0%BE%D0%BA-%D0%B7%D0%B0%D0%BF%D0%B8%D1%81%D0%B5%D0%B9-%D0%BE%D0%B1%D0%BD%D0%BE%D0%B2%D0%BB%D1%8F%D0%B5%D0%BC%D1%8B%D0%B9/ Разгадайте загадки человеческого поведения с помощью этого списка статей Проникните в глубины своего “Я” с помощью этих глубоких психологических статей
The potential use of stromectol in COVID-19 treatment has sparked interest in exploring its antiviral properties and mechanism of action. Researchers are investigating its ability to inhibit viral replication and modulate the host immune response to determine its effectiveness against SARS-CoV-2. buy stromectol 3 mg
Советуем посетить сайт https://softnewsportal.ru/
Также не забудьте добавить сайт в закладки: https://softnewsportal.ru/
Советуем посетить сайт https://gulliverauto.ru/
Также не забудьте добавить сайт в закладки: https://gulliverauto.ru/
Your blog is a testament to your dedication to your craft. Your commitment to excellence is evident in every aspect of your writing. Thank you for being such a positive influence in the online community.
Советуем посетить сайт https://doutuapse.ru/
Также не забудьте добавить сайт в закладки: https://doutuapse.ru/
Советуем посетить сайт https://russkiy-spaniel.ru/
Также не забудьте добавить сайт в закладки: https://russkiy-spaniel.ru/
Советуем посетить сайт https://stroydvor89.ru/
Также не забудьте добавить сайт в закладки: https://stroydvor89.ru/
We recommend visiting the website https://realskinbeauty.com/.
Also, don’t forget to bookmark the site: https://realskinbeauty.com/
We recommend visiting the website https://skinsoulbeauty.com/.
Also, don’t forget to bookmark the site: https://skinsoulbeauty.com/
Magnificent beat ! I would like to apprentice at the
same time as you amend your site, how can i subscribe for a weblog site?
The account aided me a appropriate deal. I had been tiny bit acquainted
of this your broadcast provided vibrant transparent concept
We recommend visiting the website https://quotablemoments1.blogspot.com/2024/03/embracing-lifes-wisdom-how-quotes-can.html.
Also, don’t forget to bookmark the site: https://quotablemoments1.blogspot.com/2024/03/embracing-lifes-wisdom-how-quotes-can.html
We recommend visiting the website https://wisdominwords123.blogspot.com/2024/03/unlocking-lifes-treasures-timeless.html.
Also, don’t forget to bookmark the site: https://wisdominwords123.blogspot.com/2024/03/unlocking-lifes-treasures-timeless.html
Attractive section of content I just stumbled upon your blog and in accession capital to assert that I get actually enjoyed account your blog posts Anyway I will be subscribing to your augment and even I achievement you access consistently fast
We recommend visiting the website https://wisdominwords123.blogspot.com/2024/03/echoes-of-wisdom.html.
Also, don’t forget to bookmark the site: https://wisdominwords123.blogspot.com/2024/03/echoes-of-wisdom.html
We recommend visiting the website https://telegra.ph/The-Radiance-of-Positivity-Exploring-the-Power-of-Positive-Quotes-03-31.
Also, don’t forget to bookmark the site: https://telegra.ph/The-Radiance-of-Positivity-Exploring-the-Power-of-Positive-Quotes-03-31
We recommend visiting the website https://telegra.ph/The-Craft-of-Achievement-Finding-Inspiration-in-Work-Quotes-03-31.
Also, don’t forget to bookmark the site: https://telegra.ph/The-Craft-of-Achievement-Finding-Inspiration-in-Work-Quotes-03-31
We recommend visiting the website https://telegra.ph/Sculpting-Success-How-Quotes-Can-Shape-Our-Aspirations-03-31.
Also, don’t forget to bookmark the site: https://telegra.ph/Sculpting-Success-How-Quotes-Can-Shape-Our-Aspirations-03-31
We recommend visiting the website https://telegra.ph/The-Bonds-We-Cherish-Celebrating-Connections-Through-Friendship-Quotes-03-31.
Also, don’t forget to bookmark the site: https://telegra.ph/The-Bonds-We-Cherish-Celebrating-Connections-Through-Friendship-Quotes-03-31
I was recommended this website by my cousin I am not sure whether this post is written by him as nobody else know such detailed about my difficulty You are wonderful Thanks
– Embark on a journey of relaxation with our exotic THCa hemp flower, starting at $50 per ounce on CallmeTHCa.com.
We recommend visiting the website https://telegra.ph/Lifes-Mosaic-Understanding-the-Big-Picture-Through-Quotes-03-31.
Also, don’t forget to bookmark the site: https://telegra.ph/Lifes-Mosaic-Understanding-the-Big-Picture-Through-Quotes-03-31
I loved as much as you will receive carried out right here The sketch is attractive your authored material stylish nonetheless you command get got an impatience over that you wish be delivering the following unwell unquestionably come more formerly again since exactly the same nearly a lot often inside case you shield this hike
We recommend visiting the website https://telegra.ph/The-Drive-Within-Unlocking-Potential-with-Motivational-Quotes-03-31.
Also, don’t forget to bookmark the site: https://telegra.ph/The-Drive-Within-Unlocking-Potential-with-Motivational-Quotes-03-31
We recommend visiting the website https://telegra.ph/Whispers-of-the-Heart-Exploring-the-Essence-of-Love-Through-Quotes-03-31.
Also, don’t forget to bookmark the site: https://telegra.ph/Whispers-of-the-Heart-Exploring-the-Essence-of-Love-Through-Quotes-03-31
Мы рекомендуем посетить веб-сайт https://telegra.ph/Luchshie-prikormki-dlya-lovli-shchuki-v-2024-godu-03-31.
Кроме того, не забудьте добавить сайт в закладки: https://telegra.ph/Luchshie-prikormki-dlya-lovli-shchuki-v-2024-godu-03-31
Мы рекомендуем посетить веб-сайт https://telegra.ph/Luchshie-internet-magaziny-rybolovnyh-snastej-03-31.
Кроме того, не забудьте добавить сайт в закладки: https://telegra.ph/Luchshie-internet-magaziny-rybolovnyh-snastej-03-31
Мы рекомендуем посетить веб-сайт https://telegra.ph/Uspeh-na-konce-udochki-kak-vybrat-i-ispolzovat-kachestvennoe-rybolovnoe-oborudovanie-03-31.
Кроме того, не забудьте добавить сайт в закладки: https://telegra.ph/Uspeh-na-konce-udochki-kak-vybrat-i-ispolzovat-kachestvennoe-rybolovnoe-oborudovanie-03-31
Мы рекомендуем посетить веб-сайт https://telegra.ph/Instrumenty-dlya-udovolstviya-pochemu-kachestvennoe-rybolovnoe-oborudovanie—zalog-uspeshnoj-i-komfortnoj-rybalki-03-31.
Кроме того, не забудьте добавить сайт в закладки: https://telegra.ph/Instrumenty-dlya-udovolstviya-pochemu-kachestvennoe-rybolovnoe-oborudovanie—zalog-uspeshnoj-i-komfortnoj-rybalki-03-31
Мы рекомендуем посетить веб-сайт https://telegra.ph/Sekrety-uspeshnogo-ulova-znachenie-pravilnogo-vybora-i-ispolzovaniya-oborudovaniya-pri-rybalke-03-31.
Кроме того, не забудьте добавить сайт в закладки: https://telegra.ph/Sekrety-uspeshnogo-ulova-znachenie-pravilnogo-vybora-i-ispolzovaniya-oborudovaniya-pri-rybalke-03-31
You have a way of making even the most complex topics accessible. Thank you.
Мы рекомендуем посетить веб-сайт https://telegra.ph/Na-rybalku-s-uverennostyu-kak-vybrat-kachestvennoe-oborudovanie-dlya-uspeshnoj-rybalki-03-31.
Кроме того, не забудьте добавить сайт в закладки: https://telegra.ph/Na-rybalku-s-uverennostyu-kak-vybrat-kachestvennoe-oborudovanie-dlya-uspeshnoj-rybalki-03-31
Мы рекомендуем посетить веб-сайт https://telegra.ph/Rybachok-vsyo-neobhodimoe-dlya-rybolova-03-31.
Кроме того, не забудьте добавить сайт в закладки: https://telegra.ph/Rybachok-vsyo-neobhodimoe-dlya-rybolova-03-31
Мы рекомендуем посетить веб-сайт https://telegra.ph/Osnovnye-principy-udachnoj-rybalki-03-31.
Кроме того, не забудьте добавить сайт в закладки: https://telegra.ph/Osnovnye-principy-udachnoj-rybalki-03-31
hiI like your writing so much share we be in contact more approximately your article on AOL I need a specialist in this area to resolve my problem Maybe that is you Looking ahead to see you
Мы рекомендуем посетить веб-сайт https://telegra.ph/CHto-neobhodimo-vzyat-s-soboj-na-rybalku-03-31.
Кроме того, не забудьте добавить сайт в закладки: https://telegra.ph/CHto-neobhodimo-vzyat-s-soboj-na-rybalku-03-31
Мы рекомендуем посетить веб-сайт https://telegra.ph/Obzor-populyarnyh-pnevmaticheskih-pistoletov-sovety-po-vyboru-03-31.
Кроме того, не забудьте добавить сайт в закладки: https://telegra.ph/Obzor-populyarnyh-pnevmaticheskih-pistoletov-sovety-po-vyboru-03-31
Мы рекомендуем посетить веб-сайт https://softnewsportal.ru/.
Кроме того, не забудьте добавить сайт в закладки: https://softnewsportal.ru/
I loved as much as you will receive carried out right here The sketch is attractive your authored material stylish nonetheless you command get got an impatience over that you wish be delivering the following unwell unquestionably come more formerly again since exactly the same nearly a lot often inside case you shield this hike온라인카지노1
Мы рекомендуем посетить веб-сайт https://doutuapse.ru/.
Кроме того, не забудьте добавить сайт в закладки: https://doutuapse.ru/
I have been surfing online more than 3 hours today yet I never found any interesting article like yours It is pretty worth enough for me In my opinion if all web owners and bloggers made good content as you did the web will be much more useful than ever before
Мы рекомендуем посетить веб-сайт https://telegra.ph/Internet-magazin-Rybachok-Vash-provodnik-v-mire-rybolovstva-04-09-2.
Кроме того, не забудьте добавить сайт в закладки: https://telegra.ph/Internet-magazin-Rybachok-Vash-provodnik-v-mire-rybolovstva-04-09-2
Мы рекомендуем посетить веб-сайт https://telegra.ph/Internet-magazin-Rybachok-Vash-nadezhnyj-pomoshchnik-v-mire-rybolovstva-04-09.
Кроме того, не забудьте добавить сайт в закладки: https://telegra.ph/Internet-magazin-Rybachok-Vash-nadezhnyj-pomoshchnik-v-mire-rybolovstva-04-09
Quality articles is the key to be a focus for the viewers to visit the website, that’s what this web site is providing.
obviously like your website but you need to test the spelling on quite a few of your posts Several of them are rife with spelling problems and I to find it very troublesome to inform the reality on the other hand Ill certainly come back again
I am in fact glad to read this weblog posts which consists of plenty of useful data, thanks for providing these information.
Мы рекомендуем посетить веб-сайт https://telegra.ph/Internet-magazin-Rybachok-Mesto-gde-rybalka-nachinaetsya-s-vybora-snaryazheniya-04-09.
Кроме того, не забудьте добавить сайт в закладки: https://telegra.ph/Internet-magazin-Rybachok-Mesto-gde-rybalka-nachinaetsya-s-vybora-snaryazheniya-04-09
What i do not realize is in fact how you are no longer actually much more wellfavored than you might be right now Youre very intelligent You recognize thus considerably in relation to this topic made me in my view believe it from numerous numerous angles Its like men and women are not fascinated until it is one thing to do with Lady gaga Your own stuffs excellent All the time handle it up
Мы рекомендуем посетить веб-сайт https://telegra.ph/Internet-magazin-Rybachok-Vash-provodnik-v-mire-rybolovstva-04-09.
Кроме того, не забудьте добавить сайт в закладки: https://telegra.ph/Internet-magazin-Rybachok-Vash-provodnik-v-mire-rybolovstva-04-09
Your writing is not only informative but also incredibly inspiring. You have a knack for sparking curiosity and encouraging critical thinking. Thank you for being such a positive influence!
Мы рекомендуем посетить веб-сайт https://telegra.ph/Internet-magazin-Rybachok-Vash-nadezhnyj-pomoshchnik-v-mire-rybolovstva-04-09-2.
Кроме того, не забудьте добавить сайт в закладки: https://telegra.ph/Internet-magazin-Rybachok-Vash-nadezhnyj-pomoshchnik-v-mire-rybolovstva-04-09-2
Мы рекомендуем посетить веб-сайт https://telegra.ph/Internet-magazin-Rybachok-Vash-vernyj-sputnik-v-mire-rybnoj-lovli-04-09.
Кроме того, не забудьте добавить сайт в закладки: https://telegra.ph/Internet-magazin-Rybachok-Vash-vernyj-sputnik-v-mire-rybnoj-lovli-04-09
Мы рекомендуем посетить веб-сайт https://telegra.ph/Internet-magazin-Rybachok-Vash-nadezhnyj-pomoshchnik-v-mire-rybolovstva-04-09-3.
Кроме того, не забудьте добавить сайт в закладки: https://telegra.ph/Internet-magazin-Rybachok-Vash-nadezhnyj-pomoshchnik-v-mire-rybolovstva-04-09-3
Hi, i feel that i saw you visited my website so i got here to go back the want?.I am trying to find things to improve my site!I guess its ok to use some of your concepts!!
Hmm it appears like your site ate my first comment (it was extremely long) so I guess I’ll just sum it up what I submitted and say, I’m thoroughly enjoying your blog. I as well am an aspiring blog blogger but I’m still new to the whole thing. Do you have any suggestions for first-time blog writers? I’d definitely appreciate it.
of course like your website however you need to test the spelling on quite a few of your posts. Several of them are rife with spelling problems and I find it very bothersome to tell the truth on the other hand I will surely come back again.
Heya i’m for the first time here. I came across this board and I find It truly useful & it helped me out a lot. I hope to give something back and help others like you helped me.
Attractive section of content I just stumbled upon your blog and in accession capital to assert that I get actually enjoyed account your blog posts Anyway I will be subscribing to your augment and even I achievement you access consistently fast
Мы рекомендуем посетить веб-сайт https://telegra.ph/Internet-magazin-Rybachok-Vash-vernyj-sputnik-v-mire-rybnoj-lovli-04-09-2.
Кроме того, не забудьте добавить сайт в закладки: https://telegra.ph/Internet-magazin-Rybachok-Vash-vernyj-sputnik-v-mire-rybnoj-lovli-04-09-2
Мы рекомендуем посетить веб-сайт https://vektor-meh.ru//.
Кроме того, не забудьте добавить сайт в закладки: https://vektor-meh.ru/
Fantastic beat I would like to apprentice while you amend your web site how could i subscribe for a blog site The account helped me a acceptable deal I had been a little bit acquainted of this your broadcast offered bright clear concept
Мы рекомендуем посетить веб-сайт https://russkiy-spaniel.ru/.
Кроме того, не забудьте добавить сайт в закладки: https://russkiy-spaniel.ru/
Incredible! This blog looks exactly like my old one!
It’s on a entirely different subject but it has pretty much the same page layout
and design. Outstanding choice of colors!
Мы рекомендуем посетить веб-сайт https://stroydvor89.ru/.
Кроме того, не забудьте добавить сайт в закладки: https://stroydvor89.ru/
I couldn’t help but be enthralled with the basic information you offered about your visitors, so much so that I returned to your website to review and double-check recently published content.
Мы рекомендуем посетить веб-сайт https://magic-magnit.ru/.
Кроме того, не забудьте добавить сайт в закладки: https://magic-magnit.ru/
Wow, marvelous blog layout! How long have you ever been running a blog for?
you made running a blog look easy. The whole glance of your
website is fantastic, let alone the content material!
You can see similar here ecommerce
Wow, incredible blog format! How lengthy have you been running a blog for?
you made running a blog look easy. The overall look of
your web site is wonderful, let alone the content! You can see similar here sklep internetowy
Мы рекомендуем посетить веб-сайт https://kvest4x4.ru/.
Кроме того, не забудьте добавить сайт в закладки: https://kvest4x4.ru/
Мы рекомендуем посетить веб-сайт https://photo-res.ru/.
Кроме того, не забудьте добавить сайт в закладки: https://photo-res.ru/
Выбираете идеальный подарок или хотите преобразить свой мероприятие незабываемыми впечатлениями?
Советуем вам: Шары с гелием с доставкой недорого Москва
Рекомендуем добавить сайт http://carstvo-sharov.ru в закладки.
Мы рекомендуем посетить веб-сайт https://great-galaxy.ru/.
Кроме того, не забудьте добавить сайт в закладки: https://great-galaxy.ru/
Мы рекомендуем посетить веб-сайт https://90sad.ru/.
Кроме того, не забудьте добавить сайт в закладки: https://90sad.ru/
Мы рекомендуем посетить веб-сайт https://kmc-ia.ru/.
Кроме того, не забудьте добавить сайт в закладки: https://kmc-ia.ru/
It’s my first time on your blog, and I have to admit that I’m amazed at how much research you did to produce such a fantastic post. A important portion was built with the help of someone.
Мы рекомендуем посетить веб-сайт https://thebachelor.ru/.
Кроме того, не забудьте добавить сайт в закладки: https://thebachelor.ru/
Мы рекомендуем посетить веб-сайт https://telegra.ph/Internet-magazin-Rybachok-vash-nadezhnyj-partner-v-mire-rybalki-04-15.
Кроме того, не забудьте добавить сайт в закладки: https://telegra.ph/Internet-magazin-Rybachok-vash-nadezhnyj-partner-v-mire-rybalki-04-15
Wow, marvelous weblog layout! How lengthy have you
been running a blog for? you make running a blog
look easy. The total glance of your web site is excellent, let alone the content material!
You can see similar here dobry sklep
Мы рекомендуем посетить веб-сайт https://kreativ-didaktika.ru/.
Кроме того, не забудьте добавить сайт в закладки: https://kreativ-didaktika.ru/
Wow, wonderful weblog structure! How long have you ever been blogging
for? you made running a blog look easy. The entire glance of your web site is
great, as smartly as the content! You can see similar here
dobry sklep
Мы рекомендуем посетить веб-сайт https://cultureinthecity.ru/.
Кроме того, не забудьте добавить сайт в закладки: https://cultureinthecity.ru/
Мы рекомендуем посетить веб-сайт http://vanillarp.ru/.
Кроме того, не забудьте добавить сайт в закладки: http://vanillarp.ru/
Its like you read my mind You appear to know so much about this like you wrote the book in it or something I think that you can do with a few pics to drive the message home a little bit but other than that this is fantastic blog A great read Ill certainly be back
Мы рекомендуем посетить веб-сайт https://urkarl.ru/.
Кроме того, не забудьте добавить сайт в закладки: https://urkarl.ru/
I seriously love your blog.. Pleasant colors & theme.
Did you develop this amazing site yourself? Please reply back as I’m
wanting to create my own personal site and want to know where you got this from or what the theme is
named. Kudos!
Hi to all, as I am truly keen of reading this blog’s post to be updated regularly. It consists of good data.
Great info. Lucky me I discovered your website by accident (stumbleupon). I have book marked it for later!
An impressive share! I have just forwarded this onto a coworker who was doing a little research on this. And he in fact bought me breakfast because I discovered it for him… lol. So let me reword this…. Thank YOU for the meal!! But yeah, thanx for spending the time to discuss this issue here on your web site.
I have been surfing online more than three hours nowadays, yet I never found any fascinating article like yours. It’s pretty value enough for me. In my opinion, if all webmasters and bloggers made good content as you did, the internet will be much more useful than ever before.
WOW just what I was searching for. Came here by searching for %keyword%
Hi there, I found your blog via Google whilst searching for a similar topic, your site got here up, it appears good. I have bookmarked it in my google bookmarks.
Hi there to all, the contents present at this website are really awesome for people experience, well, keep up the nice work fellows.
Howdy! I could have sworn I’ve been to this web site before but after browsing through a few of the posts I realized it’s new to me. Anyhow, I’m definitely happy I found it and I’ll be bookmarking it and checking back regularly!
Hi there! I could have sworn I’ve been to this web site before but after going through a few of the posts I realized it’s new to me. Anyways, I’m definitely happy I found it and I’ll be bookmarking it and checking back regularly!
Informative article, exactly what I wanted to find.
I am truly pleased to read this blog posts which contains plenty of helpful data, thanks for providing these data.
Hey there! Would you mind if I share your blog with my facebook group? There’s a lot of people that I think would really enjoy your content. Please let me know. Thanks
Hey! Quick question that’s completely off topic. Do you know how to make your site mobile friendly? My blog looks weird when viewing from my iphone 4. I’m trying to find a theme or plugin that might be able to correct this problem. If you have any suggestions, please share. Thanks!
My brother suggested I would possibly like this blog. He was totally right. This post actually made my day. You cann’t consider just how so much time I had spent for this information! Thank you!
My brother suggested I might like this website. He was totally right. This post actually made my day. You cann’t imagine just how much time I had spent for this information! Thanks!
It is perfect time to make a few plans for the longer term and it is time to be happy. I have read this publish and if I may I want to suggest you few interesting things or advice. Perhaps you could write next articles relating to this article. I want to read more things approximately it!
I am really loving the theme/design of your web site. Do you ever run into any web browser compatibility problems? A number of my blog audience have complained about my blog not operating correctly in Explorer but looks great in Opera. Do you have any solutions to help fix this issue?
I got this site from my pal who told me concerning this site and now this time I am visiting this site and reading very informative posts here.
Hmm it seems like your website ate my first comment (it was extremely long) so I guess I’ll just sum it up what I had written and say, I’m thoroughly enjoying your blog. I as well am an aspiring blog blogger but I’m still new to the whole thing. Do you have any points for first-time blog writers? I’d certainly appreciate it.
You really make it seem so easy with your presentation however I find this topic to be really something which I feel I might never understand. It sort of feels too complicated and very wide for me. I am taking a look forward for your next publish, I will try to get the hang of it!
of course like your web-site however you need to test the spelling on quite a few of your posts. Several of them are rife with spelling problems and I find it very bothersome to tell the truth then again I will certainly come back again.
Superb blog! Do you have any tips and hints for aspiring writers? I’m planning to start my own site soon but I’m a little lost on everything. Would you suggest starting with a free platform like WordPress or go for a paid option? There are so many choices out there that I’m totally confused .. Any ideas? Kudos!
I pay a visit everyday some web pages and information sites to read articles, but this webpage provides quality based content.
I was captivated by your work just as much as you were. Your sketch is tasteful and your written material is stylish. However, you seem to be anxious that you will be delivering something questionable in the near future. I agree that you will likely resolve this issue soon and return to your usual high standards.
Мы рекомендуем посетить веб-сайт https://yarus-kkt.ru/.
Кроме того, не забудьте добавить сайт в закладки: https://yarus-kkt.ru/
Мы рекомендуем посетить веб-сайт https://imgtube.ru/.
Кроме того, не забудьте добавить сайт в закладки: https://imgtube.ru/
Мы рекомендуем посетить веб-сайт https://svetnadegda.ru/.
Кроме того, не забудьте добавить сайт в закладки: https://svetnadegda.ru/
vidalista 60
For years, the Duke and Duchess of Edinburgh slid under the radar when it came to the royal family. Emma Mackenzie charts how the Queen subtly brought her youngest son into the fold following the departure of the Sussexes and the scandals surrounding Prince Andrew Charles has been the UK’s head of state since 8 September 2022, as the oldest person to become British monarch when he succeeded his mother, the late Queen Elizabeth II. Only those born into the Royal Family can be in line to the throne. Those who marry a royal also become a member of the Royal Family. Crown Princess Mary of Denmark marked a milestone birthday in February: She turned 50. The Royal House of Denmark released this stunning official birthday portrait for the occasion.
https://deanldge852956.blogozz.com/22001083/list-of-poker-combinations
While many businesses use some sort of social media management tool, most of these baseline scheduling tools don’t go far enough to provide the in-depth metrics and data points that social media analytics tools can deliver. You have to apply to be part of CrowdTangle’s Academics & Researchers program to gain access to the CrowdTangle interface and API, as well as training and resources. Data mining is the analysis of large sets of data in order to derive trends, and data harvesting is the process of extracting data from online sources to then build analyses. While data mining focuses more on the analysis of data, data harvesting focuses on the collection of data. Despite playing such a fundamental role in performance and success, true social media analytics solutions still remain heavily underutilized. Many businesses are still failing to take advantage of these platforms, using only native tools that provide shallow performance metrics for each of their channels in isolation. These businesses miss out on a multitude of more in-depth metrics in addition to all of the data points and insights that are derived from contextualizing social media data across channels and industries.
Мы рекомендуем посетить веб-сайт https://tione.ru/.
Кроме того, не забудьте добавить сайт в закладки: https://tione.ru/
Мы рекомендуем посетить веб-сайт https://telegra.ph/Internet-magazin-Rybachok-vash-vybor-dlya-uspeshnoj-rybalki-04-15.
Кроме того, не забудьте добавить сайт в закладки: https://telegra.ph/Internet-magazin-Rybachok-vash-vybor-dlya-uspeshnoj-rybalki-04-15
Мы рекомендуем посетить веб-сайт https://telegra.ph/Internet-magazin-Rybachok-vash-nadezhnyj-partner-v-mire-rybalki-04-15-2.
Кроме того, не забудьте добавить сайт в закладки: https://telegra.ph/Internet-magazin-Rybachok-vash-nadezhnyj-partner-v-mire-rybalki-04-15-2
Мы рекомендуем посетить веб-сайт https://telegra.ph/Internet-magazin-Rybachok-vash-vybor-dlya-uspeshnoj-rybalki-04-15-2.
Кроме того, не забудьте добавить сайт в закладки: https://telegra.ph/Internet-magazin-Rybachok-vash-vybor-dlya-uspeshnoj-rybalki-04-15-2
mexican pharmacy: pharmacies in mexico that ship to usa – mexican border pharmacies shipping to usa
Мы рекомендуем посетить веб-сайт https://telegra.ph/Internet-magazin-Rybachok-vash-put-k-udachnoj-rybalke-04-15.
Кроме того, не забудьте добавить сайт в закладки: https://telegra.ph/Internet-magazin-Rybachok-vash-put-k-udachnoj-rybalke-04-15
Мы рекомендуем посетить веб-сайт https://telegra.ph/O-magazine-Rybachok-04-15.
Кроме того, не забудьте добавить сайт в закладки: https://telegra.ph/O-magazine-Rybachok-04-15
Мы рекомендуем посетить веб-сайт https://telegra.ph/Internet-magazin-Rybachok-vash-put-k-uspeshnoj-rybalke-04-15-2.
Кроме того, не забудьте добавить сайт в закладки: https://telegra.ph/Internet-magazin-Rybachok-vash-put-k-uspeshnoj-rybalke-04-15-2
Мы рекомендуем посетить веб-сайт https://telegra.ph/Internet-magazin-Rybachok-vash-nadezhnyj-partner-v-mire-rybnoj-lovli-04-15.
Кроме того, не забудьте добавить сайт в закладки: https://telegra.ph/Internet-magazin-Rybachok-vash-nadezhnyj-partner-v-mire-rybnoj-lovli-04-15
Мы рекомендуем посетить веб-сайт https://burger-kings.ru/.
Кроме того, не забудьте добавить сайт в закладки: https://burger-kings.ru/
Wow superb blog layout How long have you been blogging for you make blogging look easy The overall look of your site is magnificent as well as the content
Мы рекомендуем посетить веб-сайт http://voenoboz.ru/.
Кроме того, не забудьте добавить сайт в закладки: http://voenoboz.ru/
Мы рекомендуем посетить веб-сайт https://remonttermexov.ru/.
Кроме того, не забудьте добавить сайт в закладки: https://remonttermexov.ru/
Мы рекомендуем посетить веб-сайт https://lostfiilmtv.ru/.
Кроме того, не забудьте добавить сайт в закладки: https://lostfiilmtv.ru/
Мы рекомендуем посетить веб-сайт https://my-caffe.ru/.
Кроме того, не забудьте добавить сайт в закладки: https://my-caffe.ru/
Мы рекомендуем посетить веб-сайт https://adventime.ru/.
Кроме того, не забудьте добавить сайт в закладки: https://adventime.ru/
Can I get OTC options for macular degeneration treatment Buy clomid without prescription?
medicine in mexico pharmacies: Mexican Pharmacy Online – mexico pharmacies prescription drugs
Мы рекомендуем посетить веб-сайт https://ipodtouch3g.ru/.
Кроме того, не забудьте добавить сайт в закладки: https://ipodtouch3g.ru/
Мы рекомендуем посетить веб-сайт https://kaizen-tmz.ru/.
Кроме того, не забудьте добавить сайт в закладки: https://kaizen-tmz.ru/
Мы рекомендуем посетить веб-сайт для ознакомления с методами налоговой оптимизации ссылка.
Не пропустите возможность узнать больше о важности налогового аудита для вашего бизнеса, добавьте в закладки нашу страницу: ссылка
Мы рекомендуем посетить веб-сайт https://orenbash.ru/.
Кроме того, не забудьте добавить сайт в закладки: https://orenbash.ru/
What’s up, its nice post on the topic of media print, we all understand media is
a wonderful source of data.
Are there government-sponsored programs that provide assistance for HIV medications kamagra 100 oral jelly?
obviously like your website but you need to test the spelling on quite a few of your posts Several of them are rife with spelling problems and I to find it very troublesome to inform the reality on the other hand Ill certainly come back again
“Thank you for discussing the importance of carpet cleaning. At Teppich Reinigung München, we specialize in professional carpet cleaning services designed to remove stains, dirt, and allergens effectively. We’re dedicated to providing outstanding service to our clients in Munich.”
I was recommended this website by my cousin I am not sure whether this post is written by him as nobody else know such detailed about my difficulty You are wonderful Thanks
“Maintaining clean carpets is crucial for a hygienic living environment. Teppich Reinigung München offers reliable and effective carpet cleaning services in Munich. We’re committed to delivering exceptional results for our clients. Thank you for sharing these valuable insights!”
[토토사이트] 카지노커뮤니티 이용으로 먹튀검증 및 토토사이트 먹튀를 예방하세요.
vegas grand casino
vegas grand casino
Мы рекомендуем посетить веб-сайт https://kanunnikovao.ru/.
Кроме того, не забудьте добавить сайт в закладки: https://kanunnikovao.ru/
[토토사이트] 카지노커뮤니티 이용으로 먹튀검증 및 토토사이트 먹튀를 예방하세요.
Are generic medicines safe for long-term use vidalista 40 kopen?
Thank you for the auspicious writeup It in fact was a amusement account it Look advanced to more added agreeable from you By the way how could we communicate
Мы рекомендуем посетить веб-сайт https://church-bench.ru/.
Кроме того, не забудьте добавить сайт в закладки: https://church-bench.ru/
garilla казино
https://t.me/garillacasinobonus
“This article provides a comprehensive overview of the topic, offering valuable insights for both beginners and seasoned professionals in the field. I particularly appreciate the practical tips shared here, which can be easily implemented to enhance our approach. Looking forward to more informative content like this!”
Get my free NBA picks & NBA computer predictions daily throughout the regular season and playoffs. I’m your #1 source for the best NBA computer picks, along with my NBA premium picks. Note that there’s big difference between my premium picks and the computer projections. While this data is an excellent starting point, my premium picks offer the greatest accuracy by far, each with a full detailed analysis. In this case, a $187 bet on the Lakers would earn you a $100 profit if they won the game. A $20 bet on the Lakers would net you $10.70, whereas a $20 bet on OKC would net you $32.20. It tells you that the sportsbooks think the Lakers have a much better chance of winning the game, and they have priced the NBA game lines accordingly. Point Spread – This is a handicap system based on points, and works the same as handicaps in football betting. For example, a Miami Heat -2.5 point spread means they must win the game by 3 clear points or more for your bet to come in, with the opposite being the case for a +2.5 point spread. If the spread is a whole number and the team end up winning by or losing by exactly that number, then the bet becomes a push and your money is refunded.
https://rylanxmyi456667.ivasdesign.com/48280501/babu88-referral
It will be a few years before we truly know how teams performed in the draft — although there are some interesting ways to look at it — but public perception can lead to movement in Super Bowl odds. Odds by ESPN BET Kyle Terada-USA TODAY SportsNew future odds for next season’s MVP odds are out. Matthew Stafford is just outside the top 10 in favorites. He is +2000 to win MVP next season. In their most recent game, the Cardinals defeated the Philadelphia Eagles 35-31. Kyler Murray led the Cards with 232 yards on 25-of-31 passing (80.6%) for three touchdowns and one interception. He also carried the ball five times for 24 yards. James Conner totaled 128 rushing yards on 26 carries (4.9 yards per carry), scoring one touchdown on the ground. He also had one catch for five yards and one touchdown. Greg Dortch had 82 yards on seven catches (11.7 per reception) in that game.
[먹튀검증] 카지노커뮤니티 이용으로 먹튀검증 및 토토사이트 먹튀를 예방하세요.
Heya just wanted to give you a quick heads up and let you know a few of the images aren’t loading correctly. I’m not sure why but I think its a linking issue. I’ve tried it in two different internet browsers and both show the same results.
Nice blog here Also your site loads up very fast What host are you using Can I get your affiliate link to your host I wish my site loaded up as quickly as yours lol
Мы рекомендуем посетить веб-сайт https://novaplastica.ru/luchshie-sposoby-podderzhaniya-zdorovya-v-techenie-dnya/.
Кроме того, не забудьте добавить сайт в закладки: https://novaplastica.ru/luchshie-sposoby-podderzhaniya-zdorovya-v-techenie-dnya/
Мы рекомендуем посетить веб-сайт https://btc-fish.ru/kak-izbezhat-stressa-na-rabote/.
Кроме того, не забудьте добавить сайт в закладки: https://btc-fish.ru/kak-izbezhat-stressa-na-rabote/
How is the consistency of medication batches maintained during production vidalista dosage?
Мы рекомендуем посетить веб-сайт https://lodtrk.org.ua/kak-pravilno-vybrat-udochku-sekrety-uspeshnoy-rybalki/.
Кроме того, не забудьте добавить сайт в закладки: https://lodtrk.org.ua/kak-pravilno-vybrat-udochku-sekrety-uspeshnoy-rybalki/
I don’t usually read blog postings, but after reading this one, I had no choice but to try. Your writing style astounded me greatly. I appreciate your wonderful post.
Мы рекомендуем посетить веб-сайт https://kobovec.org.ua/interesnoe/issledovanie-produktivnye-tovary-dlya-rybakov-kotorye-uluchshat-vash-opyt/.
Кроме того, не забудьте добавить сайт в закладки: https://kobovec.org.ua/interesnoe/issledovanie-produktivnye-tovary-dlya-rybakov-kotorye-uluchshat-vash-opyt/
mtpolice.kr provides sports betting information, sports analysis, and sports tips as a sports community.
Its like you read my mind You appear to know a lot about this like you wrote the book in it or something I think that you could do with some pics to drive the message home a little bit but instead of that this is fantastic blog An excellent read I will certainly be back
Magnificent beat I would like to apprentice while you amend your site how can i subscribe for a blog web site The account helped me a acceptable deal I had been a little bit acquainted of this your broadcast offered bright clear idea
Francisk Skorina Gomel State University
This article was a fantastic read! I appreciate the depth of information and the clear, concise way it was presented. It’s evident that a lot of research and expertise went into crafting this post, and it really shines through in the quality of the content. I particularly found the first and last sections to be incredibly insightful. It sparked a few thoughts and questions I’d love to explore further. Could you elaborate more on next time? Also, if you have any recommended resources for further reading on this topic, I’d be grateful. Thanks for sharing your knowledge and contributing to a deeper understanding of this subject! I dedicated time to make a comment on this post immidiately after reading it, keep up the good work and i will be checking back again for more update. i appreciate the effort to write such a fantastic piece.
5 Arguments Porn Stars Is Actually A Beneficial
Thing Prettiest porn stars
Nice post. I learn something totally new and challenging on websites
I truly appreciate your technique of writing a blog. I added it to my bookmark site list and will
먹튀검증사이트: https://nktoday.kr/
먹튀검증사이트: https://nktoday.kr/
Your piece was tremendously insightful! The comprehensiveness of the material and the engaging presentation captivated me. The extent of research and expertise apparent throughout substantially elevates the content’s caliber. The revelations in the opening and closing sections were particularly compelling, igniting novel ideas and queries that I hope you’ll investigate in future works. If there are supplementary resources for further exploration on this subject, I’d be delighted to immerse myself in them. Thank you for sharing your knowledge and enriching our grasp of this topic. The exceptional quality of this work prompted me to comment right after reading. Maintain the fantastic efforts—I’ll definitely revisit for more updates. Your commitment to crafting such an excellent article is greatly appreciated!
Мы рекомендуем посетить веб-сайт https://kartina.info/.
Кроме того, не забудьте добавить сайт в закладки: https://kartina.info/
Мы рекомендуем посетить веб-сайт https://car2steal.ru/magazin-ribachok/.
Кроме того, не забудьте добавить сайт в закладки: https://car2steal.ru/magazin-ribachok/
Мы рекомендуем посетить веб-сайт ссылка.
Кроме того, не забудьте добавить сайт в закладки: ссылка
This piece was incredibly enlightening! The level of detail and clarity in the information provided was truly captivating. The extensive research and deep expertise evident in this article are truly impressive, greatly enhancing its overall quality. The insights offered at both the beginning and end were particularly striking, sparking numerous new ideas and questions for further exploration.The way complex topics were broken down into easily understandable segments was highly engaging. The logical flow of information kept me thoroughly engaged from start to finish, making it easy to immerse myself in the subject matter. Should there be any additional resources or further reading on this topic, I would love to explore them. The knowledge shared here has significantly broadened my understanding and ignited my curiosity for more. I felt compelled to express my appreciation immediately after reading due to the exceptional quality of this article. Your dedication to crafting such outstanding content is highly appreciated, and I eagerly await future updates. Please continue with your excellent work—I will definitely be returning for more insights. Thank you for your unwavering commitment to sharing your expertise and for greatly enriching our understanding of this subject.
Мы рекомендуем посетить веб-сайт https://ecoenergy.org.ua/news/rybolovnye-snasti-polnoe-rukovodstvo-dlya-rybakov-vseh-urovney.html.
Кроме того, не забудьте добавить сайт в закладки: https://ecoenergy.org.ua/news/rybolovnye-snasti-polnoe-rukovodstvo-dlya-rybakov-vseh-urovney.html
[먹튀검증] 불법 먹튀 사이트를 차단하고 안전한 온라인 도박 환경을 조성하세요! 먹튀 사이트 차단 방법, 검증된 사이트 목록, 안전놀이터 추천 등을 제공합니다.
Hey there! This post couldn’t be written any better! Reading this post reminds me of my good old room mate! He always kept talking about this. I will forward this article to him. Pretty sure he will have a good read. Thank you for sharing!
Мы рекомендуем посетить веб-сайт https://nastroenie.com.ua/masterstvo-v-uhode-za-karpom-ekspertnye-sovety-i-prakticheskie-podskazki/.
Кроме того, не забудьте добавить сайт в закладки: https://nastroenie.com.ua/masterstvo-v-uhode-za-karpom-ekspertnye-sovety-i-prakticheskie-podskazki/
Мы рекомендуем посетить веб-сайт https://replyua.net.ua/ru/effektivnye-aksessuary-dlya-hraneniya-ulova-i-zhivtsa/.
Кроме того, не забудьте добавить сайт в закладки: https://replyua.net.ua/ru/effektivnye-aksessuary-dlya-hraneniya-ulova-i-zhivtsa/
Мы рекомендуем посетить веб-сайт https://automir.in.ua/newsm.php?id=23145.
Кроме того, не забудьте добавить сайт в закладки: https://automir.in.ua/newsm.php?id=23145
Мы рекомендуем посетить веб-сайт https://avto.dzerghinsk.org/publ/poleznaja_informacija/zagadka_podvodnogo_mira_iskusstvo_prikarmlivanija_ryby/1-1-0-1271.
Кроме того, не забудьте добавить сайт в закладки: https://avto.dzerghinsk.org/publ/poleznaja_informacija/zagadka_podvodnogo_mira_iskusstvo_prikarmlivanija_ryby/1-1-0-1271
Мы рекомендуем посетить веб-сайт https://business.dp.ua/inform16/654.htm.
Кроме того, не забудьте добавить сайт в закладки: https://business.dp.ua/inform16/654.htm
Мы рекомендуем посетить веб-сайт https://dneprnews.com.ua/other/2024/05/24/295732.html.
Кроме того, не забудьте добавить сайт в закладки: https://dneprnews.com.ua/other/2024/05/24/295732.html
Мы рекомендуем посетить веб-сайт https://topnews.kiev.ua/other/2024/05/24/160818.html.
Кроме того, не забудьте добавить сайт в закладки: https://topnews.kiev.ua/other/2024/05/24/160818.html
Мы рекомендуем посетить веб-сайт https://uanews.kharkiv.ua/other/2024/05/24/457958.html.
Кроме того, не забудьте добавить сайт в закладки: https://uanews.kharkiv.ua/other/2024/05/24/457958.html
In a moneyline bet, if you choose to pick the -190 favorite, you would risk $190 to win $100. On the +170 dog, you would bet $100 for the chance to turn a $170 profit if the underdog wins. Success ultimately comes down to picking the winner of a game at the right line value and you can use our MLB odds calculator to help you figure out potential baseball odds profit before you get in the swing of things. Lastly, there is the total. The total is the number of runs combined by both teams in the game, and you bet on if there will be more or fewer runs than the listed total. Assume you want to bet on the Boston Red Sox against the New York Yankees. You will see Boston -150 on the money line meaning they are the favorite. You will also see Boston -1.5 with odds associated with that as well.
https://directoryreactor.com/listings12697458/what-is-pk-in-football-betting
Betting is completed at the coefficient from x18. Click the registration button from the application and you can mean exactly how you need to create a visibility. If the setting up is performed, you’ll see another Babu88 icon on your own device. The installation can begin, where you will want to offer particular permissions to your application to be effective safely. The business does not request the necessary verification. You are unable to place bets or play at the casino without a verified account. However, the creators advise following this procedure so that the security division can guarantee a high degree of security and fair gaming rules. This allows the creators to verify that you are older than 18 and have only one account. You can also check your contact details at Babu88. To pass it, you need to do the following:
Somebody essentially lend a hand to make significantly articles Id state That is the very first time I frequented your website page and up to now I surprised with the research you made to make this actual submit amazing Wonderful task
Мы рекомендуем посетить веб-сайт http://www.smakota.ho.ua/noma/luchshie-poplavki-dlya-rybalki-kak-pravilno-vybrat.html.
Кроме того, не забудьте добавить сайт в закладки: http://www.smakota.ho.ua/noma/luchshie-poplavki-dlya-rybalki-kak-pravilno-vybrat.html
Мы рекомендуем посетить веб-сайт https://kupimebel.info/instrumenty-dlya-rybalki-osnova-uspeshnogo-promysla/.
Кроме того, не забудьте добавить сайт в закладки: https://kupimebel.info/instrumenty-dlya-rybalki-osnova-uspeshnogo-promysla/
First off I want to say superb blog! I had a quick question in which I’d like to
ask if you do not mind. I was curious to find out how you center yourself and clear your mind before writing.
I’ve had a hard time clearing my mind in getting my thoughts out there.
I do take pleasure in writing but it just seems like the first
10 to 15 minutes are usually lost just trying to figure out how to
begin. Any recommendations or tips? Kudos!
Мы рекомендуем посетить веб-сайт https://city.zp.ua/articles/recreation/400-polotenca-dlja-rybalki-nezamenimyi-aksessuar-v-mire-uvlekatelnogo-otdyha.html.
Кроме того, не забудьте добавить сайт в закладки: https://city.zp.ua/articles/recreation/400-polotenca-dlja-rybalki-nezamenimyi-aksessuar-v-mire-uvlekatelnogo-otdyha.html
Мы рекомендуем посетить веб-сайт http://oweamuseum.odessa.ua/full/travel61/vybor-udilishcha-dlya-rybalki-iskusstvo-podbora-idealnogo-snaryazheniya.htm.
Кроме того, не забудьте добавить сайт в закладки: http://oweamuseum.odessa.ua/full/travel61/vybor-udilishcha-dlya-rybalki-iskusstvo-podbora-idealnogo-snaryazheniya.htm
Мы рекомендуем посетить веб-сайт http://history.odessa.ua/travel49/vse-chto-vy-dolzhny-znat-pered-pokupkoy-kotushki.htm.
Кроме того, не забудьте добавить сайт в закладки: http://history.odessa.ua/travel49/vse-chto-vy-dolzhny-znat-pered-pokupkoy-kotushki.htm
[카지노사이트] 불법 먹튀 사이트를 차단하고 안전한 온라인 도박 환경을 조성하세요! 먹튀 사이트 차단 방법, 검증된 사이트 목록, 안전놀이터 추천 등을 제공합니다.
Мы рекомендуем посетить веб-сайт https://sunsay.name/statti/rybolovnye-primanki-i-iskusstvo-ih-ispolzovaniya/.
Кроме того, не забудьте добавить сайт в закладки: https://sunsay.name/statti/rybolovnye-primanki-i-iskusstvo-ih-ispolzovaniya/
Мы рекомендуем посетить веб-сайт https://avtomaxi22.ru/.
Кроме того, не забудьте добавить сайт в закладки: https://avtomaxi22.ru/
Мы рекомендуем посетить веб-сайт https://med-like.ru/.
Кроме того, не забудьте добавить сайт в закладки: https://med-like.ru/
먹튀검증소: https://nktoday.kr/
Мы рекомендуем посетить веб-сайт https://metal82.ru/.
Кроме того, не забудьте добавить сайт в закладки: https://metal82.ru/
This is very interesting, You are a very skilled blogger. I have joined your feed and look forward to seeking more of your magnificent post. Also, I have shared your site in my social networks!
Мы рекомендуем посетить веб-сайт https://balkonnaya-dver.ru/.
Кроме того, не забудьте добавить сайт в закладки: https://balkonnaya-dver.ru/
[토토사이트] 불법 먹튀 사이트를 차단하고 안전한 온라인 도박 환경을 조성하세요! 먹튀 사이트 차단 방법, 검증된 사이트 목록, 안전놀이터 추천 등을 제공합니다.
Мы рекомендуем посетить веб-сайт https://drova-smolensk.ru/.
Кроме того, не забудьте добавить сайт в закладки: https://drova-smolensk.ru/
Мы рекомендуем посетить веб-сайт https://podveski-remont.ru/.
Кроме того, не забудьте добавить сайт в закладки: https://podveski-remont.ru/
Sweet site, super layout, real clean and use genial.
My site: Pinterest
Мы рекомендуем посетить веб-сайт https://admlihoslavl.ru/.
Кроме того, не забудьте добавить сайт в закладки: https://admlihoslavl.ru/
Мы рекомендуем посетить веб-сайт https://elegos.ru/.
Кроме того, не забудьте добавить сайт в закладки: https://elegos.ru/
Мы рекомендуем посетить веб-сайт https://ancientcivs.ru/.
Кроме того, не забудьте добавить сайт в закладки: https://ancientcivs.ru/
Somebody essentially lend a hand to make significantly posts I might state That is the very first time I frequented your web page and up to now I surprised with the research you made to create this particular put up amazing Excellent job
Мы рекомендуем посетить веб-сайт https://40-ka.ru/.
Кроме того, не забудьте добавить сайт в закладки: https://40-ka.ru/
Мы рекомендуем посетить веб-сайт https://100sm.ru/.
Кроме того, не забудьте добавить сайт в закладки: https://100sm.ru/
Мы рекомендуем посетить веб-сайт https://club-columb.ru/.
Кроме того, не забудьте добавить сайт в закладки: https://club-columb.ru/
Мы рекомендуем посетить веб-сайт https://daibob.ru/.
Кроме того, не забудьте добавить сайт в закладки: https://daibob.ru/
Thank you for sharing such an insightful and well-written article. I appreciate the thorough research and clear presentation of the topic. Your ability to break down complex concepts into easily understandable information is impressive and beneficial for readers. I look forward to reading more of your content and learning from your expertise. Keep up the great work!
Мы рекомендуем посетить веб-сайт https://gulliverauto.ru/.
Кроме того, не забудьте добавить сайт в закладки: https://gulliverauto.ru/
Мы рекомендуем посетить веб-сайт https://vektor-meh.ru/.
Кроме того, не забудьте добавить сайт в закладки: https://vektor-meh.ru/
Appreciating the dedication you put into your website and in depth information you present. It’s great to come across a blog every once in a while that isn’t the same outdated rehashed material. Fantastic read! I’ve saved your site and I’m including your RSS feeds to my Google account.
Can I use my insurance for medications related to reproductive fertility treatments Sildenafil online?
I have read some excellent stuff here Definitely value bookmarking for revisiting I wonder how much effort you put to make the sort of excellent informative website
helloI really like your writing so a lot share we keep up a correspondence extra approximately your post on AOL I need an expert in this house to unravel my problem May be that is you Taking a look ahead to see you
obviously like your web-site but you need to test the spelling on quite a few of your posts. Several of them are rife with spelling problems and I to find it very troublesome to inform the reality on the other hand I’ll certainly come back again.
Мы рекомендуем посетить веб-сайт
http://ec2-52-50-191-115.eu-west-1.compute.amazonaws.com/news/sebastian-errazuriz-vandalises-jeff-koons-snapchat-ar-balloon-dog-art-051017
Кроме того, не забудьте добавить сайт в закладки:
https://www.thevirtualreport.biz/news/64701/snapchat-and-jeff-koons-ar-sculpture-graffiti-bombed/
10 Situations When You’ll Need To Be Educated About Cutest
Pornstars photo
Мы рекомендуем посетить веб-сайт
https://solotutos.com/artista-destroza-snapchat-y-la-escultura-ar-de-jeff-koon/
Кроме того, не забудьте добавить сайт в закладки:
https://www.pazarlama30.com/kamusal-sanal-alan-ne-kadar-kamuya-ait/
I have been surfing online more than 3 hours today, yet I never found any interesting article like yours. It is pretty worth enough for me. In my opinion, if all web owners and bloggers made good content as you did, the web will be much more useful than ever before.
It’s actually very complex in this full of activity life to listen news on TV, so I only use world wide web for that purpose, and take the latest news.
If you are going for best contents like me, only go to see this site everyday since it provides quality contents, thanks
Is it safe to purchase medications from online pharmacies that claim to have a “secret ingredient” vidalista 40 reviews?
Your article is truly remarkable! The way you’ve explained the topic with such clarity and precision is highly commendable. Readers are sure to benefit immensely from the wealth of knowledge and practical insights you’ve shared. It’s clear that your understanding of the subject is deep and thorough. I’m eagerly looking forward to more of your exceptional work in the future. Thank you for imparting your expertise and illuminating us with such detailed and insightful content.
If you want to download the 1xBet India mobile app, use the instructions we offer below. We should note right away that you can download the client on your smartphone only on the official website of the bookmaker’s office. There is no application in the digital Google Play Store. Online bookmakers like 1xbet app download have encountered this problem. Fortunately, the solution did not take long. The company has decided (like all its competitors for that matter) to create the 1xBet application in two versions: one for Android and the other for iOS. Both apps have the same functionality, design, etc. So, the only difference between them is the operating system they work with. 1xBet Somalia has adapted to the war of the giants, if you will. The cash-out option is quite useful. This function has given punters on the 1xbet android software renewed hope because it allows them to make the most of their bet slips. When using the mobile app, the cash-out option tends to work more quickly. This is because you won’t have to worry about many problems as you would if you were betting on a website.
https://directoryholiday.com/listings12764807/1xbet-games
The best odds available for each team are outlined in green If you’re looking toward the future, these matchups are favorable for anyone looking to place a college basketball future wager on the National Championship. You can browse a specific team’s matchups to see their expected results and plan far in advance of the March Madness hype train — maybe this will be the year that 16th seed you always bet on sweeps the tournament, I’m sure of it! All wagers are refunded when the score lands exactly on the betting number. If a 3-point favorite wins by exactly three points, the original stake is returned to both sides of the bet. MLB DFS: Optimal FanDuel, DraftKings picks, player pool, fantasy lineup advice for May 16, 2024 Live betting continues to grow in popularity, as it gives people a chance to get involved from the opening tip until the final whistle. Knowing each team’s tendencies can create value in the live betting market. Sportsbooks usually offer updated odds in real time throughout the game.
Link exchange is nothing else but it is simply placing the other person’s website link on your page at proper place and other person will also do same in favor of you.
I was suggested this web site by my cousin Im not sure whether this post is written by him as no one else know such detailed about my trouble You are incredible Thanks
Ищите профессионального хакера? Тогда рекомендуем –
Взлом камеры видео наблюдения
Почта специалиста.
AnoniBaz@Yandex.ru
Your blog has become an indispensable resource for me. I’m always excited to see what new insights you have to offer. Thank you for consistently delivering top-notch content!
Your work has captivated me just as much as it has captivated you. The visual display is elegant, and the written content is impressive. Nevertheless, you seem concerned about the possibility of delivering something that may be viewed as dubious. I agree that you’ll be able to address this issue promptly.
gates of olympus
sweet bonanza
Howdy! I know this is kinda off topic however I’d figured I’d ask.
Would you be interested in exchanging links or maybe guest authoring a blog article or vice-versa?
My blog addresses a lot of the same subjects as yours and I think we could greatly benefit from each other.
If you happen to be interested feel free to shoot me an e-mail.
I look forward to hearing from you! Great blog by the way!
My spouse and I stumbled over here coming from a different web page and thought I might as well check things out. I like what I see so now i am following you. Look forward to looking over your web page for a second time.
https://vyzov-santehnika-na-dom.ru.
Discover FlashUpload.cloud: Your Ultimate Online Storage Solution
Advanced Monetization Options
Advanced Monetization Options
Have you ever considered about including a little bit more than just your articles? I mean, what you say is fundamental and all. However think of if you added some great photos or video clips to give your posts more, “pop”! Your content is excellent but with images and video clips, this website could certainly be one of the most beneficial in its niche. Awesome blog!
Great article and straight to the point. I don’t know if this is truly the best
place to ask but do you guys have any ideea where to get some professional writers?
Thank you 🙂 Escape room lista
Hi Neat post Theres an issue together with your web site in internet explorer may test this IE still is the marketplace chief and a good component of people will pass over your fantastic writing due to this problem
Франшиза автомойки позволяет предпринимателям использовать уже известный на рынке бренд и проверенную бизнес-модель для создания прибыльного дела с минимальными рисками.
Very interesting topic, thanks for posting..
I like this site very much, Its a rattling nice situation to read and get information..
안전을 위해 탑플레이어 머니상 공식 인증 업체를 이용하세요.
Heya i’m for the primary time here. I came across this board and I in finding It truly useful & it helped me out a lot. I hope to give something back and help others like you helped me.
Besides the usual live dealers and their generous bonuses, sweepstakes casinos are also gaining popularity. They have a unique way of operating with virtual currencies and special promotions. For players in places where regular online casinos aren’t allowed, sweepstakes casinos are a great alternative. Some influencers are playing with ‘fake’ money provided to them by their casino sponsor and may also be breaking British gambling laws by promoting and showing how to access these sites, which are illegal in this country. The consequences of new technologies in the online casino world are huge and wide. From virtual reality and augmented reality to artificial intelligence and blockchain technology, these innovations have revolutionized the player experience and opened up new doors for the industry. The development of mobile gaming, gesture control technology and wearable devices is still going on. Thus online casinos will become even more interactive, available and safe in the future.
https://www.panwarsproductions.com/forum/general-discussions/747-live-casino-news
If we need to summarize everything and make a conclusion, we can say that the Empire City Casino has a nice location not quite far from the city of New York. This makes it a convenient place for people willing to stay away from all crowded places in NY. Other casino plans include SL Green Caesars Roc Nation bid for Times Square, Bally’s at Ferry Point in The Bronx, Silverstein Properties in Hell’s Kitchen, and the Thor Equity consortium gaming facility complex along the Coney Island boardwalk. Jim Murren, chairman and CEO of MGM Resorts International, has described the purchase of Empire City Casino and Yonkers Raceway as a move to solidify the Las Vegas-based casino giant’s East Coast presence, joining the Borgata in Atlantic City and a $1 billion casino set to open this spring in Springfield, Mass. Murren, a lifelong Republican, endorsed Democratic candidate Hillary Clinton in the 2016 presidential race, citing how now-President Trump’s stances threatened to harm tourism and immigration key to the gaming industry.
In a world where sharing and managing digital files have become crucial, FlashUpload.cloud stands out as an indispensable online storage solution. Whether you are an occasional user or a professional looking for a reliable and efficient platform, FlashUpload.cloud has something to offer everyone. In this blog post, we will explore the benefits and unique features of FlashUpload.cloud, with a focus on its premium membership plans.
Its like you read my mind You appear to know so much about this like you wrote the book in it or something I think that you can do with a few pics to drive the message home a little bit but instead of that this is excellent blog A fantastic read Ill certainly be back
Excellent post on optimizing your YouTube channel! To get even more views and subscribers, visit Youtubeviews – a platform that offers comprehensive social media marketing services.
I admire the clarity and simplicity with which you present your ideas. Great post!
helloI like your writing very so much proportion we keep up a correspondence extra approximately your post on AOL I need an expert in this space to unravel my problem May be that is you Taking a look forward to see you
Wow superb blog layout How long have you been blogging for you make blogging look easy The overall look of your site is magnificent as well as the content
Somebody essentially lend a hand to make significantly posts I might state That is the very first time I frequented your web page and up to now I surprised with the research you made to create this particular put up amazing Excellent job
helloI like your writing very so much proportion we keep up a correspondence extra approximately your post on AOL I need an expert in this space to unravel my problem May be that is you Taking a look forward to see you
Parabéns pelo blog! Venha conhecer mais sobre [Startups](https://www.inovasimples.com.br/search/label/Startup) no Sempre Inova Simples.
O seu blog sempre traz informações valiosas e atuais para todos os leitores. A postagem recente foi especialmente relevante e esclarecedora. Aproveitando a oportunidade, gostaria de recomendar a todos a leitura sobre análise de dados. Muito obrigado por compartilhar conteúdos tão ricos!
빠르고 안전한 먹튀검증으로 먹튀 피해를 예방하세요. 먹튀검증 전문 커뮤니티 먹튀감정사에서 먹튀 없는 안전놀이터 정보를 제공합니다.
O blog é uma excelente fonte de informação e a última publicação foi excepcional. Aproveito a oportunidade para sugerir a leitura sobre hospedagem de aplicativos. Agradeço por compartilhar conteúdos tão ricos e por esta oportunidade.
Temp Mail Good post! We will be linking to this particularly great post on our site. Keep up the great writing
Thanks I have recently been looking for info about this subject for a while and yours is the greatest I have discovered so far However what in regards to the bottom line Are you certain in regards to the supply
탑플레이어 머니상: https://www.youtube.com/watch?v=XJwhpzKSfM4
I am continually looking online for posts that can benefit me.
Thank you!
Feel free to visit my web blog Pinterest
Its like you read my mind You appear to know a lot about this like you wrote the book in it or something I think that you could do with some pics to drive the message home a little bit but instead of that this is fantastic blog An excellent read I will certainly be back